
Posts in advanced
Bayesian Workflow with SEMs
- 30 September 2025
This case study extends the themes of contemporary Bayesian workflow and Structural Equation Modelling. While both topics are well represented in the PyMC examples library, our goal here is to show how the principles of the Bayesian workflow can be applied concretely to structural equation models (SEMs). The iterative and expansionary strategies of model development for SEMs provide an independent motivation for the recommendations of [Gelman et al., 2020] stemming from the SEM literature broadly. But [Kline, 2023] in particular highlights the utility of a staggered approach to model development as a diagnostic for model mis-specification.
Bayesian Non-parametric Causal Inference
- 30 January 2024
There are few claims stronger than the assertion of a causal relationship and few claims more contestable. A naive world model - rich with tenuous connections and non-sequiter implications is characteristic of conspiracy theory and idiocy. On the other hand, a refined and detailed knowledge of cause and effect characterised by clear expectations, plausible connections and compelling counterfactuals, will steer you well through the buzzing, blooming confusion of the world.
Discrete Choice and Random Utility Models
- 30 June 2023
This notebook uses libraries that are not PyMC dependencies and therefore need to be installed specifically to run this notebook. Open the dropdown below for extra guidance.
Longitudinal Models of Change
- 30 April 2023
The study of change involves simultaneously analysing the individual trajectories of change and abstracting over the set of individuals studied to extract broader insight about the nature of the change in question. As such it’s easy to lose sight of the forest for the focus on the trees. In this example we’ll demonstrate some of the subtleties of using hierarchical bayesian models to study the change within a population of individuals - moving from the within individual view to the between/cross individuals perspective.
Bayesian Missing Data Imputation
- 28 February 2023
Duplicate implicit target name: “bayesian missing data imputation”.
Using ModelBuilder class for deploying PyMC models
- 22 February 2023
Many users face difficulty in deploying their PyMC models to production because deploying/saving/loading a user-created model is not well standardized. One of the reasons behind this is there is no direct way to save or load a model in PyMC like scikit-learn or TensorFlow. The new ModelBuilder class is aimed to improve this workflow by providing a scikit-learn inspired API to wrap your PyMC models.
Pathfinder Variational Inference
- 05 February 2023
Pathfinder [Zhang et al., 2021] is a variational inference algorithm that produces samples from the posterior of a Bayesian model. It compares favorably to the widely used ADVI algorithm. On large problems, it should scale better than most MCMC algorithms, including dynamic HMC (i.e. NUTS), at the cost of a more biased estimate of the posterior. For details on the algorithm, see the arxiv preprint.
Empirical Approximation overview
- 13 January 2023
For most models we use sampling MCMC algorithms like Metropolis or NUTS. In PyMC we got used to store traces of MCMC samples and then do analysis using them. There is a similar concept for the variational inference submodule in PyMC: Empirical. This type of approximation stores particles for the SVGD sampler. There is no difference between independent SVGD particles and MCMC samples. Empirical acts as a bridge between MCMC sampling output and full-fledged VI utils like apply_replacements or sample_node. For the interface description, see variational_api_quickstart. Here we will just focus on Emprical and give an overview of specific things for the Empirical approximation.
Fitting a Reinforcement Learning Model to Behavioral Data with PyMC
- 05 August 2022
Reinforcement Learning models are commonly used in behavioral research to model how animals and humans learn, in situtions where they get to make repeated choices that are followed by some form of feedback, such as a reward or a punishment.
Gaussian Processes using numpy kernel
- 31 July 2022
Example of simple Gaussian Process fit, adapted from Stan’s example-models repository.
How to wrap a JAX function for use in PyMC
- 24 March 2022
This notebook uses libraries that are not PyMC dependencies and therefore need to be installed specifically to run this notebook. Open the dropdown below for extra guidance.
Factor analysis
- 19 March 2022
Factor analysis is a widely used probabilistic model for identifying low-rank structure in multivariate data as encoded in latent variables. It is very closely related to principal components analysis, and differs only in the prior distributions assumed for these latent variables. It is also a good example of a linear Gaussian model as it can be described entirely as a linear transformation of underlying Gaussian variates. For a high-level view of how factor analysis relates to other models, you can check out this diagram originally published by Ghahramani and Roweis.
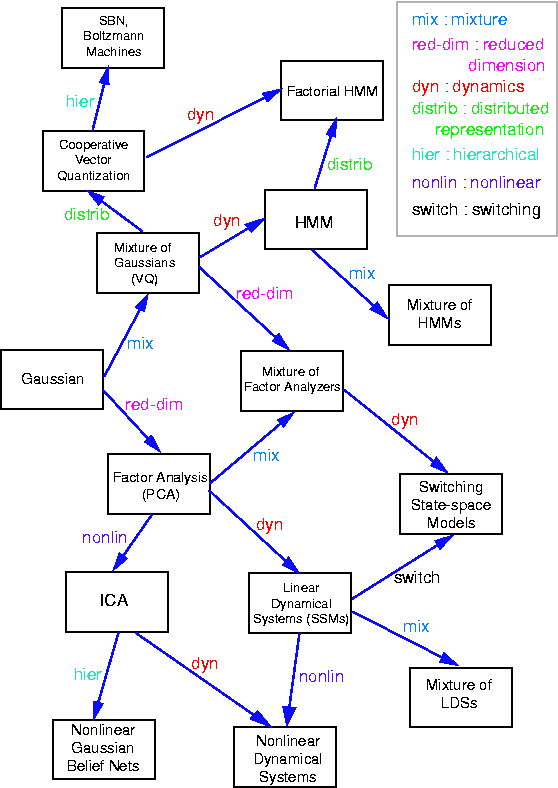{kind=link}
Dirichlet mixtures of multinomials
- 08 January 2022
This example notebook demonstrates the use of a Dirichlet mixture of multinomials (a.k.a Dirichlet-multinomial or DM) to model categorical count data. Models like this one are important in a variety of areas, including natural language processing, ecology, bioinformatics, and more.
Using a “black box” likelihood function
- 16 December 2021
There is a related example that discusses how to use a likelihood implemented in JAX
Dirichlet process mixtures for density estimation
- 16 September 2021
The Dirichlet process is a flexible probability distribution over the space of distributions. Most generally, a probability distribution, \(P\), on a set \(\Omega\) is a [measure](https://en.wikipedia.org/wiki/Measure_(mathematics%29) that assigns measure one to the entire space (\(P(\Omega) = 1\)). A Dirichlet process \(P \sim \textrm{DP}(\alpha, P_0)\) is a measure that has the property that, for every finite disjoint partition \(S_1, \ldots, S_n\) of \(\Omega\),
Using a custom step method for sampling from locally conjugate posterior distributions
- 17 November 2020
Markov chain Monte Carlo (MCMC) sampling methods are fundamental to modern Bayesian inference. PyMC leverages Hamiltonian Monte Carlo (HMC), a powerful sampling algorithm that efficiently explores high-dimensional posterior distributions. Unlike simpler MCMC methods, HMC harnesses the gradient of the log posterior density to make intelligent proposals, allowing it to effectively sample complex posteriors with hundreds or thousands of parameters. A key advantage of HMC is its generality - it works with arbitrary prior distributions and likelihood functions, without requiring conjugate pairs or closed-form solutions. This is crucial since most real-world models involve priors and likelihoods whose product cannot be analytically integrated to obtain the posterior distribution. HMC’s gradient-guided proposals make it dramatically more efficient than earlier MCMC approaches that rely on random walks or simple proposal distributions.
Inferring parameters of SDEs using a Euler-Maruyama scheme
- 30 July 2016
This notebook is derived from a presentation prepared for the Theoretical Neuroscience Group, Institute of Systems Neuroscience at Aix-Marseile University.