



Stochastic Volatility model#
import os
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
rng = np.random.RandomState(1234)
az.style.use("arviz-darkgrid")
Asset prices have time-varying volatility (variance of day over day returns). In some periods, returns are highly variable, while in others very stable. Stochastic volatility models model this with a latent volatility variable, modeled as a stochastic process. The following model is similar to the one described in the No-U-Turn Sampler paper, [Hoffman and Gelman, 2014].
Here, \(r\) is the daily return series and \(s\) is the latent log volatility process.
Build Model#
First we load daily returns of the S&P 500, and calculate the daily log returns. This data is from May 2008 to November 2019.
try:
returns = pd.read_csv(os.path.join("..", "data", "SP500.csv"), index_col="Date")
except FileNotFoundError:
returns = pd.read_csv(pm.get_data("SP500.csv"), index_col="Date")
returns["change"] = np.log(returns["Close"]).diff()
returns = returns.dropna()
returns.head()
| Close | change | |
|---|---|---|
| Date | ||
| 2008-05-05 | 1407.489990 | -0.004544 |
| 2008-05-06 | 1418.260010 | 0.007623 |
| 2008-05-07 | 1392.569946 | -0.018280 |
| 2008-05-08 | 1397.680054 | 0.003663 |
| 2008-05-09 | 1388.280029 | -0.006748 |
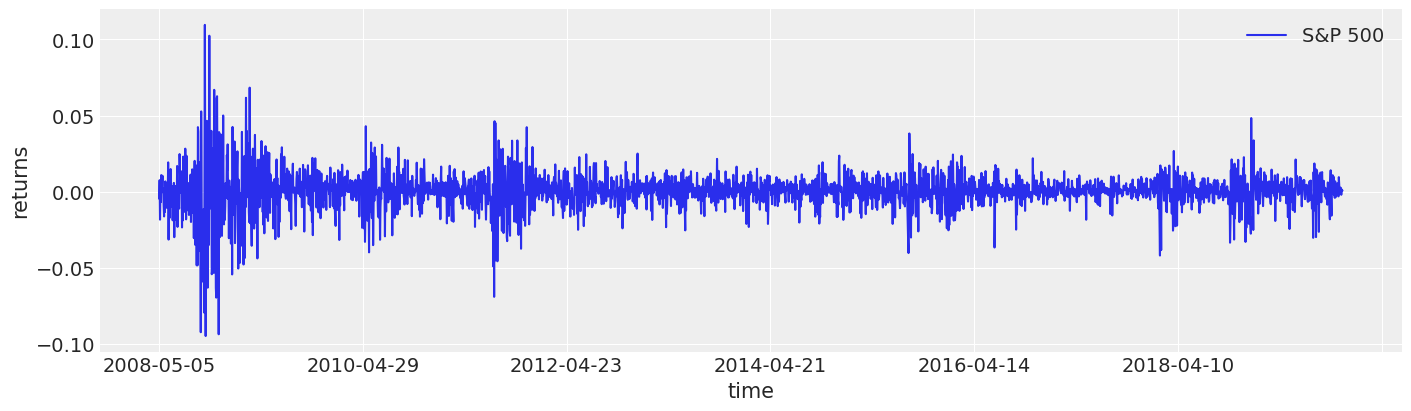
As you can see, the volatility seems to change over time quite a bit but cluster around certain time-periods. For example, the 2008 financial crisis is easy to pick out.
fig, ax = plt.subplots(figsize=(14, 4))
returns.plot(y="change", label="S&P 500", ax=ax)
ax.set(xlabel="time", ylabel="returns")
ax.legend();
Specifying the model in PyMC mirrors its statistical specification.
def make_stochastic_volatility_model(data):
with pm.Model(coords={"time": data.index.values}) as model:
step_size = pm.Exponential("step_size", 10)
volatility = pm.GaussianRandomWalk(
"volatility", sigma=step_size, dims="time", init_dist=pm.Normal.dist(0, 100)
)
nu = pm.Exponential("nu", 0.1)
returns = pm.StudentT(
"returns", nu=nu, lam=np.exp(-2 * volatility), observed=data["change"], dims="time"
)
return model
stochastic_vol_model = make_stochastic_volatility_model(returns)
Checking the model#
Two good things to do to make sure our model is what we expect is to
Take a look at the model structure. This lets us know we specified the priors we wanted and the connections we wanted. It is also handy to remind ourselves of the size of the random variables.
