



The Besag-York-Mollie Model for Spatial Data#
import os
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
import pytensor.tensor as pt
from scipy import sparse
from scipy.linalg import solve
from scipy.sparse.linalg import spsolve
Attention
This notebook uses libraries that are not PyMC dependencies and therefore need to be installed specifically to run this notebook. Open the dropdown below for extra guidance.
Extra dependencies install instructions
In order to run this notebook (either locally or on binder) you won’t only need a working PyMC installation with all optional dependencies, but also to install some extra dependencies. For advise on installing PyMC itself, please refer to Installation
You can install these dependencies with your preferred package manager, we provide as an example the pip and conda commands below.
$ pip install nutpie networkx
Note that if you want (or need) to install the packages from inside the notebook instead of the command line, you can install the packages by running a variation of the pip command:
import sys
!{sys.executable} -m pip install nutpie networkx
You should not run !pip install as it might install the package in a different
environment and not be available from the Jupyter notebook even if installed.
Another alternative is using conda instead:
$ conda install nutpie networkx
when installing scientific python packages with conda, we recommend using conda forge
# these libraries are not dependencies of pymc
import networkx as nx
import nutpie
RANDOM_SEED = 8926
rng = np.random.default_rng(RANDOM_SEED)
az.style.use("arviz-darkgrid")
Why use the Besag-York-Mollie model?#
This notebook explains why and how to deploy the Besag-York-Mollie (BYM) model in PyMC. The BYM model is an attractive approach to many spatial statistics problems. It’s flexible - once you add the BYM components, the rest of the workflow proceeds like any other Bayesian generalized linear model. You can add predictors to estimate causal effects. You can swap out link functions and outcome distributions to handle different data types. You can mix and match whatever samplers work best.
BYM also scales well with large datasets. A common problem with spatial models is that their computational cost grows rapidly as the size of the dataset increases. This is the case, for example, with PyMC’s CAR model. With the BYM model, the growth in computational cost is nearly linear.
The BYM model works with areal data, such as neighboring states, counties, or census tracks. For problems involving spatial points or continuous measures of distance, consider using a Gaussian Process instead.
Powered by ICAR#
The main engine that powers the BYM model is an intrinsic conditional autoregressive prior (ICAR). ICAR is a special kind of multivariate normal distribution that assumes adjacent areas covary.
It helps to adopt a bit of the vocabulary of graph theory when talking about spatial modeling. A graph is composed of nodes and edges. The nodes represent the areas in space while the edges represent proximity. In this type of problem, we draw an edge between two areas that share a border.
Suppose we have a graph like the one built from an adjacency matrix W below.

The adjacency matrix encodes which nodes are connected to which other nodes. If node i and j are connected, there will be a 1 at row i, column j. Otherwise, there will be a zero. For example, node 1 and 3 are connected. There is a 1 in the matrix at row 3, column 1. However node 3 is not connected to node 2, so there is a 0 at row 3 column 2. We have to, of course, remember python indexing. The first row is 0 and the last is 3. Adjacency matrices are also symmetrical - if Canada is adjacent to the United States, the United States is adjacent to Canada.
The density function for ICAR takes in an adjacency matrix W and a variance \(\sigma\). We usually assume \(\sigma = 1\) and deal with variance in other ways so I’ll ignore that first fraction for now.
Each \(\phi_{i}\) is penalized based on the square distance from each of its neighbors. The notation \(i \sim j\) indicates a sum over all the neighbors of \(\phi_{i}\).
So, for example, imagine that the intensity of the color represents the value of a variable at each node. Node 1 is connected to everyone. Node 1 and 0 have a fairly similar color so the penalty would be small. But node 2 has a pretty different color from node 1, so it would receive a large penalty. If we move our attention to node 3, it only has one neighbor and would receive just a single large penalty based on the distance from node 1.
In this way, ICAR encodes the core assumption of spatial statistics - nearby areas should be more similar to each other than distant areas. The most likely outcome is a graph where every node has the same value. In this case, the square distance between neighbors is always zero. The more a graph experiences abrupt changes between neighboring areas, the lower the log density.
ICAR has a few other special features: it is constrained so all the \(\phi\)’s add up to zero. This also implies the mean of the \(\phi\)’s is zero. It can be helpful to think of ICAR values as similar to z-scores. They represent relative deviations centered around 0. ICAR is also typically only used as a sub-component of a larger model. Other parts of the model typically adjust the scale (with a variance parameter) or the location (with an intercept parameter). An accessible discussion of the math behind ICAR and its relationship to CAR can be found here or in the academic paper version [Morris et al., 2019].
The flexbility of random effects#
One of the typical goals of statistical modeling is to partition the variance of the data into three categories: variance explained by the causes of interest, structured variance and unstructured variance. In our case, the ICAR model is meant to capture the (spatially) structured variance. Adding predictor variables can handle the first category. The BYM model approaches the third category with random effects, \(\theta\). A random effect is a vector of random variables of length n where n is the number of areas. It is meant to capture all the remaining variance not explained by spatial or causal effects.
Constructing a model that includes both structured and unstructured variance can be tricky. Naive approaches often run into issues of identifiability. Each component can, in principle, independently explain the variance. So the fitting algorithm might not be able to settle into a small neighborhood in the parameter space.
The BYM model is delicately designed to solve issues of identifiability. It uses a mixture distribution where the parameter \(\rho\) controls the balance of structured to unstructured variance. The BYM model looks this:
When \(\rho\) is close to 1, most of the variance is spatially structured. When \(\rho\) is close to 0, most of the variance is unstructured.
\(\sigma\) is a scale parameter shared by both \(\theta\) and \(\phi\). Both \(\theta\) and \(\phi\) are centered at zero and have a variance of 1. So they both function like z-scores. \(\sigma\) can stretch or shrink the mixture of effects so it is appropriate for the actual data. \(\beta\) is a shared intercept that recenters the mixture to fit the data. Finally, \(\text{s}\) is the scaling factor. It is a constant computed from the adjacency matrix. It rescales the \(\phi\)’s so that they have the same expected variance as \(\theta\). A more detailed discussion of why this works appears below.
Fitting this model takes care of the challenge of partitioning variance into structure and unstructured components. The only challenge left is settling on predictor variables, a challenge that varies from case to case. Riebler et al. [2016] put forward this particular approach to the BYM model and offers more explanation of why this parameterization of the BYM model is both interpretable and identifiable while previous parameterizations of the BYM models are often not.
Demonstrating the BYM model on the New York City pedestrian accidents dataset#
We’ll demonstrate the BYM model on a dataset recording the number of traffic accidents involving pedestrians in New York City. The data is organized into roughly 2000 census tracts, providing our spatial structure. Our goal is to demonstrate that we can partition the variance into explained, spatially structured, and unstructured components.
Setup the data#
The spatial data comes in the form of an edgelist. Beside adjacency matrices, edgelists are the other popular technique for representing areal data on computers. An edgelist is a pair of lists that stores information about the edges in a graph. Suppose that i and j are the names of two nodes. If node i and node j are connected, then one list will contain i and the other will contain j on the same row. For example, in the dataframe below, node 1 is connected to node 1452 as well as node 1721.
try:
df_edges = pd.read_csv(os.path.join("..", "data", "nyc_edgelist.csv"))
except FileNotFoundError:
df_edges = pd.read_csv(pm.get_data("nyc_edgelist.csv"))
df_edges
| N | N_edges | node1 | node2 | |
|---|---|---|---|---|
| 0 | 1921 | 5461 | 1 | 1452 |
| 1 | 1921 | 5461 | 1 | 1721 |
| 2 | 1921 | 5461 | 2 | 3 |
| 3 | 1921 | 5461 | 2 | 4 |
| 4 | 1921 | 5461 | 2 | 5 |
| ... | ... | ... | ... | ... |
| 5456 | 1921 | 5461 | 1918 | 1919 |
| 5457 | 1921 | 5461 | 1918 | 1921 |
| 5458 | 1921 | 5461 | 1919 | 1920 |
| 5459 | 1921 | 5461 | 1919 | 1921 |
| 5460 | 1921 | 5461 | 1920 | 1921 |
5461 rows × 4 columns
To actually get our model running, however, we’ll need to convert the edgelist to an adjacency matrix. The code below performs that task along with some other clean up tasks.
# convert edgelist to adjacency matrix
# extract and reformat the edgelist
nodes = np.stack((df_edges.node1.values, df_edges.node2.values))
nodes = nodes.T
# subtract one for python indexing
nodes = nodes - 1
# convert the number of nodes to a integer
N = int(df_edges.N.values[0])
# build a matrix of zeros to store adjacency
# it has size NxN where N is the number of
# areas in the dataset
adj = np.zeros((N, N))
# loop through the edgelist and assign 1
# to the location in the adjacency matrix
# to represent the edge
# this will only fill in the upper triangle
# of the matrix
for node in nodes:
adj[tuple(node)] = 1
# add the transpose to make the adjacency
# matrix symmetrical
W_nyc = adj.T + adj
We’ll compute the scaling factor. It will require a special function which is fairly involved. A proper explanation of the function would take us pretty far afield from the NYC case study so I’ll leave discussion of the scaling factor for later.
def scaling_factor_sp(A):
"""Compute the scaling factor from an adjacency matrix.
This function uses sparse matrix computations and is most
efficient on sparse adjacency matrices. Used in the BYM2 model.
The scaling factor is a measure of the variance in the number of
edges across nodes in a connected graph.
Only works for fully connected graphs. The argument for scaling
factors is developed by Andrea Riebler, Sigrunn H. Sørbye,
Daniel Simpson, Havard Rue in "An intuitive Bayesian spatial
model for disease mapping that accounts for scaling"
https://arxiv.org/abs/1601.01180"""
# Computes the precision matrix in sparse format
# from an adjacency matrix.
num_neighbors = A.sum(axis=1)
A = sparse.csc_matrix(A)
D = sparse.diags(num_neighbors, format="csc")
Q = D - A
# add a small jitter along the diagonal
Q_perturbed = Q + sparse.diags(np.ones(Q.shape[0])) * max(Q.diagonal()) * np.sqrt(
np.finfo(np.float64).eps
)
# Compute a version of the pseudo-inverse
n = Q_perturbed.shape[0]
b = sparse.identity(n, format="csc")
Sigma = spsolve(Q_perturbed, b)
A = np.ones(n)
W = Sigma @ A.T
Q_inv = Sigma - np.outer(W * solve(A @ W, np.ones(1)), W.T)
# Compute the geometric mean of the diagonal on a
# precision matrix.
return np.exp(np.sum(np.log(np.diag(Q_inv))) / n)
scaling_factor = scaling_factor_sp(W_nyc)
scaling_factor
0.7136574058611103
The first .csv file just has the spatial structure bits. The rest of the data comes separately - here we’ll pull in the number of accidents y and the population size of the census track, E. We’ll use the population size as an offset - we should expect that more populated areas will have more accidents for trivial reasons. What is more interesting is something like the excess risk associated with an area.
Finally, we’ll also explore one predictor variable, the social fragmentation index. The index is built out of measures of the number of vacant housing units, people living alone, renters and people who have moved within the previous year. These communities tend to be less integrated and have weaker social support systems. The social epidemiology community is interested in how ecological variables can trickle down into various facets of public health. So we’ll see if social fragmentation can explain the pattern of traffic accidents. The measure is standardized to have a mean of zero and standard deviation of 1.
try:
df_nyc = pd.read_csv(os.path.join("..", "data", "nyc_traffic.csv"))
except FileNotFoundError:
df_nyc = pd.read_csv(pm.get_data("nyc_traffic.csv"))
y = df_nyc.events_2001.values
E = df_nyc.pop_2001.values
fragment_index = df_nyc.fragment_index.values
# Most census tracts have huge populations
# but a handful have 0. We round
# those up to 10 to avoid triggering an error
# with the log of 0.
E[E < 10] = 10
log_E = np.log(E)
area_idx = df_nyc["census_tract"].values
coords = {"area_idx": area_idx}
We can get a sense of the spatial structure by visualizing the adjacency matrix. The figure below only captures the relative position of the census tracks. It doesn’t bother with the absolute position so it doesn’t look like New York City. This representation highlights how the city is composed of several regions of uniformly connected areas, a few central hubs that have a huge number of connections, and then a few narrow corridors.
# build the positions of the nodes. We'll only
# generate the positions once so that we can
# compare visualizations from the data to
# the model predictions.
# I found that running spectral layout first
# and passing it to spring layout makes easy to read
# visualizations for large datasets.
G_nyc = nx.Graph(W_nyc)
pos = nx.spectral_layout(G_nyc)
pos = nx.spring_layout(G_nyc, pos=pos, seed=RANDOM_SEED)
# the spread of the data is pretty high. Most areas have 0 accidents.
# one area has 300. Color-gradient based visualization doesn't work
# well under those conditions. So for the purpose of the color
# we'll cap the accidents at 30 using vmax
#
# however, we'll also make the node size sensitive to the real
# number of accidents. So big yellow nodes have way more accidents
# than small yellow nodes.
plt.figure(figsize=(10, 8))
nx.draw_networkx(
G_nyc,
pos=pos,
node_color=y,
cmap="plasma",
vmax=30,
width=0.5,
alpha=0.6,
with_labels=False,
node_size=20 + 3 * y,
)
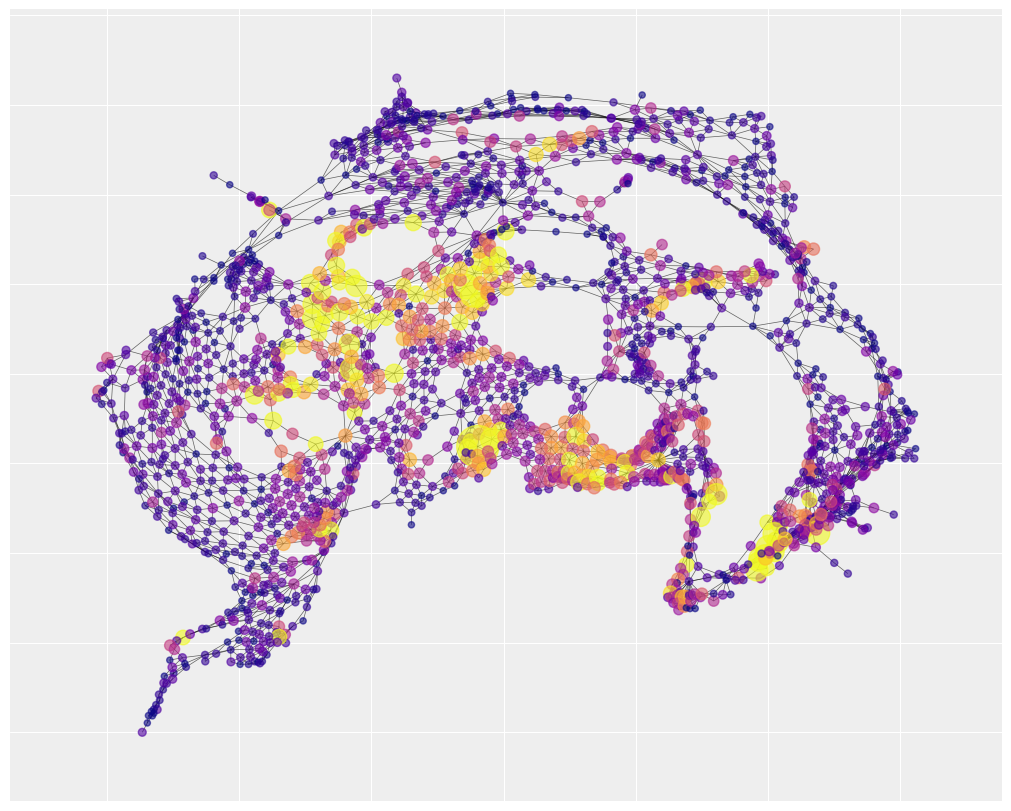
The map also shows there are number of hotspots where most of the accidents take place and they are spatially clustered, namely the bottom right corner, the bottom center and the center left region. This is a good indication that a spatial autocorrelation model is an appropriate choice.
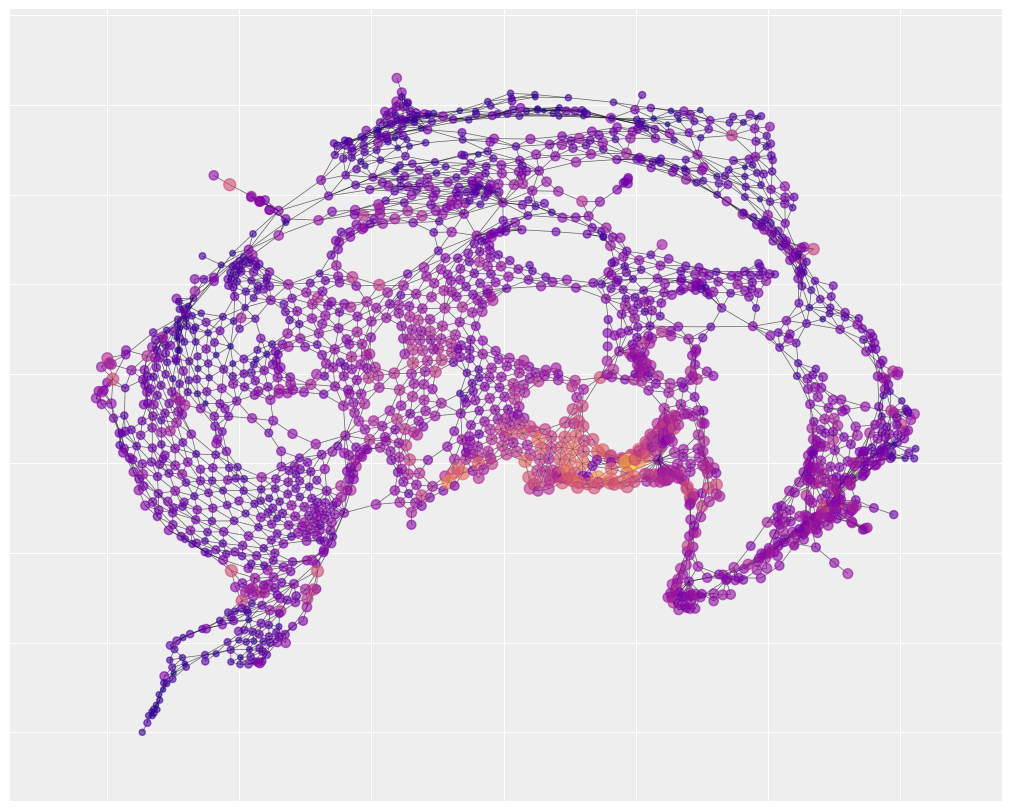
We can also visualize the spatial layout of social fragmentation. You’ll notice that there is one neighborhood of social fragmentation that overlaps with the map of traffic accidents. The statistical analysis below will help us understand how strong that overlap really is.
plt.figure(figsize=(10, 8))
nx.draw_networkx(
G_nyc,
pos=pos,
node_color=fragment_index,
cmap="plasma",
width=0.5,
alpha=0.6,
with_labels=False,
node_size=40 + 5 * fragment_index,
)
Specifying a BYM model with PyMC#
All the parameters of the BYM were already introduced in section 1. Now it’s just a matter of assigning some priors. The priors on \(\theta\) are picky - we need to assign a mean of 0 and a standard deviation 1 so that we can interpret it as comparable with \(\phi\). Otherwise, the priors distributions afford the opportunity to incorporate domain expertise. In this problem, I’ll pick some weakly informative priors.
Lastly, we’ll use a Poisson outcome distribution. The number of traffic accidents is a count outcome and the maximum possible value is very large. To ensure our predictions remain positive, we’ll exponentiate the linear model before passing it to the Poisson distribution.
with pm.Model(coords=coords) as BYM_model:
# intercept
beta0 = pm.Normal("beta0", 0, 1)
# fragmentation effect
beta1 = pm.Normal("beta1", 0, 1)
# independent random effect
theta = pm.Normal("theta", 0, 1, dims="area_idx")
# spatially structured random effect
phi = pm.ICAR("phi", W=W_nyc, dims="area_idx")
# joint variance of random effects
sigma = pm.HalfNormal("sigma", 1)
# the mixing rate is rho
rho = pm.Beta("rho", 0.5, 0.5)
# the bym component - it mixes a spatial and a random effect
mixture = pm.Deterministic(
"mixture", pt.sqrt(1 - rho) * theta + pt.sqrt(rho / scaling_factor) * phi, dims="area_idx"
)
# exponential link function to ensure
# predictions are positive
mu = pm.Deterministic(
"mu", pt.exp(log_E + beta0 + beta1 * fragment_index + sigma * mixture), dims="area_idx"
)
y_i = pm.Poisson("y_i", mu, observed=y)
Sampling the model#
# if you haven't installed nutpie, it's okay to to just delete
# 'nuts_sampler="nutpie"'. The default sampler took roughly 12 minutes on
# my machine.
with BYM_model:
idata = pm.sample(1000, nuts_sampler="nutpie", random_seed=rng)
Sampler Progress
Total Chains: 4
Active Chains: 0
Finished Chains: 4
Sampling for 31 seconds
Estimated Time to Completion: now
| Progress | Draws | Divergences | Step Size | Gradients/Draw |
|---|---|---|---|---|
| 2000 | 0 | 0.13 | 255 | |
| 2000 | 0 | 0.13 | 127 | |
| 2000 | 0 | 0.13 | 63 | |
| 2000 | 0 | 0.13 | 63 |
We can evaluate the sampler in several ways. First, it looks like all our chains converged. All parameters have rhat values very close to one.
rhat = az.summary(idata, kind="diagnostics").r_hat.values
sum(rhat > 1.03)
0
Second, the trace plots on all the main parameters look stationary and well-mixed. They also reveal that the mean of rho is somewhere around 0.50, indicating that spatial effects are likely present in the data.
az.plot_trace(idata, var_names=["beta0", "beta1", "sigma", "rho"])
plt.tight_layout();

Our trace plot also indicates there is a small effect of social fragmentation on traffic accidents with the bulk of the posterior mass between 0.06 and 0.12.
Posterior predictive checking#
The payoff of all this work is that we can now visualize what it means to decompose the variance into explanatory, spatial and unstructured parts. One way to make this vivid is to inspect each component of the model individually. We’ll see what the model thinks NYC should look like if spatial effects were the only source of variance, then we’ll turn to the explanatory effect and finally the random effect.
In the first case, we’ll visualize only the predictions that come from the spatial component of the model. In other words, we are assuming \(\rho = 1\) and we ignore \(\theta\) and social fragmentation.
Then we’ll overlay our predictions onto the same adjacency map we built earlier.
# draw posterio
with pm.do(BYM_model, {"rho": 1.0, "beta1": 0}):
y_predict = pm.sample_posterior_predictive(
idata, var_names=["mu", "mixture"], predictions=True, extend_inferencedata=False
)
y_spatial_pred = y_predict.predictions.mu.mean(dim=["chain", "draw"]).values
plt.figure(figsize=(10, 8))
nx.draw_networkx(
G_nyc,
pos=pos,
node_color=y_spatial_pred,
cmap="plasma",
vmax=30,
width=0.5,
alpha=0.6,
with_labels=False,
node_size=20 + 3 * y_spatial_pred,
)
Sampling: []

The resulting picture is called spatial smoothing. Nearby areas tend to be very similar to each other, resulting in distinct neighborhoods of risk. In the dark purple regions, there is little variance and the number of predicted accidents is low, close to zero.
Spatial smoothing is especially useful for forecasting. Imagine there was a low-accident tract surrounded in a high accident neighborhood. Suppose you wanted to predict where would have high accident numbers in the future so that you could target an intervention on those areas. Focusing only on the ring of tracts that had high accident counts in the past might be a mistake. The focal low-accident tract in the middle probably just had good luck in the past. In the future, that area will probably resemble its neighbors more than its past. Spatial smoothing relies on the same principle behind partial pooling - we can learn more by pooling information from nearby areas to correct for anomalies.
We can notice that there are three neighborhoods of risk, represented by large yellow clusters, that are well-captured. This suggests that a lot of the explanation for traffic accidents has to do with unidentified but spatially structured causes. By contrast, the social fragmentation index only explains a single neighborhood of risk in the bottom center of the map (with a few small pockets of success elsewhere).
with pm.do(
BYM_model,
{
"sigma": 0.0,
},
):
y_predict = pm.sample_posterior_predictive(
idata, var_names=["mu", "mixture"], predictions=True, extend_inferencedata=False
)
y_frag_pred = y_predict.predictions.mu.mean(dim=["chain", "draw"]).values
plt.figure(figsize=(10, 8))
nx.draw_networkx(
G_nyc,
pos=pos,
node_color=y_frag_pred,
cmap="plasma",
vmax=30,
width=0.5,
alpha=0.6,
with_labels=False,
node_size=20 + 3 * y_frag_pred,
)
Sampling: []

Finally, we might look at the unstructured variance by assuming \(\rho = 0\). If our model managed to partition variance successfully, there should not be too many spatial clusters left over in the unstructured variance. Instead, variance should be scattered all over the map.
with pm.do(BYM_model, {"rho": 0.0, "beta1": 0}):
y_predict = pm.sample_posterior_predictive(
idata, var_names=["mu", "mixture"], predictions=True, extend_inferencedata=False
)
y_unspatial_pred = y_predict.predictions.mu.mean(dim=["chain", "draw"]).values
plt.figure(figsize=(10, 8))
nx.draw_networkx(
G_nyc,
pos=pos,
node_color=y_unspatial_pred,
cmap="plasma",
vmax=30,
width=0.5,
alpha=0.6,
with_labels=False,
node_size=20 + 3 * y_unspatial_pred,
)
Sampling: []

What does the scaling factor actually do?#
Discussions of the BYM model often omit talking about the scaling factor in too much detail. There is good reason for this. If your main interest is in epidemiology, you don’t really need to know about it. Users can allow it to just be a black box. The computation of the scaling factor also involves some pretty obscure ideas in linear algebra. I won’t cover the computation here but I will try to provide a bit of intuition for what role it plays in the BYM model.
Take a look at these two graphs.
W1 = np.array([[0, 1, 1, 0], [1, 0, 0, 1], [1, 0, 0, 1], [0, 1, 1, 0]])
G = nx.Graph(W1)
nx.draw(G)
c:\Users\dsaun\Anaconda3\envs\spatial_pymc_env\Lib\site-packages\IPython\core\events.py:89: UserWarning: There are no gridspecs with layoutgrids. Possibly did not call parent GridSpec with the "figure" keyword
func(*args, **kwargs)
c:\Users\dsaun\Anaconda3\envs\spatial_pymc_env\Lib\site-packages\IPython\core\pylabtools.py:152: UserWarning: There are no gridspecs with layoutgrids. Possibly did not call parent GridSpec with the "figure" keyword
fig.canvas.print_figure(bytes_io, **kw)

W2 = np.array([[0, 1, 1, 1], [1, 0, 1, 1], [1, 1, 0, 1], [1, 1, 1, 0]])
G = nx.Graph(W2)
nx.draw(G)

If there is strong spatial covariance between the nodes, we should expect the first graph to allow for more variance than the second graph. In the second graph, every node exercises influence on every other node. So the resulting outcomes should be relatively uniform.
The scaling factor is a measure of how much variance is implied by a particular adjacency matrix. If we compute the scaling factor for the two matrices above, it confirms our intuition. The first graph permits more variance than the second.
scaling_factor_sp(W1), scaling_factor_sp(W2)
(0.31249999534338707, 0.18749999767169354)
A second example can really underscore the point. These are two preferential attachment graphs - a few nodes have a lot of edges and the majority of nodes have very few edges. The only difference is the minimal number of edges. In the first graph, every node gets at least two edges. In the second, each nodes has at least one.
G = nx.barabasi_albert_graph(50, 2)
nx.draw(G)
W_sparse = nx.adjacency_matrix(G, dtype="int")
W = W_sparse.toarray()
print("scaling factor: " + str(scaling_factor_sp(W)))
scaling factor: 0.41031348581585425

G = nx.barabasi_albert_graph(50, 1)
nx.draw(G)
W_sparse = nx.adjacency_matrix(G, dtype="int")
W = W_sparse.toarray()
print("scaling factor: " + str(scaling_factor_sp(W)))
scaling factor: 1.7744552306768082

The second graph has a much higher scaling factor because it is less uniformly connected. There is more opportunity for small pockets to form with distinctive traits. In the first graph, the regularity of connections moderates that opportunity. Again, the scaling factors confirm our intuition.
This much clears up what the scaling factor measures. But why do we need to use it? Let’s revisit the mathematical description of the BYM component:
The goal of the BYM model is that we mix together two different types of random effects and then \(\sigma\) provides the overall variance of the mixture. That means we need to be very careful about the individual variances of each random effect - they both need to equal approximately 1. It’s easy to make sure the variance of \(\theta \approx 1\). We can just specify that as part of the prior. Getting the variance of \(\phi \approx 1\) is harder because the variance comes from data (the spatial structure), not from the prior.
The scaling factor is the trick that ensures the variance of \(\phi\) roughly equals one. When the variance implied by the spatial structure is quite small, say, less than one, dividing \(\rho\) by the scaling factor will give some number greater than one. In other words, we expand the variance of \(\phi\) until it equals one. Now all the other parameters will behave properly. \(\rho\) represents a mixture between two similar things and \(\sigma\) represents the joint variance from random effects.
A final way to understand the purpose of the scaling factor is to imagine what would happen if we didn’t include it. Suppose the graph implied very large variance, like the first preferential attachment graph above. In this case, the mixture parameter, \(\rho\), might pull in more of \(\phi\) because the data has a lot of variance and the model is searching for variance wherever it can find to explain it. But that makes the interpretation of the results challenging. Did \(\rho\) gravitate towards \(\phi\) because there is actually a strong spatial structure? Or because it had higher variance than \(\theta\)? We cannot tell unless we rescale the \(\phi\).
Authors#
Authored by Daniel Saunders in August, 2023 (pymc-examples#566).
References#
Andrea Riebler, Sigrunn H Sørbye, Daniel Simpson, and Håvard Rue. An intuitive bayesian spatial model for disease mapping that accounts for scaling. Statistical methods in medical research, 25(4):1145–1165, 2016.
Mitzi Morris, Katherine Wheeler-Martin, Dan Simpson, Stephen J. Mooney, Andrew Gelman, and Charles DiMaggio. Bayesian hierarchical spatial models: implementing the besag york mollié model in stan. Spatial and Spatio-temporal Epidemiology, 31:100301, 2019. URL: https://www.sciencedirect.com/science/article/pii/S1877584518301175, doi:https://doi.org/10.1016/j.sste.2019.100301.
Watermark#
%load_ext watermark
%watermark -n -u -v -iv -w -p xarray
Last updated: Thu Aug 01 2024
Python implementation: CPython
Python version : 3.11.0
IPython version : 8.8.0
xarray: 2024.3.0
matplotlib: 3.6.2
pytensor : 2.14.2
networkx : 3.0
nutpie : 0.13.0
numpy : 1.24.3
pymc : 5.16.0
pandas : 2.2.2
scipy : 1.10.0
arviz : 0.17.1
Watermark: 2.3.1
License notice#
All the notebooks in this example gallery are provided under the MIT License which allows modification, and redistribution for any use provided the copyright and license notices are preserved.
Citing PyMC examples#
To cite this notebook, use the DOI provided by Zenodo for the pymc-examples repository.
Important
Many notebooks are adapted from other sources: blogs, books… In such cases you should cite the original source as well.
Also remember to cite the relevant libraries used by your code.
Here is an citation template in bibtex:
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
which once rendered could look like: