



Bayesian regression with truncated or censored data#
The notebook provides an example of how to conduct linear regression when your outcome variable is either censored or truncated.
from copy import copy
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pymc as pm
import xarray as xr
from numpy.random import default_rng
from scipy.stats import norm, truncnorm
%config InlineBackend.figure_format = 'retina'
rng = default_rng(12345)
az.style.use("arviz-darkgrid")
Truncation and censoring#
Truncation and censoring are examples of missing data problems. It can sometimes be easy to muddle up truncation and censoring, so let’s look at some definitions.
Truncation is a type of missing data problem where you are simply unaware of any data where the outcome variable falls outside of a certain set of bounds.
Censoring occurs when a measurement has a sensitivity with a certain set of bounds. But rather than discard data outside these bounds, you would record a measurement at the bound which it exceeded.
Let’s further explore this with some code and plots. First we will generate some true (x, y) scatter data, where y is our outcome measure and x is some predictor variable.
slope, intercept, σ, N = 1, 0, 2, 200
x = rng.uniform(-10, 10, N)
y = rng.normal(loc=slope * x + intercept, scale=σ)
For this example of (x, y) scatter data, we can describe the truncation process as simply filtering out any data for which our outcome variable y falls outside of a set of bounds.
def truncate_y(x, y, bounds):
keep = (y >= bounds[0]) & (y <= bounds[1])
return (x[keep], y[keep])
With censoring however, we are setting the y value equal to the bounds that they exceed.
def censor_y(x, y, bounds):
cy = copy(y)
cy[y <= bounds[0]] = bounds[0]
cy[y >= bounds[1]] = bounds[1]
return (x, cy)
Based on our generated (x, y) data (which an experimenter would never see in real life), we can generate our actual observed datasets for truncated data (xt, yt) and censored data (xc, yc).
bounds = [-5, 5]
xt, yt = truncate_y(x, y, bounds)
xc, yc = censor_y(x, y, bounds)
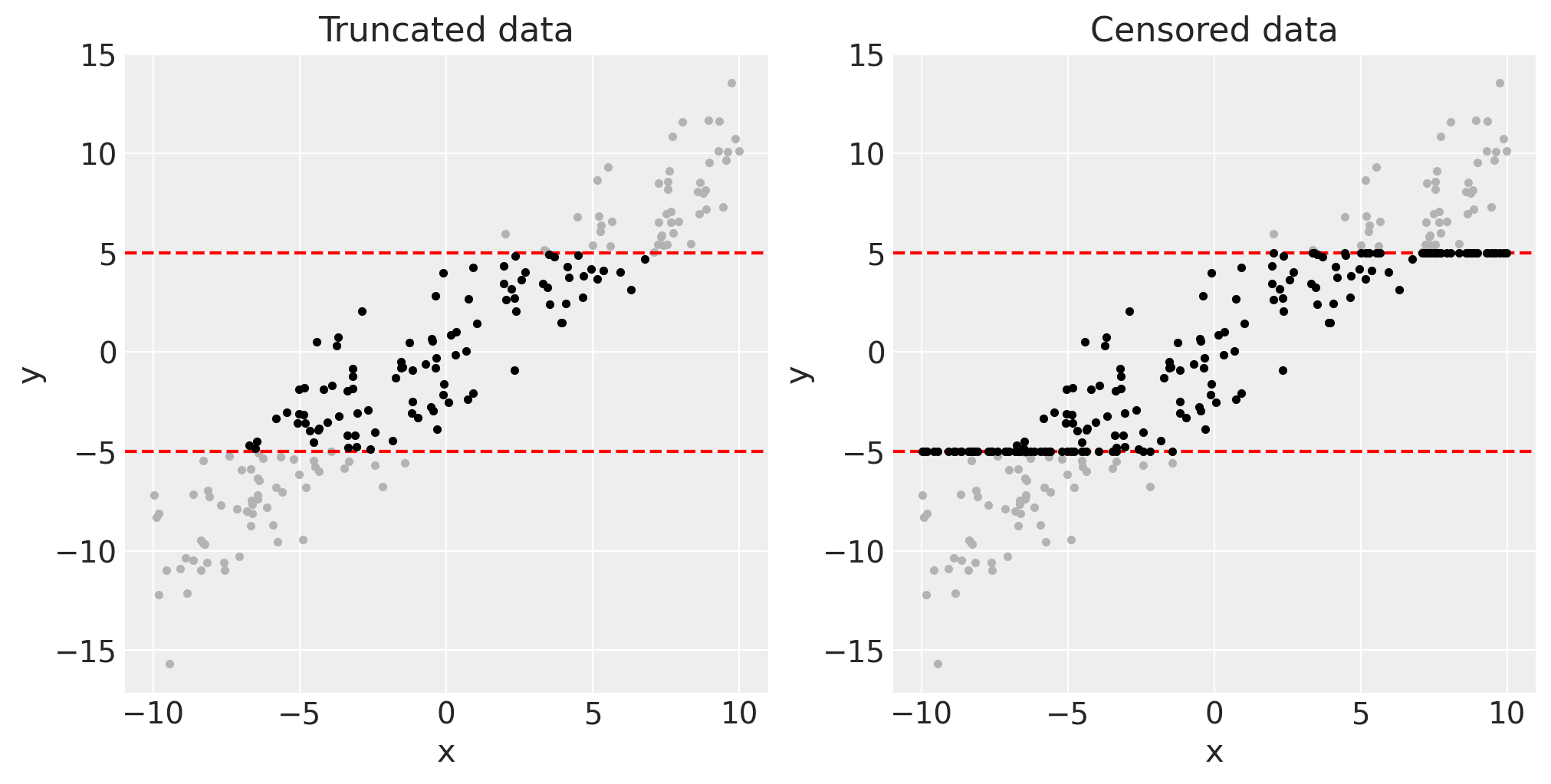
We can visualise this latent data (in grey) and the remaining truncated or censored data (black) as below.