Take a look at the prior predictive samples. This helps us interpret what our priors imply about the data.
pm.model_to_graphviz(stochastic_vol_model)

with stochastic_vol_model:
idata = pm.sample_prior_predictive(500, random_seed=rng)
prior_predictive = az.extract(idata, group="prior_predictive")
Sampling: [nu, returns, step_size, volatility]
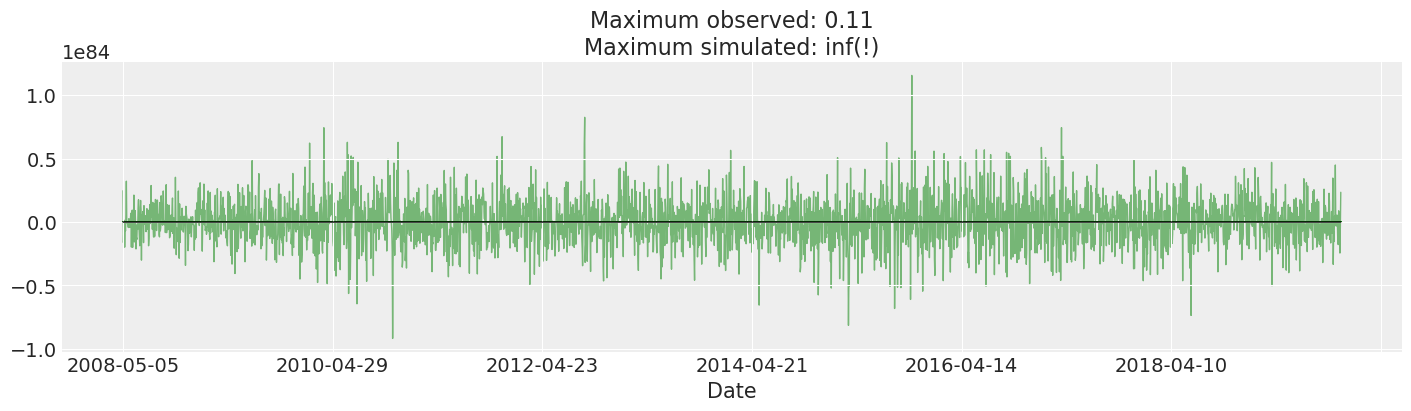
We plot and inspect the prior predictive. This is many orders of magnitude larger than the actual returns we observed. In fact, I cherry-picked a few draws to keep the plot from looking silly. This may suggest changing our priors: a return that our model considers plausible would violate all sorts of constraints by a huge margin: the total value of all goods and services the world produces is ~\(\$10^9\), so we might reasonably not expect any returns above that magnitude.
That said, we get somewhat reasonable results fitting this model anyways, and it is standard, so we leave it as is.
fig, ax = plt.subplots(figsize=(14, 4))
returns["change"].plot(ax=ax, lw=1, color="black")
ax.plot(
prior_predictive["returns"][:, 0::10],
"g",
alpha=0.5,
lw=1,
zorder=-10,
)
max_observed, max_simulated = np.max(np.abs(returns["change"])), np.max(
np.abs(prior_predictive["returns"].values)
)
ax.set_title(f"Maximum observed: {max_observed:.2g}\nMaximum simulated: {max_simulated:.2g}(!)");
Fit Model#
Once we are happy with our model, we can sample from the posterior. This is a somewhat tricky model to fit even with NUTS, so we sample and tune a little longer than default.
with stochastic_vol_model:
idata.extend(pm.sample(random_seed=rng))
posterior = az.extract(idata)
posterior["exp_volatility"] = np.exp(posterior["volatility"])
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 113 seconds.
with stochastic_vol_model:
idata.extend(pm.sample_posterior_predictive(idata, random_seed=rng))
posterior_predictive = az.extract(idata, group="posterior_predictive")
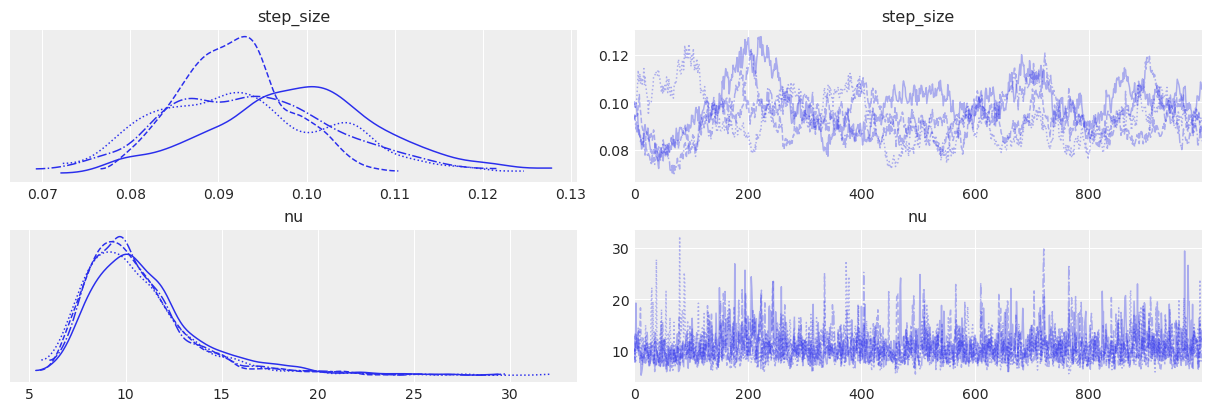
Note that the step_size parameter does not look perfect: the different chains look somewhat different. This again indicates some weakness in our model: it may make sense to allow the step_size to change over time, especially over this 11 year time span.
az.plot_trace(idata, var_names=["step_size", "nu"]);
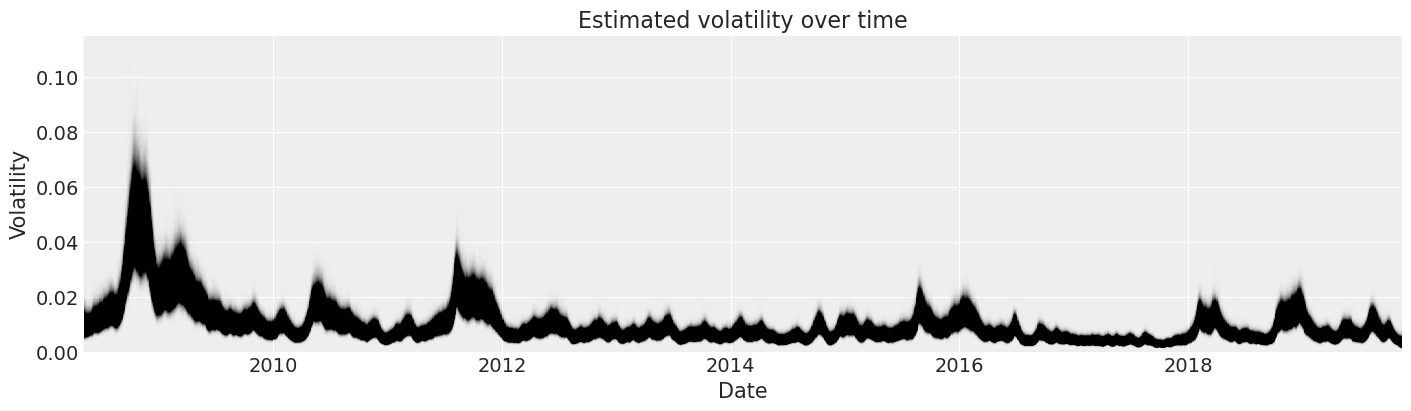
Now we can look at our posterior estimates of the volatility in S&P 500 returns over time.
fig, ax = plt.subplots(figsize=(14, 4))
y_vals = posterior["exp_volatility"]
x_vals = y_vals.time.astype(np.datetime64)
plt.plot(x_vals, y_vals, "k", alpha=0.002)
ax.set_xlim(x_vals.min(), x_vals.max())
ax.set_ylim(bottom=0)
ax.set(title="Estimated volatility over time", xlabel="Date", ylabel="Volatility");
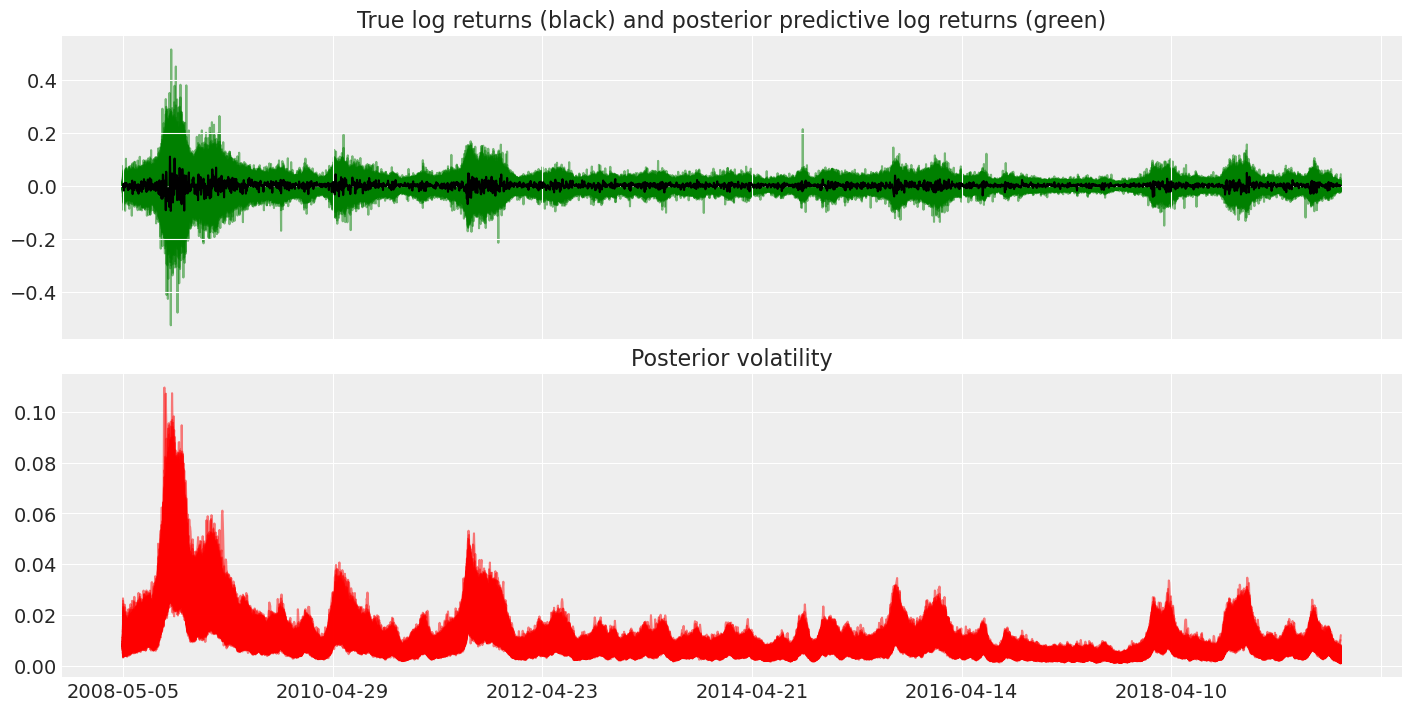
Finally, we can use the posterior predictive distribution to see the how the learned volatility could have effected returns.
fig, axes = plt.subplots(nrows=2, figsize=(14, 7), sharex=True)
returns["change"].plot(ax=axes[0], color="black")
axes[1].plot(posterior["exp_volatility"], "r", alpha=0.5)
axes[0].plot(
posterior_predictive["returns"],
"g",
alpha=0.5,
zorder=-10,
)
axes[0].set_title("True log returns (black) and posterior predictive log returns (green)")
axes[1].set_title("Posterior volatility");
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor,aeppl,xarray
Last updated: Sun Feb 05 2023
Python implementation: CPython
Python version : 3.10.9
IPython version : 8.9.0
pytensor: 2.8.11
aeppl : not installed
xarray : 2023.1.0
arviz : 0.14.0
pymc : 5.0.1
matplotlib: 3.6.3
numpy : 1.24.1
pandas : 1.5.3
Watermark: 2.3.1
References#
Matthew Hoffman and Andrew Gelman. The no-u-turn sampler: adaptively setting path lengths in hamiltonian monte carlo. Journal of Machine Learning Research, 15:1593–1623, 2014. URL: https://dl.acm.org/doi/10.5555/2627435.2638586.
License notice#
All the notebooks in this example gallery are provided under the MIT License which allows modification, and redistribution for any use provided the copyright and license notices are preserved.
Citing PyMC examples#
To cite this notebook, use the DOI provided by Zenodo for the pymc-examples repository.
Important
Many notebooks are adapted from other sources: blogs, books… In such cases you should cite the original source as well.
Also remember to cite the relevant libraries used by your code.
Here is an citation template in bibtex:
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
which once rendered could look like: