
All Posts
Heteroscedastic Bayesian Robust Regression
- 30 April 2026
The PyMC gallery has two robust regression notebooks: one with a Student-t likelihood (pymc-examples:GLM-robust) and one with the Hogg (2010) signal-vs-noise mixture (pymc-examples:GLM-robust-with-outlier-detection). Both protect against vertical outliers (points with unusual response values), but neither defends against leverage points: observations far from the bulk of the predictor space, which can drag the regression line even under a heavy-tailed likelihood.
Estimating species distributions with occupancy models
- 06 January 2026
Estimating where species live is one of the most common tasks in ecology. Recreational birders know that every field guide includes a range map showing where a species can be found, as well as habitat information to help locate the animals. For example, a field guide for Swiss birds might tell you that Red Crossbills (Loxia curvirostra) are most likely found in forests at intermediate elevations. Both of these tasks–mapping ranges and estimating habitat relationships–fall under the umbrella of species distribution modeling.
Modeling spatial point patterns with a marked log-Gaussian Cox process
- 31 December 2025
The log-Gaussian Cox process (LGCP) is a probabilistic model of point patterns typically observed in space or time. It has two main components. First, an underlying intensity field \(\lambda(s)\) of positive real values is modeled over the entire domain \(X\) using an exponentially-transformed Gaussian process which constrains \(\lambda\) to be positive. Then, this intensity field is used to parameterize a Poisson point process which represents a stochastic mechanism for placing points in space. Some phenomena amenable to this representation include the incidence of cancer cases across a county, or the spatiotemporal locations of crime events in a city. Both spatial and temporal dimensions can be handled equivalently within this framework, though this tutorial only addresses data in two spatial dimensions.
Bayesian Workflow with SEMs
- 06 September 2025
This case study extends the themes of contemporary Bayesian workflow and Structural Equation Modelling. While both topics are well represented in the PyMC examples library, our goal here is to show how the principles of the Bayesian workflow can be applied concretely to structural equation models (SEMs). The iterative and expansionary strategies of model development for SEMs provide an independent motivation for the recommendations of [Gelman et al., 2020] stemming from the SEM literature broadly. But [Kline, 2023] in particular highlights the utility of a staggered approach to model development as a diagnostic for model mis-specification.
The Bayesian Workflow: COVID-19 Outbreak Modeling
- 16 June 2025
Bayesian modeling is a robust approach for drawing conclusions from data. Successful modeling involves an interplay among statistical models, subject matter knowledge, and computational techniques. In building Bayesian models, it is easy to get carried away with complex models from the outset, often leading to an unsatisfactory final result (or a dead end). To avoid common model development pitfalls, a structured approach is helpful. The Bayesian workflow (Gelman et al.) is a systematic approach to building, validating, and refining probabilistic models, ensuring that the models are robust, interpretable, and useful for decision-making. The workflow’s iterative nature ensures that modeling assumptions are tested and refined as the model grows, leading to more reliable results.
Forecasting Hurricane Trajectories with State Space Models
- 15 June 2025
Duplicate implicit target name: “forecasting hurricane trajectories with state space models”.
Time Series Models Derived From a Generative Graph
- 06 January 2025
In this notebook, we show how to model and fit a time series model starting from a generative graph. In particular, we explain how to use scan to loop efficiently inside a PyMC model.
Bayesian Hypothesis Testing - an introduction
- 06 December 2024
Bayesian hypothesis testing provides a flexible and intuitive way to assess whether parameters differ from specified values. Unlike classical methods focusing on p-values, Bayesian methods let us directly compute probabilities of hypotheses and quantify the strength of evidence in various ways.
GLM-missing-values-in-covariates
- 09 November 2024
Minimal Reproducible Example: Workflow to handle missing data in multiple covariates (numeric predictor features)
GLM-ordinal-features
- 27 October 2024
Here we use an ordinal exogenous predictor feature within a model:
Simpson’s paradox
- 06 September 2024
Simpson’s Paradox describes a situation where there might be a negative relationship between two variables within a group, but when data from multiple groups are combined, that relationship may disappear or even reverse sign. The gif below (from the Simpson’s Paradox Wikipedia page) demonstrates this very nicely.
Confirmatory Factor Analysis and Structural Equation Models in Psychometrics
- 06 September 2024
“Evidently, the notions of relevance and dependence are far more basic to human reasoning than the numerical values attached to probability judgments…the language used for representing probabilistic information should allow assertions about dependency relationships to be expressed qualitatively, directly, and explicitly” - Pearl in Probabilistic Reasoning in Intelligent Systems
The prevalence of malaria in the Gambia
- 24 August 2024
Duplicate implicit target name: “the prevalence of malaria in the gambia”.
Model Averaging
- 06 August 2024
When confronted with more than one model we have several options. One of them is to perform model selection as exemplified by the PyMC examples Model comparison and the GLM: Model Selection, usually is a good idea to also include posterior predictive checks in order to decide which model to keep. Discarding all models except one is equivalent to affirm that, among the evaluated models, one is correct (under some criteria) with probability 1 and the rest are incorrect. In most cases this will be an overstatement that ignores the uncertainty we have in our models. This is somewhat similar to computing the full posterior and then just keeping a point-estimate like the posterior mean; we may become overconfident of what we really know. You can also browse the blog/tag/model-comparison tag to find related posts.
Gaussian Processes: HSGP Advanced Usage
- 28 June 2024
The Hilbert Space Gaussian processes approximation is a low-rank GP approximation that is particularly well-suited to usage in probabilistic programming languages like PyMC. It approximates the GP using a pre-computed and fixed set of basis functions that don’t depend on the form of the covariance kernel or its hyperparameters. It’s a parametric approximation, so prediction in PyMC can be done as one would with a linear model via pm.Data or pm.set_data. You don’t need to define the .conditional distribution that non-parameteric GPs rely on. This makes it much easier to integrate an HSGP, instead of a GP, into your existing PyMC model. Additionally, unlike many other GP approximations, HSGPs can be used anywhere within a model and with any likelihood function.
Gaussian Processes: HSGP Reference & First Steps
- 10 June 2024
The Hilbert Space Gaussian processes approximation is a low-rank GP approximation that is particularly well-suited to usage in probabilistic programming languages like PyMC. It approximates the GP using a pre-computed and fixed set of basis functions that don’t depend on the form of the covariance kernel or its hyperparameters. It’s a parametric approximation, so prediction in PyMC can be done as one would with a linear model via pm.Data or pm.set_data. You don’t need to define the .conditional distribution that non-parameteric GPs rely on. This makes it much easier to integrate an HSGP, instead of a GP, into your existing PyMC model. Additionally, unlike many other GP approximations, HSGPs can be used anywhere within a model and with any likelihood function.
Categorical regression
- 06 May 2024
In this example, we will model outcomes with more than two categories.
Automatic marginalization of discrete variables
- 20 January 2024
PyMC is very amendable to sampling models with discrete latent variables. But if you insist on using the NUTS sampler exclusively, you will need to get rid of your discrete variables somehow. The best way to do this is by marginalizing them out, as then you benefit from Rao-Blackwell’s theorem and get a lower variance estimate of your parameters.
Categories and Curves
- 14 January 2024
This notebook is part of the PyMC port of the Statistical Rethinking 2023 lecture series by Richard McElreath.
The Garden of Forking Data
- 07 January 2024
This notebook is part of the PyMC port of the Statistical Rethinking 2023 lecture series by Richard McElreath.
Social Networks
- 07 January 2024
This notebook is part of the PyMC port of the Statistical Rethinking 2023 lecture series by Richard McElreath.
Ordered Categories
- 07 January 2024
This notebook is part of the PyMC port of the Statistical Rethinking 2023 lecture series by Richard McElreath.
Multilevel Models
- 07 January 2024
This notebook is part of the PyMC port of the Statistical Rethinking 2023 lecture series by Richard McElreath.
Multilevel Adventures
- 07 January 2024
This notebook is part of the PyMC port of the Statistical Rethinking 2023 lecture series by Richard McElreath.
Modeling Events
- 07 January 2024
This notebook is part of the PyMC port of the Statistical Rethinking 2023 lecture series by Richard McElreath.
Missing Data
- 07 January 2024
This notebook is part of the PyMC port of the Statistical Rethinking 2023 lecture series by Richard McElreath.
Measurement and Misclassification
- 07 January 2024
This notebook is part of the PyMC port of the Statistical Rethinking 2023 lecture series by Richard McElreath.
Markov Chain Monte Carlo
- 07 January 2024
This notebook is part of the PyMC port of the Statistical Rethinking 2023 lecture series by Richard McElreath.
Horoscopes
- 07 January 2024
This notebook is part of the PyMC port of the Statistical Rethinking 2023 lecture series by Richard McElreath.
Good & Bad Controls
- 07 January 2024
This notebook is part of the PyMC port of the Statistical Rethinking 2023 lecture series by Richard McElreath.
Geocentric Models
- 07 January 2024
This notebook is part of the PyMC port of the Statistical Rethinking 2023 lecture series by Richard McElreath.
Generalized Linear Madness
- 07 January 2024
This notebook is part of the PyMC port of the Statistical Rethinking 2023 lecture series by Richard McElreath.
Gaussian Processes
- 07 January 2024
This notebook is part of the PyMC port of the Statistical Rethinking 2023 lecture series by Richard McElreath.
Fitting Over & Under
- 07 January 2024
This notebook is part of the PyMC port of the Statistical Rethinking 2023 lecture series by Richard McElreath.
Elemental Confounds
- 07 January 2024
This notebook is part of the PyMC port of the Statistical Rethinking 2023 lecture series by Richard McElreath.
Counts and Hidden Confounds
- 07 January 2024
This notebook is part of the PyMC port of the Statistical Rethinking 2023 lecture series by Richard McElreath.
Correlated Features
- 07 January 2024
This notebook is part of the PyMC port of the Statistical Rethinking 2023 lecture series by Richard McElreath.
Bayesian Non-parametric Causal Inference
- 06 January 2024
There are few claims stronger than the assertion of a causal relationship and few claims more contestable. A naive world model - rich with tenuous connections and non-sequiter implications is characteristic of conspiracy theory and idiocy. On the other hand, a refined and detailed knowledge of cause and effect characterised by clear expectations, plausible connections and compelling counterfactuals, will steer you well through the buzzing, blooming confusion of the world.
Baby Births Modelling with HSGPs
- 06 January 2024
This notebook provides an example of using the Hilbert Space Gaussian Process (HSGP) technique, introduced in [], in the context of time series modeling. This technique has proven successful in speeding up models with Gaussian process components.
Out-Of-Sample Predictions
- 06 December 2023
We want to fit a logistic regression model where there is a multiplicative interaction between two numerical features.
Bayesian copula estimation: Describing correlated joint distributions
- 06 December 2023
When we deal with multiple variables (e.g. \(a\) and \(b\)) we often want to describe the joint distribution \(P(a, b)\) parametrically. If we are lucky, then this joint distribution might be ‘simple’ in some way. For example, it could be that \(a\) and \(b\) are statistically independent, in which case we can break down the joint distribution into \(P(a, b) = P(a) P(b)\) and so we just need to find appropriate parametric descriptions for \(P(a)\) and \(P(b)\). Even if this is not appropriate, it may be that \(P(a, b)\) could be described well by a simple multivariate distribution, such as a multivariate normal distribution for example.
Frailty and Survival Regression Models
- 06 November 2023
This notebook uses libraries that are not PyMC dependencies and therefore need to be installed specifically to run this notebook. Open the dropdown below for extra guidance.
GLM: Negative Binomial Regression
- 06 September 2023
This notebook uses libraries that are not PyMC dependencies and therefore need to be installed specifically to run this notebook. Open the dropdown below for extra guidance.
The Besag-York-Mollie Model for Spatial Data
- 18 August 2023
This notebook uses libraries that are not PyMC dependencies and therefore need to be installed specifically to run this notebook. Open the dropdown below for extra guidance.
Interventional what-if analysis using the PyMC do-operator
- 06 August 2023
In the realm of data science and analytics, understanding the causal relationships between variables is paramount. While traditional statistical methods have provided insights into these relationships, the advent of probabilistic programming has ushered in a new era of causal analysis. In this article, we will explore the power of interventional what-if analysis using the PyMC framework, with a special focus on the do-operator.
Faster Sampling with JAX and Numba
- 11 July 2023
PyMC can compile its models to various execution backends through PyTensor, including:
Interventional distributions and graph mutation with the do-operator
- 06 July 2023
PyMC is a pivotal component of the open source Bayesian statistics ecosystem. It helps solve real problems across a wide range of industries and academic research areas every day. And it has gained this level of utility by being accessible, powerful, and practically useful at solving Bayesian statistical inference problems.
Gaussian Processes: Latent Variable Implementation
- 06 June 2023
The gp.Latent class is a direct implementation of a Gaussian process without approximation. Given a mean and covariance function, we can place a prior on the function \(f(x)\),
Discrete Choice and Random Utility Models
- 06 June 2023
This notebook uses libraries that are not PyMC dependencies and therefore need to be installed specifically to run this notebook. Open the dropdown below for extra guidance.
Marginal Likelihood Implementation
- 04 June 2023
The gp.Marginal class implements the more common case of GP regression: the observed data are the sum of a GP and Gaussian noise. gp.Marginal has a marginal_likelihood method, a conditional method, and a predict method. Given a mean and covariance function, the function \(f(x)\) is modeled as,
Regression Models with Ordered Categorical Outcomes
- 06 April 2023
Like many areas of statistics the language of survey data comes with an overloaded vocabulary. When discussing survey design you will often hear about the contrast between design based and model based approaches to (i) sampling strategies and (ii) statistical inference on the associated data. We won’t wade into the details about different sample strategies such as: simple random sampling, cluster random sampling or stratified random sampling using population weighting schemes. The literature on each of these is vast, but in this notebook we’ll talk about when any why it’s useful to apply model driven statistical inference to Likert scaled survey response data and other kinds of ordered categorical data.
Longitudinal Models of Change
- 06 April 2023
The study of change involves simultaneously analysing the individual trajectories of change and abstracting over the set of individuals studied to extract broader insight about the nature of the change in question. As such it’s easy to lose sight of the forest for the focus on the trees. In this example we’ll demonstrate some of the subtleties of using hierarchical bayesian models to study the change within a population of individuals - moving from the within individual view to the between/cross individuals perspective.
Using ModelBuilder class for deploying PyMC models
- 22 February 2023
Many users face difficulty in deploying their PyMC models to production because deploying/saving/loading a user-created model is not well standardized. One of the reasons behind this is there is no direct way to save or load a model in PyMC like scikit-learn or TensorFlow. The new ModelBuilder class is aimed to improve this workflow by providing a scikit-learn inspired API to wrap your PyMC models.
Bayesian Missing Data Imputation
- 06 February 2023
Duplicate implicit target name: “bayesian missing data imputation”.
Pathfinder Variational Inference
- 05 February 2023
Pathfinder [] is a variational inference algorithm that produces samples from the posterior of a Bayesian model. It compares favorably to the widely used ADVI algorithm. On large problems, it should scale better than most MCMC algorithms, including dynamic HMC (i.e. NUTS), at the cost of a more biased estimate of the posterior. For details on the algorithm, see the arxiv preprint.
Multivariate Gaussian Random Walk
- 02 February 2023
This notebook shows how to fit a correlated time series using multivariate Gaussian random walks (GRWs). In particular, we perform a Bayesian regression of the time series data against a model dependent on GRWs.
Rolling Regression
- 28 January 2023
Pairs trading is a famous technique in algorithmic trading that plays two stocks against each other.
Hierarchical Partial Pooling
- 28 January 2023
Suppose you are tasked with estimating baseball batting skills for several players. One such performance metric is batting average. Since players play a different number of games and bat in different positions in the order, each player has a different number of at-bats. However, you want to estimate the skill of all players, including those with a relatively small number of batting opportunities.
Quantile Regression with BART
- 25 January 2023
Usually when doing regression we model the conditional mean of some distribution. Common cases are a Normal distribution for continuous unbounded responses, a Poisson distribution for count data, etc.
DEMetropolis(Z) Sampler Tuning
- 18 January 2023
For continuous variables, the default PyMC sampler (NUTS) requires that gradients are computed, which PyMC does through autodifferentiation. However, in some cases, a PyMC model may not be supplied with gradients (for example, by evaluating a numerical model outside of PyMC) and an alternative sampler is necessary. The DEMetropolisZ sampler is an efficient choice for gradient-free inference. The implementation of DEMetropolisZ in PyMC is based on but with a modified tuning scheme. This notebook compares various tuning parameter settings for the sampler, including the drop_tune_fraction parameter which was introduced in PyMC.
DEMetropolis and DEMetropolis(Z) Algorithm Comparisons
- 18 January 2023
For continuous variables, the default PyMC sampler (NUTS) requires that gradients are computed, which PyMC does through autodifferentiation. However, in some cases, a PyMC model may not be supplied with gradients (for example, by evaluating a numerical model outside of PyMC) and an alternative sampler is necessary. Differential evolution (DE) Metropolis samplers are an efficient choice for gradient-free inference. This notebook compares the DEMetropolis and the DEMetropolisZ samplers in PyMC to help determine which is a better option for a given problem.
Reparameterizing the Weibull Accelerated Failure Time Model
- 17 January 2023
This notebook uses libraries that are not PyMC dependencies and therefore need to be installed specifically to run this notebook. Open the dropdown below for extra guidance.
Bayesian Survival Analysis
- 17 January 2023
Survival analysis studies the distribution of the time to an event. Its applications span many fields across medicine, biology, engineering, and social science. This tutorial shows how to fit and analyze a Bayesian survival model in Python using PyMC.
ODE Lotka-Volterra With Bayesian Inference in Multiple Ways
- 16 January 2023
The purpose of this notebook is to demonstrate how to perform Bayesian inference on a system of ordinary differential equations (ODEs), both with and without gradients. The accuracy and efficiency of different samplers are compared.
Introduction to Variational Inference with PyMC
- 13 January 2023
The most common strategy for computing posterior quantities of Bayesian models is via sampling, particularly Markov chain Monte Carlo (MCMC) algorithms. While sampling algorithms and associated computing have continually improved in performance and efficiency, MCMC methods still scale poorly with data size, and become prohibitive for more than a few thousand observations. A more scalable alternative to sampling is variational inference (VI), which re-frames the problem of computing the posterior distribution as an optimization problem.
Empirical Approximation overview
- 13 January 2023
For most models we use sampling MCMC algorithms like Metropolis or NUTS. In PyMC we got used to store traces of MCMC samples and then do analysis using them. There is a similar concept for the variational inference submodule in PyMC: Empirical. This type of approximation stores particles for the SVGD sampler. There is no difference between independent SVGD particles and MCMC samples. Empirical acts as a bridge between MCMC sampling output and full-fledged VI utils like apply_replacements or sample_node. For the interface description, see variational_api_quickstart. Here we will just focus on Emprical and give an overview of specific things for the Empirical approximation.
Hierarchical Binomial Model: Rat Tumor Example
- 10 January 2023
This short tutorial demonstrates how to use PyMC to do inference for the rat tumour example found in chapter 5 of Bayesian Data Analysis 3rd Edition [Gelman et al., 2013]. Readers should already be familiar with the PyMC API.
GLM: Robust Linear Regression
- 10 January 2023
Duplicate implicit target name: “glm: robust linear regression”.
Bayes Factors and Marginal Likelihood
- 10 January 2023
The “Bayesian way” to compare models is to compute the marginal likelihood of each model \(p(y \mid M_k)\), i.e. the probability of the observed data \(y\) given the \(M_k\) model. This quantity, the marginal likelihood, is just the normalizing constant of Bayes’ theorem. We can see this if we write Bayes’ theorem and make explicit the fact that all inferences are model-dependant.
Analysis of An AR(1) Model in PyMC
- 07 January 2023
Consider the following AR(2) process, initialized in the infinite past:
Reliability Statistics and Predictive Calibration
- 06 January 2023
Duplicate implicit target name: “reliability statistics and predictive calibration”.
Modeling Heteroscedasticity with BART
- 06 January 2023
In this notebook we show how to use BART to model heteroscedasticity as described in Section 4.1 of pymc-bart’s paper []. We use the marketing data set provided by the R package datarium [Kassambara, 2019]. The idea is to model a marketing channel contribution to sales as a function of budget.
GLM: Poisson Regression
- 30 November 2022
This is a minimal reproducible example of Poisson regression to predict counts using dummy data.
Bayesian Vector Autoregressive Models
- 06 November 2022
Duplicate implicit target name: “bayesian vector autoregressive models”.
A Primer on Bayesian Methods for Multilevel Modeling
- 24 October 2022
Hierarchical or multilevel modeling is a generalization of regression modeling.
Forecasting with Structural AR Timeseries
- 20 October 2022
Bayesian structural timeseries models are an interesting way to learn about the structure inherent in any observed timeseries data. It also gives us the ability to project forward the implied predictive distribution granting us another view on forecasting problems. We can treat the learned characteristics of the timeseries data observed to-date as informative about the structure of the unrealised future state of the same measure.
Multi-output Gaussian Processes: Coregionalization models using Hamadard product
- 06 October 2022
This notebook shows how to implement the Intrinsic Coregionalization Model (ICM) and the Linear Coregionalization Model (LCM) using a Hamadard product between the Coregion kernel and input kernels. Multi-output Gaussian Process is discussed in this paper by Bonilla et al. [2007]. For further information about ICM and LCM, please check out the talk on Multi-output Gaussian Processes by Mauricio Alvarez, and his slides with more references at the last page.
Kronecker Structured Covariances
- 06 October 2022
PyMC contains implementations for models that have Kronecker structured covariances. This patterned structure enables Gaussian process models to work on much larger datasets. Kronecker structure can be exploited when
Interrupted time series analysis
- 06 October 2022
This notebook focuses on how to conduct a simple Bayesian interrupted time series analysis. This is useful in quasi-experimental settings where an intervention was applied to all treatment units.
Generalized Extreme Value Distribution
- 27 September 2022
The Generalized Extreme Value (GEV) distribution is a meta-distribution containing the Weibull, Gumbel, and Frechet families of extreme value distributions. It is used for modelling the distribution of extremes (maxima or minima) of stationary processes, such as the annual maximum wind speed, annual maximum truck weight on a bridge, and so on, without needing a priori decision on the tail behaviour.
Difference in differences
- 06 September 2022
This notebook provides a brief overview of the difference in differences approach to causal inference, and shows a working example of how to conduct this type of analysis under the Bayesian framework, using PyMC. While the notebooks provides a high level overview of the approach, I recommend consulting two excellent textbooks on causal inference. Both The Effect [Huntington-Klein, 2021] and Causal Inference: The Mixtape [Cunningham, 2021] have chapters devoted to difference in differences.
Bayesian regression with truncated or censored data
- 06 September 2022
The notebook provides an example of how to conduct linear regression when your outcome variable is either censored or truncated.
Fitting a Reinforcement Learning Model to Behavioral Data with PyMC
- 05 August 2022
Reinforcement Learning models are commonly used in behavioral research to model how animals and humans learn, in situtions where they get to make repeated choices that are followed by some form of feedback, such as a reward or a punishment.
How to debug a model
- 02 August 2022
There are various levels on which to debug a model. One of the simplest is to just print out the values that different variables are taking on.
Gaussian Processes using numpy kernel
- 31 July 2022
Example of simple Gaussian Process fit, adapted from Stan’s example-models repository.
Conditional Autoregressive (CAR) Models for Spatial Data
- 29 July 2022
This notebook uses libraries that are not PyMC dependencies and therefore need to be installed specifically to run this notebook. Open the dropdown below for extra guidance.
Counterfactual inference: calculating excess deaths due to COVID-19
- 06 July 2022
Causal reasoning and counterfactual thinking are really interesting but complex topics! Nevertheless, we can make headway into understanding the ideas through relatively simple examples. This notebook focuses on the concepts and the practical implementation of Bayesian causal reasoning using PyMC.
Stochastic Volatility model
- 17 June 2022
Asset prices have time-varying volatility (variance of day over day returns). In some periods, returns are highly variable, while in others very stable. Stochastic volatility models model this with a latent volatility variable, modeled as a stochastic process. The following model is similar to the one described in the No-U-Turn Sampler paper, [Hoffman and Gelman, 2014].
Splines
- 04 June 2022
Often, the model we want to fit is not a perfect line between some \(x\) and \(y\). Instead, the parameters of the model are expected to vary over \(x\). There are multiple ways to handle this situation, one of which is to fit a spline. Spline fit is effectively a sum of multiple individual curves (piecewise polynomials), each fit to a different section of \(x\), that are tied together at their boundaries, often called knots.
Probabilistic Matrix Factorization for Making Personalized Recommendations
- 03 June 2022
So you are browsing for something to watch on Netflix and just not liking the suggestions. You just know you can do better. All you need to do is collect some ratings data from yourself and friends and build a recommendation algorithm. This notebook will guide you in doing just that!
Sampler Statistics
- 31 May 2022
When checking for convergence or when debugging a badly behaving sampler, it is often helpful to take a closer look at what the sampler is doing. For this purpose some samplers export statistics for each generated sample.
General API quickstart
- 31 May 2022
Models in PyMC are centered around the Model class. It has references to all random variables (RVs) and computes the model logp and its gradients. Usually, you would instantiate it as part of a with context:
Approximate Bayesian Computation
- 31 May 2022
Approximate Bayesian Computation methods (also called likelihood free inference methods), are a group of techniques developed for inferring posterior distributions in cases where the likelihood function is intractable or costly to evaluate. This does not mean that the likelihood function is not part of the analysis, it just the we are approximating the likelihood, and hence the name of the ABC methods.
Variational Inference: Bayesian Neural Networks
- 30 May 2022
Probabilistic Programming, Deep Learning and “Big Data” are among the biggest topics in machine learning. Inside of PP, a lot of innovation is focused on making things scale using Variational Inference. In this example, I will show how to use Variational Inference in PyMC to fit a simple Bayesian Neural Network. I will also discuss how bridging Probabilistic Programming and Deep Learning can open up very interesting avenues to explore in future research.
Censored Data Models
- 06 May 2022
This example notebook on Bayesian survival analysis touches on the point of censored data. Censoring is a form of missing-data problem, in which observations greater than a certain threshold are clipped down to that threshold, or observations less than a certain threshold are clipped up to that threshold, or both. These are called right, left and interval censoring,respectively. In this example notebook we consider interval censoring.
NBA Foul Analysis with Item Response Theory
- 17 April 2022
This tutorial shows an application of Bayesian Item Response Theory [Fox, 2010] to NBA basketball foul calls data using PyMC. Based on Austin Rochford’s blogpost NBA Foul Calls and Bayesian Item Response Theory.
Regression discontinuity design analysis
- 06 April 2022
Quasi experiments involve experimental interventions and quantitative measures. However, quasi-experiments do not involve random assignment of units (e.g. cells, people, companies, schools, states) to test or control groups. This inability to conduct random assignment poses problems when making causal claims as it makes it harder to argue that any difference between a control and test group are because of an intervention and not because of a confounding factor.
Gaussian Process for CO2 at Mauna Loa
- 06 April 2022
This Gaussian Process (GP) example shows how to:
Gaussian Mixture Model
- 06 April 2022
A mixture model allows us to make inferences about the component contributors to a distribution of data. More specifically, a Gaussian Mixture Model allows us to make inferences about the means and standard deviations of a specified number of underlying component Gaussian distributions.
Air passengers - Prophet-like model
- 06 April 2022
We’re going to look at the “air passengers” dataset, which tracks the monthly totals of a US airline passengers from 1949 to 1960. We could fit this using the Prophet model [] (indeed, this dataset is one of the examples they provide in their documentation), but instead we’ll make our own Prophet-like model in PyMC3. This will make it a lot easier to inspect the model’s components and to do prior predictive checks (an integral component of the Bayesian workflow [Gelman et al., 2020]).
Model building and expansion for golf putting
- 02 April 2022
This uses and closely follows the case study from Andrew Gelman, written in Stan. There are some new visualizations and we steered away from using improper priors, but much credit to him and to the Stan group for the wonderful case study and software.
How to wrap a JAX function for use in PyMC
- 24 March 2022
This notebook uses libraries that are not PyMC dependencies and therefore need to be installed specifically to run this notebook. Open the dropdown below for extra guidance.
Mean and Covariance Functions
- 22 March 2022
A large set of mean and covariance functions are available in PyMC. It is relatively easy to define custom mean and covariance functions. Since PyMC uses PyTensor, their gradients do not need to be defined by the user.
Factor analysis
- 19 March 2022
Factor analysis is a widely used probabilistic model for identifying low-rank structure in multivariate data as encoded in latent variables. It is very closely related to principal components analysis, and differs only in the prior distributions assumed for these latent variables. It is also a good example of a linear Gaussian model as it can be described entirely as a linear transformation of underlying Gaussian variates. For a high-level view of how factor analysis relates to other models, you can check out this diagram originally published by Ghahramani and Roweis.
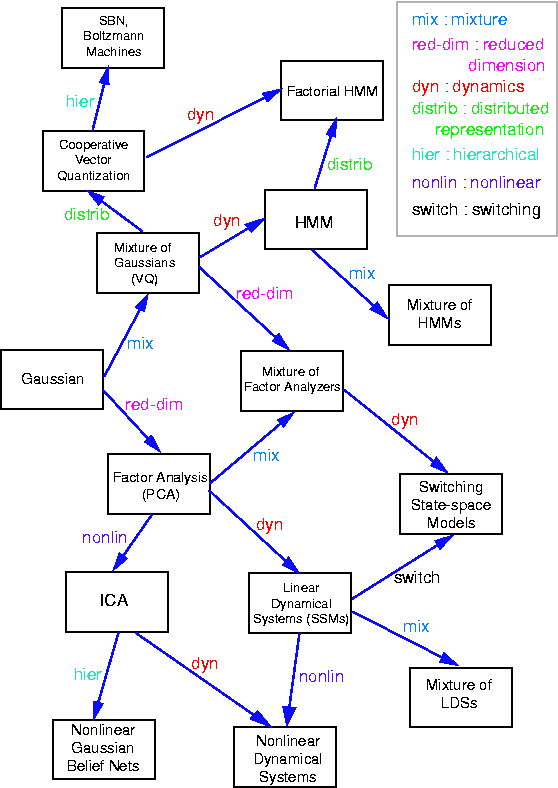{kind=link}
A Hierarchical model for Rugby prediction
- 19 March 2022
In this example, we’re going to reproduce the first model described in Baio and Blangiardo [2010] using PyMC. Then show how to sample from the posterior predictive to simulate championship outcomes from the scored goals which are the modeled quantities.
Bayesian moderation analysis
- 06 March 2022
This notebook covers Bayesian moderation analysis. This is appropriate when we believe that one predictor variable (the moderator) may influence the linear relationship between another predictor variable and an outcome. Here we look at an example where we look at the relationship between hours of training and muscle mass, where it may be that age (the moderating variable) affects this relationship.
Lasso regression with block updating
- 10 February 2022
Sometimes, it is very useful to update a set of parameters together. For example, variables that are highly correlated are often good to update together. In PyMC block updating is simple. This will be demonstrated using the parameter step of pymc.sample.
Binomial regression
- 06 February 2022
This notebook covers the logic behind Binomial regression, a specific instance of Generalized Linear Modelling. The example is kept very simple, with a single predictor variable.
Bayesian mediation analysis
- 06 February 2022
This notebook covers Bayesian mediation analysis. This is useful when we want to explore possible mediating pathways between a predictor and an outcome variable.
GLM: Model Selection
- 08 January 2022
A fairly minimal reproducible example of Model Selection using WAIC, and LOO as currently implemented in PyMC.
Dirichlet mixtures of multinomials
- 08 January 2022
This example notebook demonstrates the use of a Dirichlet mixture of multinomials (a.k.a Dirichlet-multinomial or DM) to model categorical count data. Models like this one are important in a variety of areas, including natural language processing, ecology, bioinformatics, and more.
Bayesian Estimation Supersedes the T-Test
- 07 January 2022
Non-consecutive header level increase; H1 to H3 [myst.header]
Bayesian Additive Regression Trees: Introduction
- 21 December 2021
Bayesian additive regression trees (BART) is a non-parametric regression approach. If we have some covariates \(X\) and we want to use them to model \(Y\), a BART model (omitting the priors) can be represented as:
Using a “black box” likelihood function
- 16 December 2021
There is a related example that discusses how to use a likelihood implemented in JAX
Using Data Containers
- 16 December 2021
After building the statistical model of your dreams, you’re going to need to feed it some data. Data is typically introduced to a PyMC model in one of two ways. Some data is used as an exogenous input, called X in linear regression models, where mu = X @ beta. Other data are “observed” examples of the endogenous outputs of your model, called y in regression models, and is used as input to the likelihood function implied by your model. These data, either exogenous or endogenous, can be included in your model as wide variety of datatypes, including numpy ndarrays, pandas Series and DataFrame, and even pytensor TensorVariables.
GLM: Robust Regression using Custom Likelihood for Outlier Classification
- 17 November 2021
Using PyMC for Robust Regression with Outlier Detection using the Hogg 2010 Signal vs Noise method.
Estimating parameters of a distribution from awkwardly binned data
- 23 October 2021
Let us say that we are interested in inferring the properties of a population. This could be anything from the distribution of age, or income, or body mass index, or a whole range of different possible measures. In completing this task, we might often come across the situation where we have multiple datasets, each of which can inform our beliefs about the overall population.
Sequential Monte Carlo
- 19 October 2021
Sampling from distributions with multiple peaks with standard MCMC methods can be difficult, if not impossible, as the Markov chain often gets stuck in either of the minima. A Sequential Monte Carlo sampler (SMC) is a way to ameliorate this problem.
GLM: Mini-batch ADVI on hierarchical regression model
- 23 September 2021
Unlike Gaussian mixture models, (hierarchical) regression models have independent variables. These variables affect the likelihood function, but are not random variables. When using mini-batch, we should take care of that.
Marginalized Gaussian Mixture Model
- 18 September 2021
Gaussian mixtures are a flexible class of models for data that exhibits subpopulation heterogeneity. A toy example of such a data set is shown below.
Dirichlet process mixtures for density estimation
- 16 September 2021
The Dirichlet process is a flexible probability distribution over the space of distributions. Most generally, a probability distribution, \(P\), on a set \(\Omega\) is a [measure](https://en.wikipedia.org/wiki/Measure_(mathematics%29) that assigns measure one to the entire space (\(P(\Omega) = 1\)). A Dirichlet process \(P \sim \textrm{DP}(\alpha, P_0)\) is a measure that has the property that, for every finite disjoint partition \(S_1, \ldots, S_n\) of \(\Omega\),
Introduction to Bayesian A/B Testing
- 23 May 2021
This notebook demonstrates how to implement a Bayesian analysis of an A/B test. We implement the models discussed in VWO’s Bayesian A/B Testing Whitepaper [], and discuss the effect of different prior choices for these models. This notebook does not discuss other related topics like how to choose a prior, early stopping, and power analysis.
Heteroskedastic Gaussian Processes
- 05 May 2021
We can typically divide the sources of uncertainty in our models into two categories. “Aleatoric” uncertainty (from the Latin word for dice or randomness) arises from the intrinsic variability of our system. “Epistemic” uncertainty (from the Greek word for knowledge) arises from how our observations are placed throughout the domain of interest.
Using a custom step method for sampling from locally conjugate posterior distributions
- 17 November 2020
Markov chain Monte Carlo (MCMC) sampling methods are fundamental to modern Bayesian inference. PyMC leverages Hamiltonian Monte Carlo (HMC), a powerful sampling algorithm that efficiently explores high-dimensional posterior distributions. Unlike simpler MCMC methods, HMC harnesses the gradient of the log posterior density to make intelligent proposals, allowing it to effectively sample complex posteriors with hundreds or thousands of parameters. A key advantage of HMC is its generality - it works with arbitrary prior distributions and likelihood functions, without requiring conjugate pairs or closed-form solutions. This is crucial since most real-world models involve priors and likelihoods whose product cannot be analytically integrated to obtain the posterior distribution. HMC’s gradient-guided proposals make it dramatically more efficient than earlier MCMC approaches that rely on random walks or simple proposal distributions.
Diagnosing Biased Inference with Divergences
- 06 February 2018
This notebook is inspired by Michael Betancourt’s post on mc-stan, but we have adapted to reflect improvements in diagnostics since then and to show best practices. For discussion on the theory behind divergences and how they relate to biased inference, you can read A Conceptual Introduction to Hamiltonian Monte Carlo.
Student-t Process
- 06 August 2017
PyMC also includes T-process priors. They are a generalization of a Gaussian process prior to the multivariate Student’s T distribution. The usage is identical to that of gp.Latent, except they require a degrees of freedom parameter when they are specified in the model. For more information, see chapter 9 of Rasmussen+Williams, and Shah et al..
Dependent density regression
- 06 June 2017
In another example, we showed how to use Dirichlet processes to perform Bayesian nonparametric density estimation. This example expands on the previous one, illustrating dependent density regression.
Updating Priors
- 06 January 2017
In this notebook, we will show how, in principle, it is possible to update the priors as new data becomes available.
Inferring parameters of SDEs using a Euler-Maruyama scheme
- 06 July 2016
This notebook is derived from a presentation prepared for the Theoretical Neuroscience Group, Institute of Systems Neuroscience at Aix-Marseile University.