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
for ax in axes:
ax.plot(x, y, ".", c=[0.7, 0.7, 0.7])
ax.axhline(bounds[0], c="r", ls="--")
ax.axhline(bounds[1], c="r", ls="--")
ax.set(xlabel="x", ylabel="y")
axes[0].plot(xt, yt, ".", c=[0, 0, 0])
axes[0].set(title="Truncated data")
axes[1].plot(xc, yc, ".", c=[0, 0, 0])
axes[1].set(title="Censored data");
The problem that truncated or censored regression solves#
If we were to run regular linear regression on either the truncated or censored data, it should be fairly intuitive to see that we will likely underestimate the slope. Truncated regression and censored regress (aka Tobit regression) were designed to address these missing data problems and hopefully result in regression slopes which are free from the bias introduced by truncation or censoring.
In this section we will run Bayesian linear regression on these datasets to see the extent of the problem. We start by defining a function which defines a PyMC model, conducts MCMC sampling, and returns the model and the MCMC sampling data.
def linear_regression(x, y):
with pm.Model() as model:
slope = pm.Normal("slope", mu=0, sigma=1)
intercept = pm.Normal("intercept", mu=0, sigma=1)
σ = pm.HalfNormal("σ", sigma=1)
pm.Normal("obs", mu=slope * x + intercept, sigma=σ, observed=y)
return model
So we can run this on our truncated and our censored data, separately.
trunc_linear_model = linear_regression(xt, yt)
with trunc_linear_model:
trunc_linear_fit = pm.sample()
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
cens_linear_model = linear_regression(xc, yc)
with cens_linear_model:
cens_linear_fit = pm.sample()
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
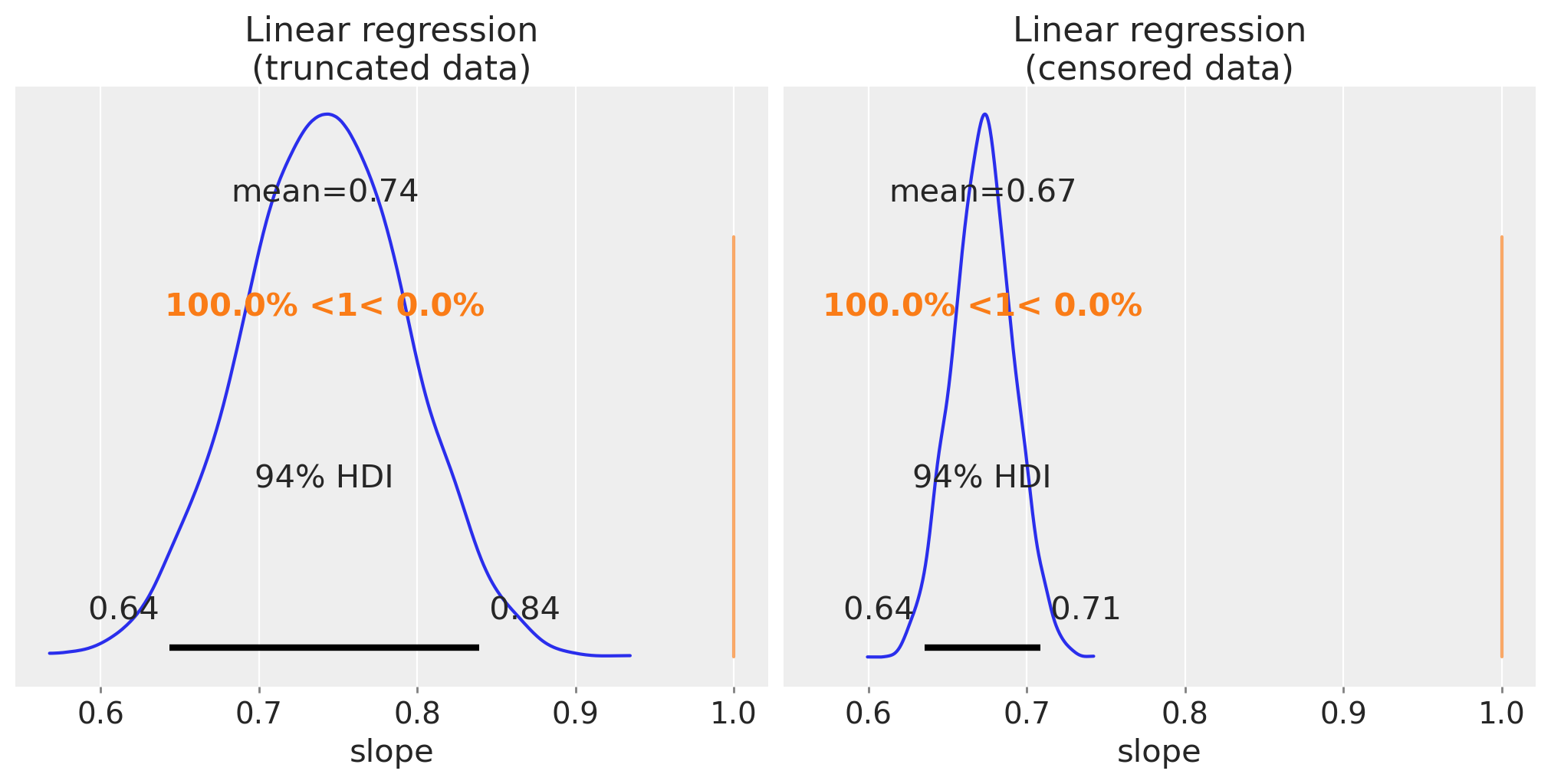
By plotting the posterior distribution over the slope parameters we can see that the estimates for the slope are pretty far off, so we are indeed underestimating the regression slope.
fig, ax = plt.subplots(1, 2, figsize=(10, 5), sharex=True)
az.plot_posterior(trunc_linear_fit, var_names=["slope"], ref_val=slope, ax=ax[0])
ax[0].set(title="Linear regression\n(truncated data)", xlabel="slope")
az.plot_posterior(cens_linear_fit, var_names=["slope"], ref_val=slope, ax=ax[1])
ax[1].set(title="Linear regression\n(censored data)", xlabel="slope");
To appreciate the extent of the problem (for this dataset) we can visualise the posterior predictive fits alongside the data.
def pp_plot(x, y, fit, ax):
# plot data
ax.plot(x, y, "k.")
# plot posterior predicted... samples from posterior
xi = xr.DataArray(np.array([np.min(x), np.max(x)]), dims=["obs_id"])
post = az.extract(fit)
y_ppc = xi * post["slope"] + post["intercept"]
ax.plot(xi, y_ppc, c="steelblue", alpha=0.01, rasterized=True)
# plot true
ax.plot(xi, slope * xi + intercept, "k", lw=3, label="True")
# plot bounds
ax.axhline(bounds[0], c="r", ls="--")
ax.axhline(bounds[1], c="r", ls="--")
ax.legend()
ax.set(xlabel="x", ylabel="y")
fig, ax = plt.subplots(1, 2, figsize=(10, 5), sharex=True, sharey=True)
pp_plot(xt, yt, trunc_linear_fit, ax[0])
ax[0].set(title="Truncated data")
pp_plot(xc, yc, cens_linear_fit, ax[1])
ax[1].set(title="Censored data");
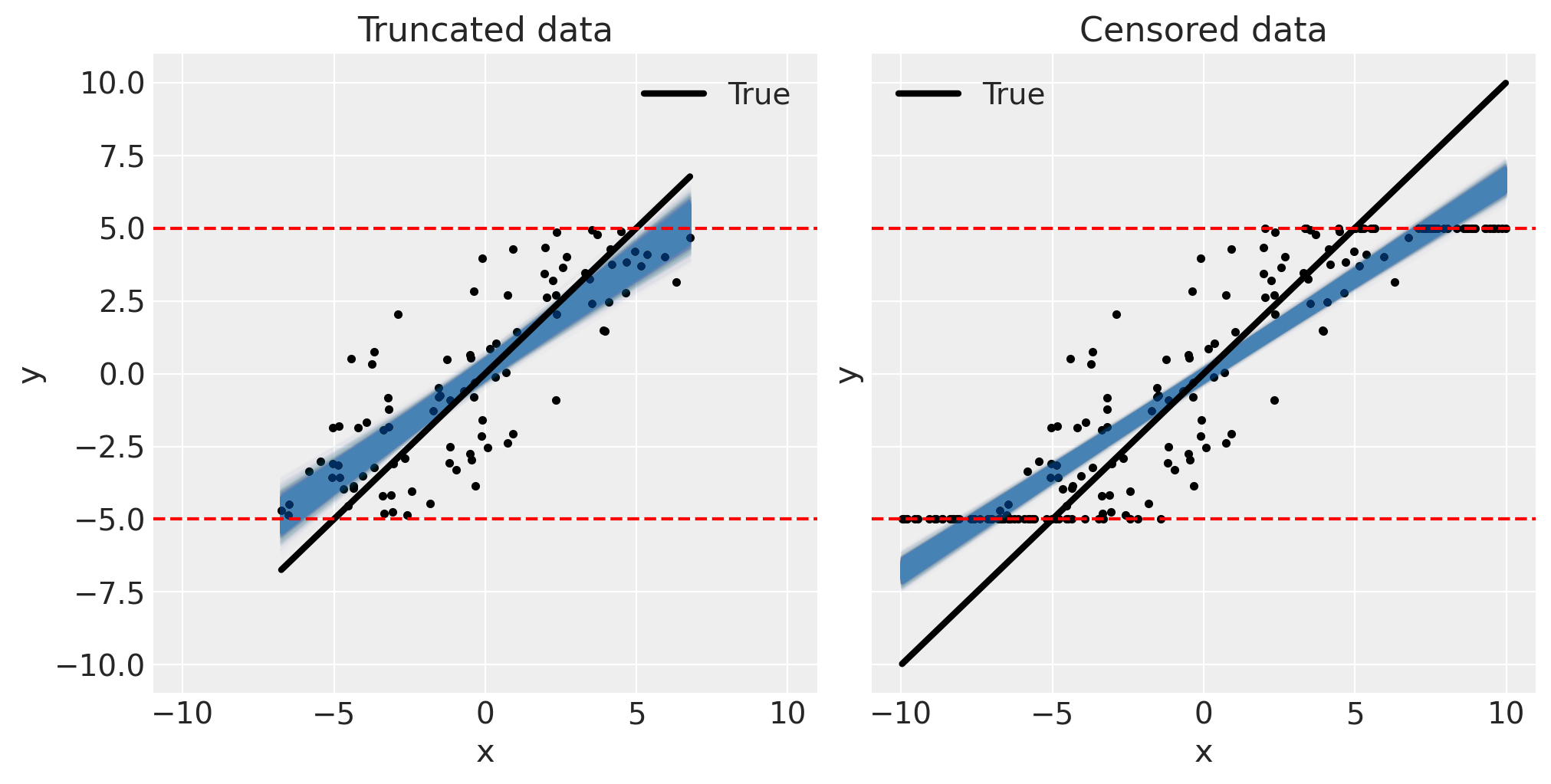
By looking at these plots we can intuitively predict what factors will influence the extent of the underestimation bias. Firstly, if the truncation or censoring bounds are very broad such that they only affect a few data points, then the underestimation bias would be smaller. Secondly, if the measurement error σ is low, we might expect the underestimation bias to decrease. In the limit of zero measurement noise then it should be possible to fully recover the true slope for truncated data but there will always be some bias in the censored case. Regardless, it would be prudent to use truncated or censored regression models unless the measurement error is near zero, or the bounds are so broad as to be practically irrelevant.
Implementing truncated and censored regression models#
Now we have seen the problem of conducting regression on truncated or censored data, in terms of underestimating the regression slopes. This is what truncated or censored regression models were designed to solve. The general approach taken by both truncated and censored regression is to encode our prior knowledge of the truncation or censoring steps in the data generating process. This is done by modifying the likelihood function in various ways.
Truncated regression model#
Truncated regression models are quite simple to implement. The normal likelihood is centered on the regression slope as normal, but now we just specify a normal distribution which is truncated at the bounds.
def truncated_regression(x, y, bounds):
with pm.Model() as model:
slope = pm.Normal("slope", mu=0, sigma=1)
intercept = pm.Normal("intercept", mu=0, sigma=1)
σ = pm.HalfNormal("σ", sigma=1)
normal_dist = pm.Normal.dist(mu=slope * x + intercept, sigma=σ)
pm.Truncated("obs", normal_dist, lower=bounds[0], upper=bounds[1], observed=y)
return model
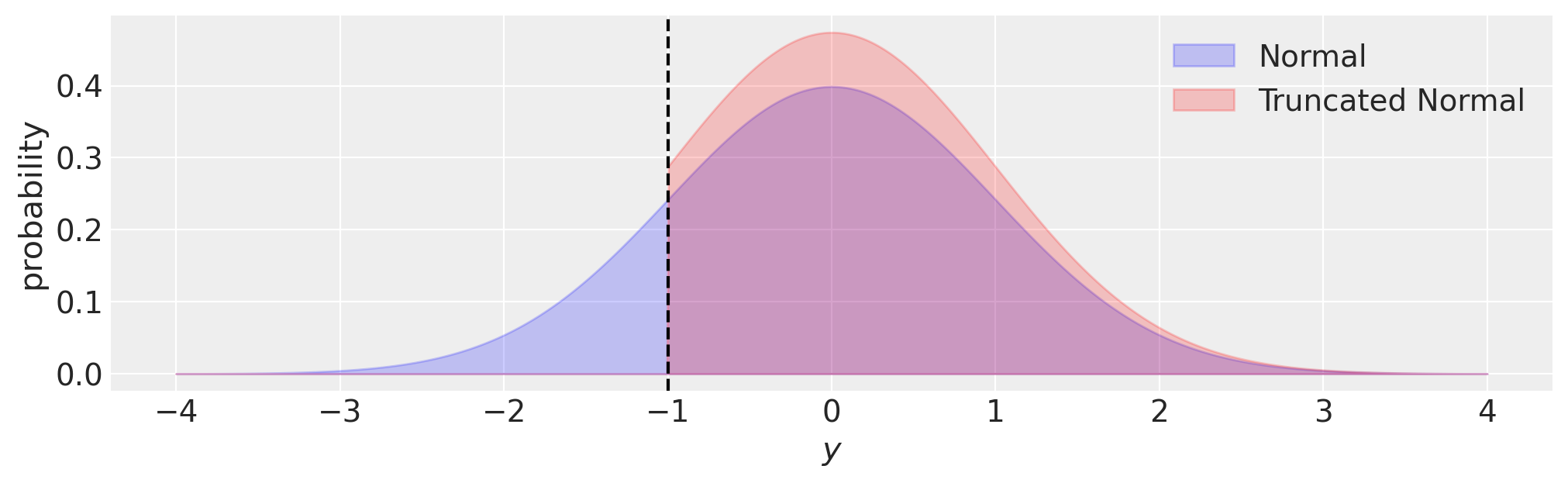
Truncated regression solves the bias problem by updating the likelihood to reflect our knowledge about the process generating the observations. Namely, we have zero chance of observing any data outside of the truncation bounds, and so the likelihood should reflect this. We can visualise this in the plot below, where compared to a normal distribution, the probability density of a truncated normal is zero outside of the truncation bounds \((y<-1)\) in this case.
fig, ax = plt.subplots(figsize=(10, 3))
y = np.linspace(-4, 4, 1000)
ax.fill_between(y, norm.pdf(y, loc=0, scale=1), 0, alpha=0.2, ec="b", fc="b", label="Normal")
ax.fill_between(
y,
truncnorm.pdf(y, -1, float("inf"), loc=0, scale=1),
0,
alpha=0.2,
ec="r",
fc="r",
label="Truncated Normal",
)
ax.set(xlabel="$y$", ylabel="probability")
ax.axvline(-1, c="k", ls="--")
ax.legend();
Censored regression model#
def censored_regression(x, y, bounds):
with pm.Model() as model:
slope = pm.Normal("slope", mu=0, sigma=1)
intercept = pm.Normal("intercept", mu=0, sigma=1)
σ = pm.HalfNormal("σ", sigma=1)
y_latent = pm.Normal.dist(mu=slope * x + intercept, sigma=σ)
obs = pm.Censored("obs", y_latent, lower=bounds[0], upper=bounds[1], observed=y)
return model
Thanks to the new pm.Censored distribution it is really straightforward to write models with censored data. The only thing to remember is that the latent variable being censored must be called with the .dist method, as in pm.Normal.dist in the model above.
Behind the scenes, pm.Censored adjusts the likelihood function to take into account that:
the probability at the lower bound is equal to the cumulative distribution function from \(-\infty\) to the lower bound,
the probability at the upper bound is equal to the the cumulative distribution function from the upper bound to \(\infty\).
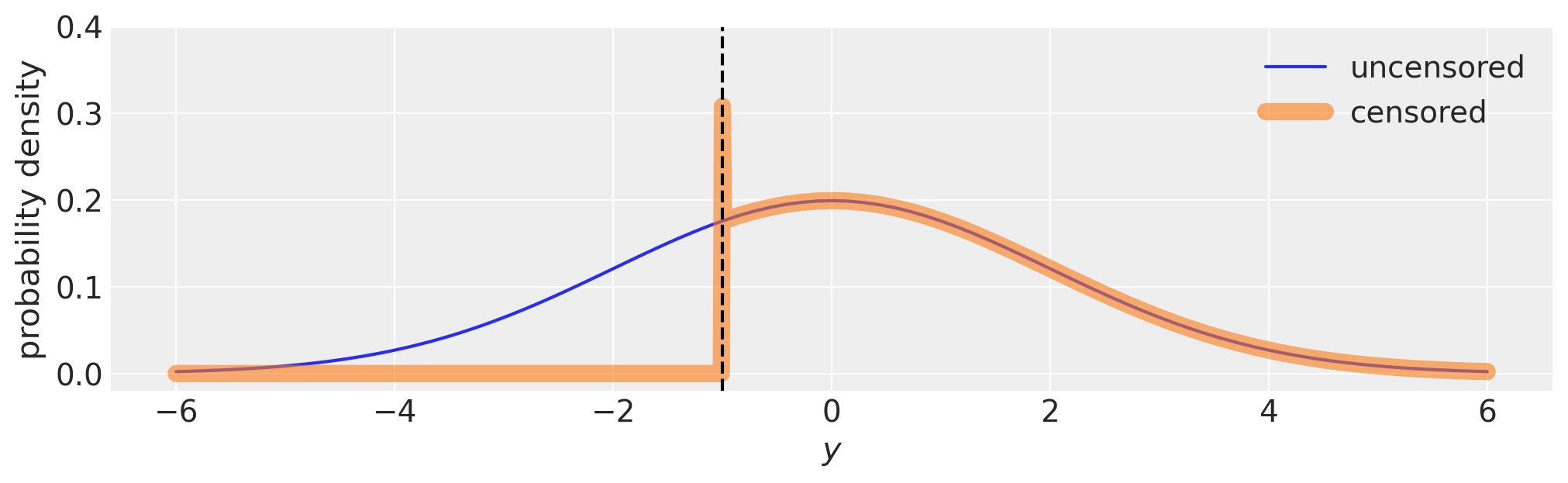
This is demonstrated visually in the plot below. Technically the probability density at the bound is infinite because the bin width exactly at the bound is zero.
fig, ax = plt.subplots(figsize=(10, 3))
with pm.Model() as m:
pm.Normal("y", 0, 2)
with pm.Model() as m_censored:
pm.Censored("y", pm.Normal.dist(0, 2), lower=-1.0, upper=None)
logp_fn = m.compile_logp()
logp_censored_fn = m_censored.compile_logp()
xi = np.hstack((np.linspace(-6, -1.01), [-1.0], np.linspace(-0.99, 6)))
ax.plot(xi, [np.exp(logp_fn({"y": x})) for x in xi], label="uncensored")
ax.plot(xi, [np.exp(logp_censored_fn({"y": x})) for x in xi], label="censored", lw=8, alpha=0.6)
ax.axvline(-1, c="k", ls="--")
ax.legend()
ax.set(xlabel="$y$", ylabel="probability density", ylim=(-0.02, 0.4));
Run the truncated and censored regressions#
Now we can conduct our parameter estimation with the truncated regression model on the truncated data…
truncated_model = truncated_regression(xt, yt, bounds)
with truncated_model:
truncated_fit = pm.sample()
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
and with the censored regression model on the censored data.
censored_model = censored_regression(xc, yc, bounds)
with censored_model:
censored_fit = pm.sample(init="adapt_diag")
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
We can do the same as before and visualise our posterior estimates on the slope.
fig, ax = plt.subplots(1, 2, figsize=(10, 5), sharex=True)
az.plot_posterior(truncated_fit, var_names=["slope"], ref_val=slope, ax=ax[0])
ax[0].set(title="Truncated regression\n(truncated data)", xlabel="slope")
az.plot_posterior(censored_fit, var_names=["slope"], ref_val=slope, ax=ax[1])
ax[1].set(title="Censored regression\n(censored data)", xlabel="slope");
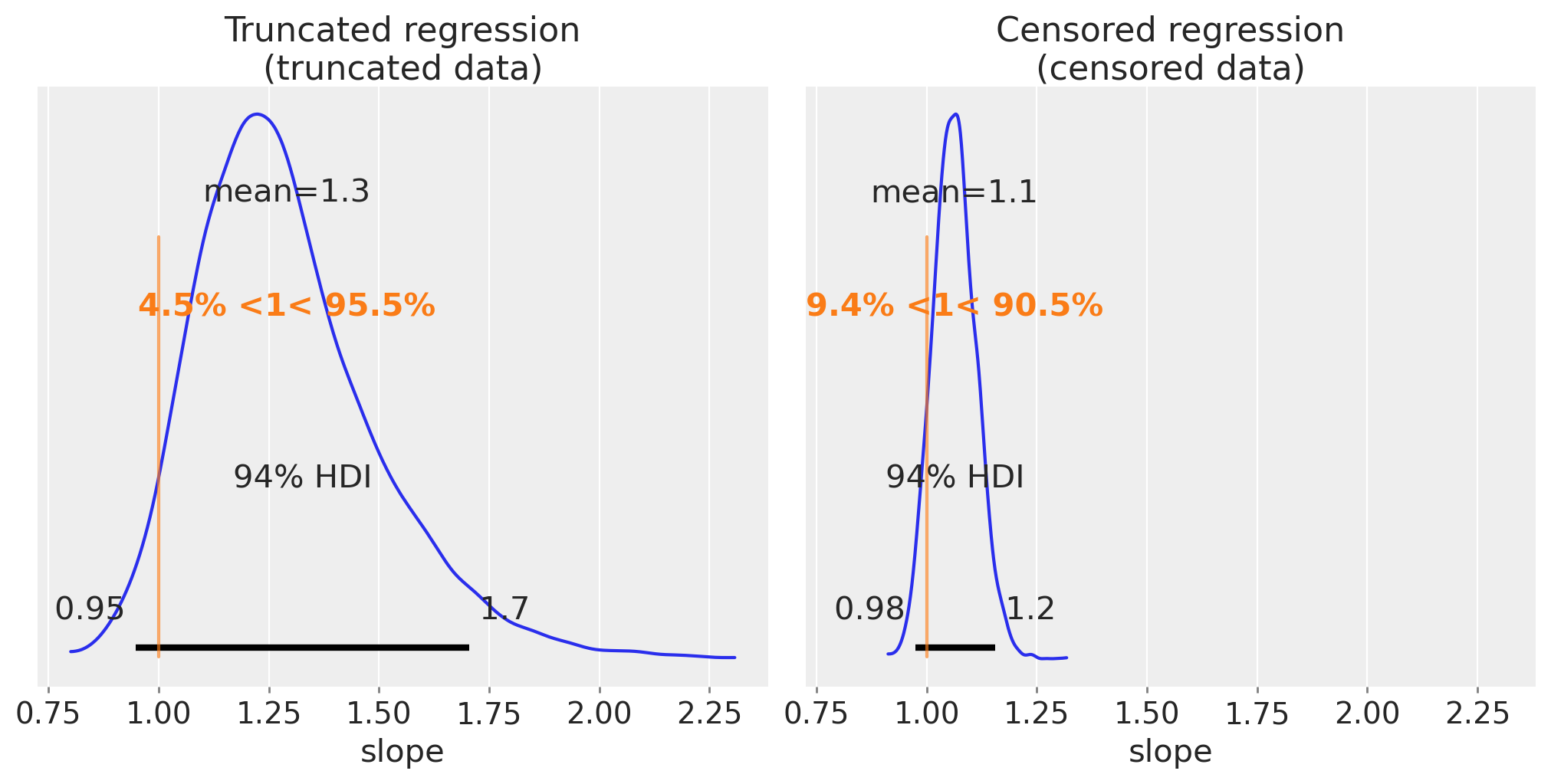
These are much better estimates. Interestingly, we can see that the estimate for censored regression is more precise than for truncated data. This will not necessarily always be the case, but the intuition here is that the x and y data is entirely discarded with truncation, but only the y data becomes partially unknown in censoring.
We could speculate then, that if an experimenter had the choice of truncating or censoring data, it might be better to opt for censoring over truncation.
Correspondingly, we can confirm the models are good through visual inspection of the posterior predictive plots.
fig, ax = plt.subplots(1, 2, figsize=(10, 5), sharex=True, sharey=True)
pp_plot(xt, yt, truncated_fit, ax[0])
ax[0].set(title="Truncated data")
pp_plot(xc, yc, censored_fit, ax[1])
ax[1].set(title="Censored data");
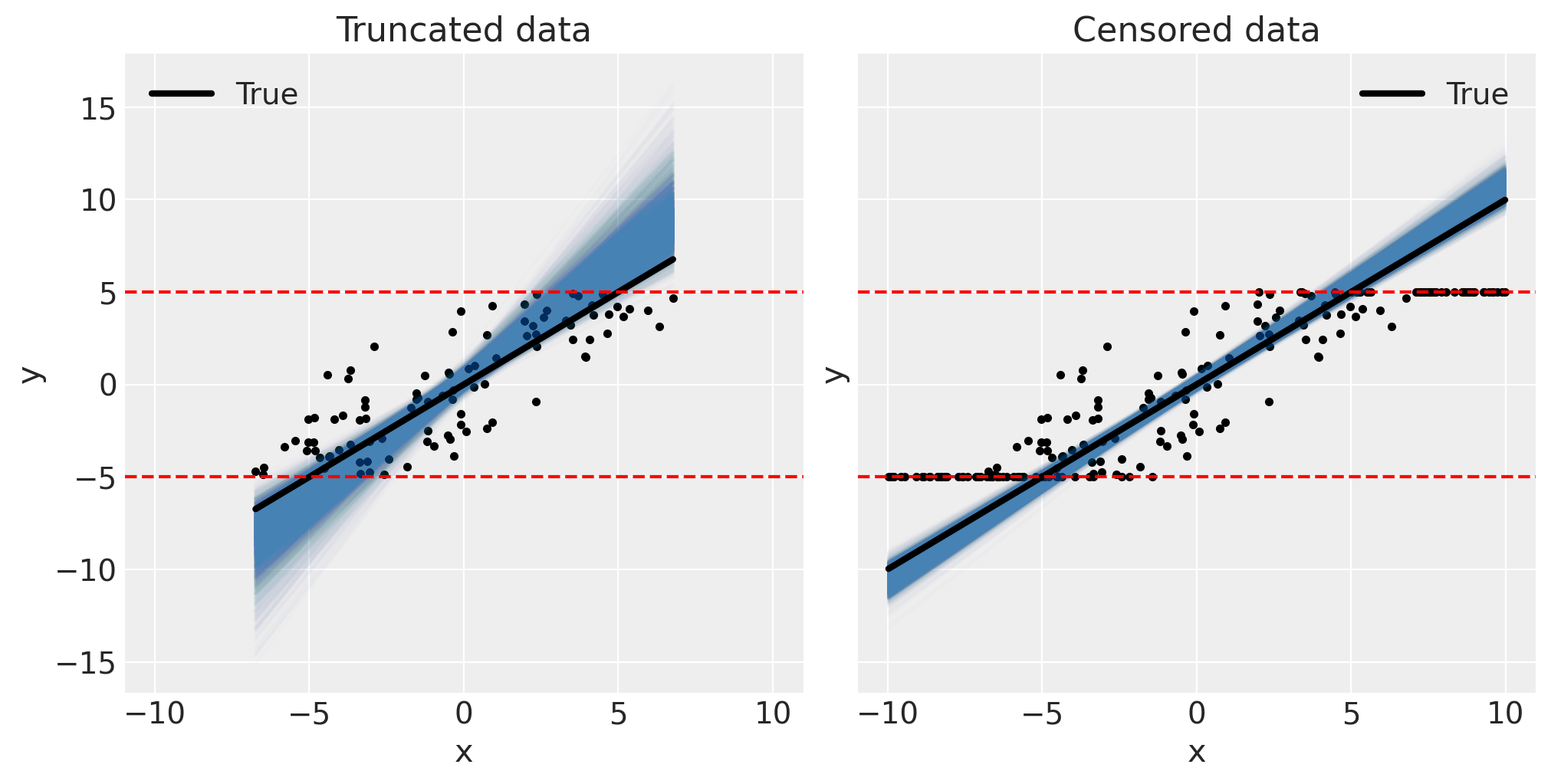
This brings an end to our guide on truncated and censored data and truncated and censored regression models in PyMC. While the extent of the regression slope estimation bias will vary with a number of factors discussed above, hopefully these examples have convinced you of the importance of encoding your knowledge of the data generating process into regression analyses.
Further topics#
It is also possible to treat the bounds as unknown latent parameters. If these are not known exactly and it is possible to fomulate a prior over these bounds, then it would be possible to infer what the bounds are. This could be argued as overkill however - depending on your data analysis context it may be entirely sufficient to extract ‘good enough’ point estimates of the bounds in order to get reasonable regression estimates.
The censored regression model presented above takes one particular approach, and there are others. For example, it did not attempt to infer posterior beliefs over the true latent y values of the censored data. It is possible to build censored regression models which do impute these censored y values, but we did not address that here as the topic of imputation deserves its own focused treatment. The PyMC Censored Data Models example also covers this topic, with a particular example model to impute censored data.
Further reading#
When looking into this topic, I found that most of the material out there focuses on maximum likelihood estimation approaches, with focus on mathematical derivation rather than practical implementation. One good concise mathematical 80 page booklet by Breen and others [1996] covers truncated and censored as well as other missing data scenarios. That said, a few pages are given over to this topic in Bayesian Data Analysis by Gelman et al. [2013], and Gelman et al. [2020].
References#
Andrew Gelman, John B. Carlin, Hal S. Stern, David B. Dunson, Aki Vehtari, and Donald B. Rubin. Bayesian Data Analysis. Chapman and Hall/CRC, 2013.
Andrew Gelman, Jennifer Hill, and Aki Vehtari. Regression and other stories. Cambridge University Press, 2020.
Richard Breen and others. Regression models: Censored, sample selected, or truncated data. Volume 111. Sage, 1996.
Watermark#
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor,aeppl
Last updated: Sun Feb 05 2023
Python implementation: CPython
Python version : 3.10.9
IPython version : 8.9.0
pytensor: 2.8.11
aeppl : not installed
numpy : 1.24.1
arviz : 0.14.0
matplotlib: 3.6.3
pymc : 5.0.1
xarray : 2023.1.0
Watermark: 2.3.1
License notice#
All the notebooks in this example gallery are provided under the MIT License which allows modification, and redistribution for any use provided the copyright and license notices are preserved.
Citing PyMC examples#
To cite this notebook, use the DOI provided by Zenodo for the pymc-examples repository.
Important
Many notebooks are adapted from other sources: blogs, books… In such cases you should cite the original source as well.
Also remember to cite the relevant libraries used by your code.
Here is an citation template in bibtex:
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
which once rendered could look like: