



ODE Lotka-Volterra With Bayesian Inference in Multiple Ways#
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
import pytensor
import pytensor.tensor as pt
from numba import njit
from pymc.ode import DifferentialEquation
from pytensor.compile.ops import as_op
from scipy.integrate import odeint
from scipy.optimize import least_squares
print(f"Running on PyMC v{pm.__version__}")
Running on PyMC v5.1.2+24.gf3ce16f26
%load_ext watermark
az.style.use("arviz-darkgrid")
rng = np.random.default_rng(1234)
Purpose#
The purpose of this notebook is to demonstrate how to perform Bayesian inference on a system of ordinary differential equations (ODEs), both with and without gradients. The accuracy and efficiency of different samplers are compared.
We will first present the Lotka-Volterra predator-prey ODE model and example data. Next, we will solve the ODE using scipy.odeint and (non-Bayesian) least squares optimization. Next, we perform Bayesian inference in PyMC using non-gradient-based samplers. Finally, we use gradient-based samplers and compare results.
Key Conclusions#
Based on the experiments in this notebook, the most simple and efficient method for performing Bayesian inference on the Lotka-Volterra equations was to specify the ODE system in Scipy, wrap the function as a Pytensor op, and use a Differential Evolution Metropolis (DEMetropolis) sampler in PyMC.
Background#
Motivation#
Ordinary differential equation models (ODEs) are used in a variety of science and engineering domains to model the time evolution of physical variables. A natural choice to estimate the values and uncertainty of model parameters given experimental data is Bayesian inference. However, ODEs can be challenging to specify and solve in the Bayesian setting, therefore, this notebook steps through multiple methods for solving an ODE inference problem using PyMC. The Lotka-Volterra model used in this example has often been used for benchmarking Bayesian inference methods (e.g., in this Stan case study, and in Chapter 16 of Statistical Rethinking [McElreath, 2018].
Lotka-Volterra Predator-Prey Model#
The Lotka-Volterra model describes the interaction between a predator and prey species. This ODE given by:
The state vector \(X(t)=[x(t),y(t)]\) comprises the densities of the prey and the predator species respectively. Parameters \(\boldsymbol{\theta}=[\alpha,\beta,\gamma,\delta, x(0),y(0)]\) are the unknowns that we wish to infer from experimental observations. \(x(0), y(0)\) are the initial values of the states needed to solve the ODE, and \(\alpha,\beta,\gamma\), and \(\delta\) are unknown model parameters which represent the following:
\(\alpha\) is the growing rate of prey when there’s no predator.
\(\beta\) is the dying rate of prey due to predation.
\(\gamma\) is the dying rate of predator when there is no prey.
\(\delta\) is the growing rate of predator in the presence of prey.
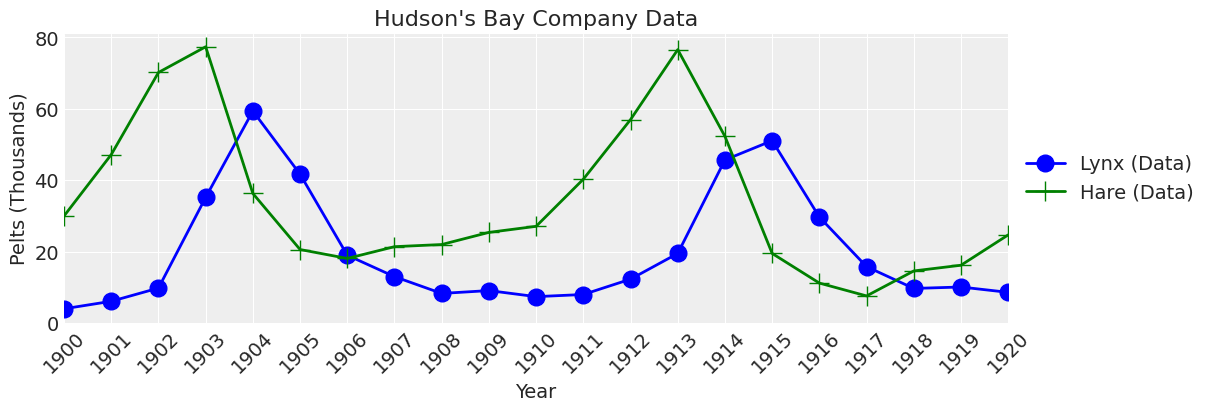
The Hudson’s Bay Company data#
The Lotka-Volterra predator prey model has been used to successfully explain the dynamics of natural populations of predators and prey, such as the lynx and snowshoe hare data of the Hudson’s Bay Company. Since the dataset is small, we will hand-enter the values.
# fmt: off
data = pd.DataFrame(dict(
year = np.arange(1900., 1921., 1),
lynx = np.array([4.0, 6.1, 9.8, 35.2, 59.4, 41.7, 19.0, 13.0, 8.3, 9.1, 7.4,
8.0, 12.3, 19.5, 45.7, 51.1, 29.7, 15.8, 9.7, 10.1, 8.6]),
hare = np.array([30.0, 47.2, 70.2, 77.4, 36.3, 20.6, 18.1, 21.4, 22.0, 25.4,
27.1, 40.3, 57.0, 76.6, 52.3, 19.5, 11.2, 7.6, 14.6, 16.2, 24.7])))
data.head()
# fmt: on
| year | lynx | hare | |
|---|---|---|---|
| 0 | 1900.0 | 4.0 | 30.0 |
| 1 | 1901.0 | 6.1 | 47.2 |
| 2 | 1902.0 | 9.8 | 70.2 |
| 3 | 1903.0 | 35.2 | 77.4 |
| 4 | 1904.0 | 59.4 | 36.3 |
# plot data function for reuse later
def plot_data(ax, lw=2, title="Hudson's Bay Company Data"):
ax.plot(data.year, data.lynx, color="b", lw=lw, marker="o", markersize=12, label="Lynx (Data)")
ax.plot(data.year, data.hare, color="g", lw=lw, marker="+", markersize=14, label="Hare (Data)")
ax.legend(fontsize=14, loc="center left", bbox_to_anchor=(1, 0.5))
ax.set_xlim([1900, 1920])
ax.set_ylim(0)
ax.set_xlabel("Year", fontsize=14)
ax.set_ylabel("Pelts (Thousands)", fontsize=14)
ax.set_xticks(data.year.astype(int))
ax.set_xticklabels(ax.get_xticks(), rotation=45)
ax.set_title(title, fontsize=16)
return ax
_, ax = plt.subplots(figsize=(12, 4))
plot_data(ax);
Problem Statement#
The purpose of this analysis is to estimate, with uncertainty, the parameters for the Lotka-Volterra model for the Hudson’s Bay Company data from 1900 to 1920.
Scipy odeint#
Here, we make a Python function that represents the right-hand-side of the ODE equations with the call signature needed for the odeint function. Note that Scipy’s solve_ivp could also be used, but the older odeint function was faster in speed tests and is therefore used in this notebook.
# define the right hand side of the ODE equations in the Scipy odeint signature
from numba import njit
@njit
def rhs(X, t, theta):
# unpack parameters
x, y = X
alpha, beta, gamma, delta, xt0, yt0 = theta
# equations
dx_dt = alpha * x - beta * x * y
dy_dt = -gamma * y + delta * x * y
return [dx_dt, dy_dt]
To get a feel for the model and make sure the equations are working correctly, let’s run the model once with reasonable values for \(\theta\) and plot the results.
# plot model function
def plot_model(
ax,
x_y,
time=np.arange(1900, 1921, 0.01),
alpha=1,
lw=3,
title="Hudson's Bay Company Data and\nExample Model Run",
):
ax.plot(time, x_y[:, 1], color="b", alpha=alpha, lw=lw, label="Lynx (Model)")
ax.plot(time, x_y[:, 0], color="g", alpha=alpha, lw=lw, label="Hare (Model)")
ax.legend(fontsize=14, loc="center left", bbox_to_anchor=(1, 0.5))
ax.set_title(title, fontsize=16)
return ax
# note theta = alpha, beta, gamma, delta, xt0, yt0
theta = np.array([0.52, 0.026, 0.84, 0.026, 34.0, 5.9])
time = np.arange(1900, 1921, 0.01)
# call Scipy's odeint function
x_y = odeint(func=rhs, y0=theta[-2:], t=time, args=(theta,))
# plot
_, ax = plt.subplots(figsize=(12, 4))
plot_data(ax, lw=0)
plot_model(ax, x_y);
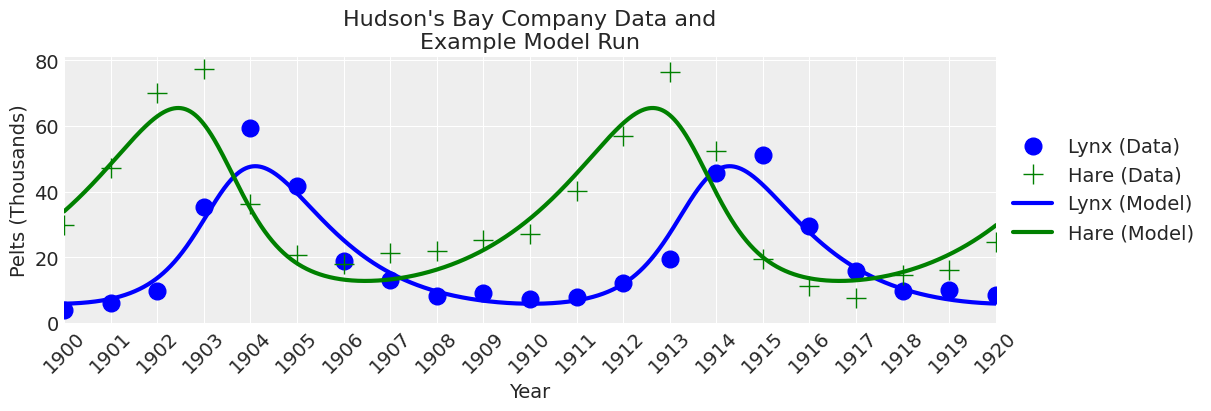
Looks like the odeint function is working as expected.
Least Squares Solution#
Now, we can solve the ODE using least squares. Make a function that calculates the residual error.
# function that calculates residuals based on a given theta
def ode_model_resid(theta):
return (
data[["hare", "lynx"]] - odeint(func=rhs, y0=theta[-2:], t=data.year, args=(theta,))
).values.flatten()
Feed the residual error function to the Scipy least_squares solver.
# calculate least squares using the Scipy solver
results = least_squares(ode_model_resid, x0=theta)
# put the results in a dataframe for presentation and convenience
df = pd.DataFrame()
parameter_names = ["alpha", "beta", "gamma", "delta", "h0", "l0"]
df["Parameter"] = parameter_names
df["Least Squares Solution"] = results.x
df.round(2)
| Parameter | Least Squares Solution | |
|---|---|---|
| 0 | alpha | 0.48 |
| 1 | beta | 0.02 |
| 2 | gamma | 0.93 |
| 3 | delta | 0.03 |
| 4 | h0 | 34.91 |
| 5 | l0 | 3.86 |
Plot
time = np.arange(1900, 1921, 0.01)
theta = results.x
x_y = odeint(func=rhs, y0=theta[-2:], t=time, args=(theta,))
fig, ax = plt.subplots(figsize=(12, 4))
plot_data(ax, lw=0)
plot_model(ax, x_y, title="Least Squares Solution");
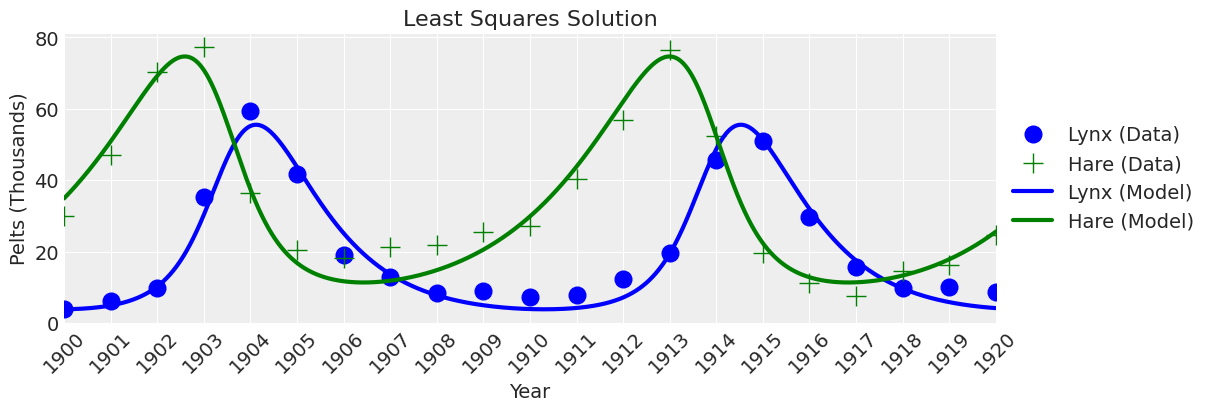
Looks right. If we didn’t care about uncertainty, then we would be done. But we do care about uncertainty, so let’s move on to Bayesian inference.
PyMC Model Specification for Gradient-Free Bayesian Inference#
Like other Numpy or Scipy-based functions, the scipy.integrate.odeint function cannot be used directly in a PyMC model because PyMC needs to know the variable input and output types to compile. Therefore, we use a Pytensor wrapper to give the variable types to PyMC. Then the function can be used in PyMC in conjunction with gradient-free samplers.
Convert Python Function to a Pytensor Operator using @as_op decorator#
We tell PyMC the input variable types and the output variable types using the @as_op decorator. odeint returns Numpy arrays, but we tell PyMC that they are Pytensor double float tensors for this purpose.
# decorator with input and output types a Pytensor double float tensors
@as_op(itypes=[pt.dvector], otypes=[pt.dmatrix])
def pytensor_forward_model_matrix(theta):
return odeint(func=rhs, y0=theta[-2:], t=data.year, args=(theta,))
PyMC Model#
Now, we can specify the PyMC model using the ode solver! For priors, we will use the results from the least squares calculation (results.x) to assign priors that start in the right range. These are empirically derived weakly informative priors. We also make them positive-only for this problem.
We will use a normal likelihood on untransformed data (i.e., not log transformed) to best fit the peaks of the data.
theta = results.x # least squares solution used to inform the priors
with pm.Model() as model:
# Priors
alpha = pm.TruncatedNormal("alpha", mu=theta[0], sigma=0.1, lower=0, initval=theta[0])
beta = pm.TruncatedNormal("beta", mu=theta[1], sigma=0.01, lower=0, initval=theta[1])
gamma = pm.TruncatedNormal("gamma", mu=theta[2], sigma=0.1, lower=0, initval=theta[2])
delta = pm.TruncatedNormal("delta", mu=theta[3], sigma=0.01, lower=0, initval=theta[3])
xt0 = pm.TruncatedNormal("xto", mu=theta[4], sigma=1, lower=0, initval=theta[4])
yt0 = pm.TruncatedNormal("yto", mu=theta[5], sigma=1, lower=0, initval=theta[5])
sigma = pm.HalfNormal("sigma", 10)
# Ode solution function
ode_solution = pytensor_forward_model_matrix(
pm.math.stack([alpha, beta, gamma, delta, xt0, yt0])
)
# Likelihood
pm.Normal("Y_obs", mu=ode_solution, sigma=sigma, observed=data[["hare", "lynx"]].values)
pm.model_to_graphviz(model=model)

Plotting Functions#
A couple of plotting functions that we will reuse below.
def plot_model_trace(ax, trace_df, row_idx, lw=1, alpha=0.2):
cols = ["alpha", "beta", "gamma", "delta", "xto", "yto"]
row = trace_df.iloc[row_idx, :][cols].values
# alpha, beta, gamma, delta, Xt0, Yt0
time = np.arange(1900, 1921, 0.01)
theta = row
x_y = odeint(func=rhs, y0=theta[-2:], t=time, args=(theta,))
plot_model(ax, x_y, time=time, lw=lw, alpha=alpha);
def plot_inference(
ax,
trace,
num_samples=25,
title="Hudson's Bay Company Data and\nInference Model Runs",
plot_model_kwargs=dict(lw=1, alpha=0.2),
):
trace_df = az.extract(trace, num_samples=num_samples).to_dataframe()
plot_data(ax, lw=0)
for row_idx in range(num_samples):
plot_model_trace(ax, trace_df, row_idx, **plot_model_kwargs)
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles[:2], labels[:2], loc="center left", bbox_to_anchor=(1, 0.5))
ax.set_title(title, fontsize=16)
Gradient-Free Sampler Options#
Having good gradient free samplers can open up the models that can be fit within PyMC. There are five options for gradient-free samplers in PyMC that are applicable to this problem:
Slice- the default gradient-free samplerDEMetropolisZ- a differential evolution Metropolis sampler that uses the past to inform sampling jumpsDEMetropolis- a differential evolution Metropolis samplerMetropolis- the vanilla Metropolis samplerSMC- Sequential Monte Carlo
Let’s give them a shot.
A few notes on running these inferences. For each sampler, the number of tuning steps and draws have been reduced to run the inference in a reasonable amount of time (on the order of minutes). This is not a sufficient number of draws to get a good inferences, in some cases, but it works for demonstration purposes. In addition, multicore processing was not working for the Pytensor op function on all machines, so inference is performed on one core.
Slice Sampler#
# Variable list to give to the sample step parameter
vars_list = list(model.values_to_rvs.keys())[:-1]
# Specify the sampler
sampler = "Slice Sampler"
tune = draws = 2000
# Inference!
with model:
trace_slice = pm.sample(step=[pm.Slice(vars_list)], tune=tune, draws=draws)
trace = trace_slice
az.summary(trace)
Multiprocess sampling (4 chains in 4 jobs)
CompoundStep
>Slice: [alpha]
>Slice: [beta]
>Slice: [gamma]
>Slice: [delta]
>Slice: [xto]
>Slice: [yto]
>Slice: [sigma]
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 120 seconds.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | 0.478 | 0.025 | 0.433 | 0.526 | 0.002 | 0.002 | 115.0 | 254.0 | 1.04 |
| beta | 0.025 | 0.001 | 0.022 | 0.027 | 0.000 | 0.000 | 253.0 | 497.0 | 1.01 |
| gamma | 0.937 | 0.054 | 0.835 | 1.039 | 0.005 | 0.004 | 109.0 | 241.0 | 1.04 |
| delta | 0.028 | 0.002 | 0.025 | 0.031 | 0.000 | 0.000 | 109.0 | 242.0 | 1.05 |
| xto | 34.945 | 0.823 | 33.386 | 36.472 | 0.023 | 0.016 | 1269.0 | 2646.0 | 1.00 |
| yto | 3.837 | 0.476 | 2.958 | 4.730 | 0.036 | 0.026 | 169.0 | 491.0 | 1.03 |
| sigma | 4.111 | 0.487 | 3.263 | 5.038 | 0.007 | 0.005 | 5141.0 | 5579.0 | 1.00 |
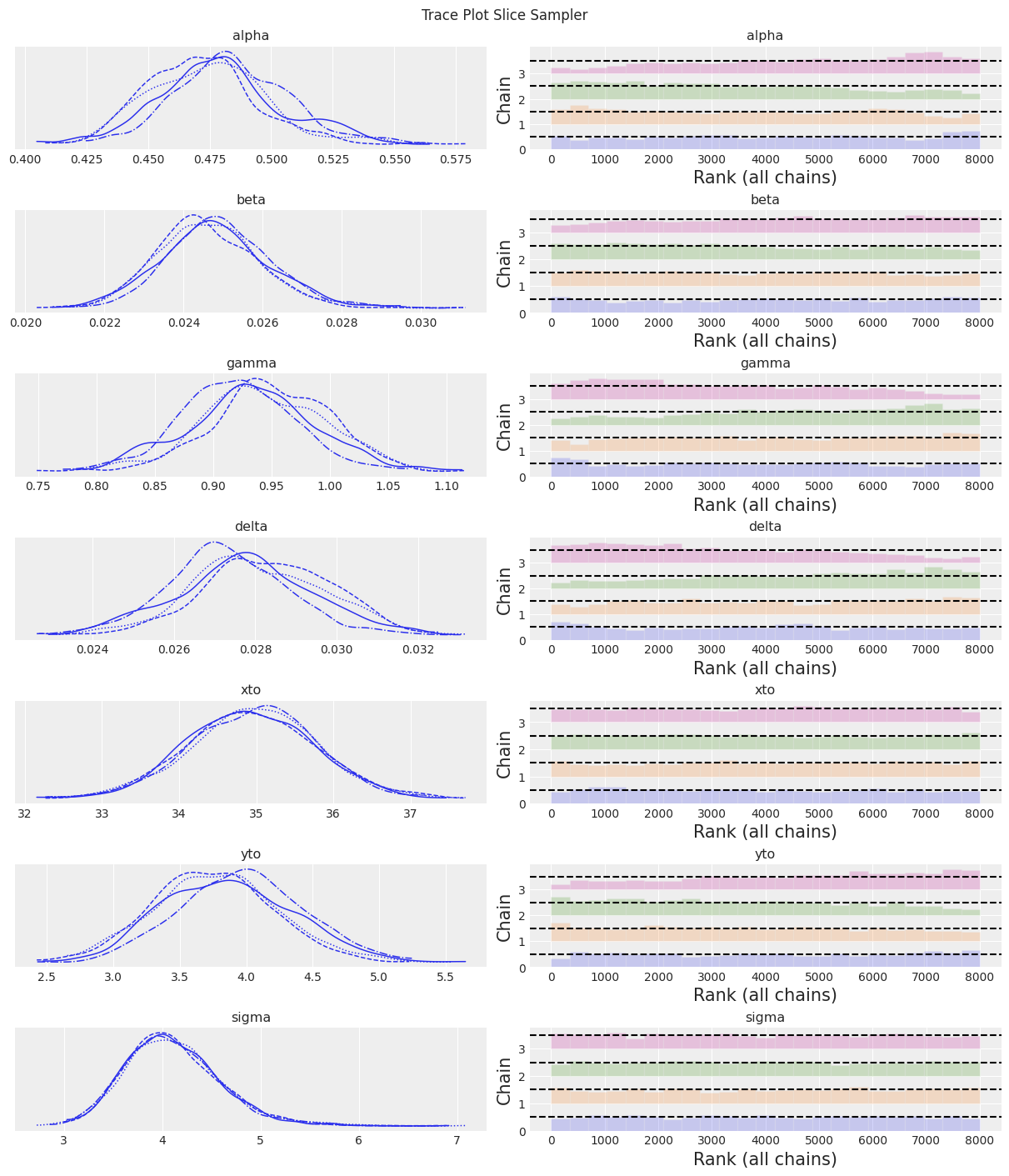
az.plot_trace(trace, kind="rank_bars")
plt.suptitle(f"Trace Plot {sampler}");
fig, ax = plt.subplots(figsize=(12, 4))
plot_inference(ax, trace, title=f"Data and Inference Model Runs\n{sampler} Sampler");
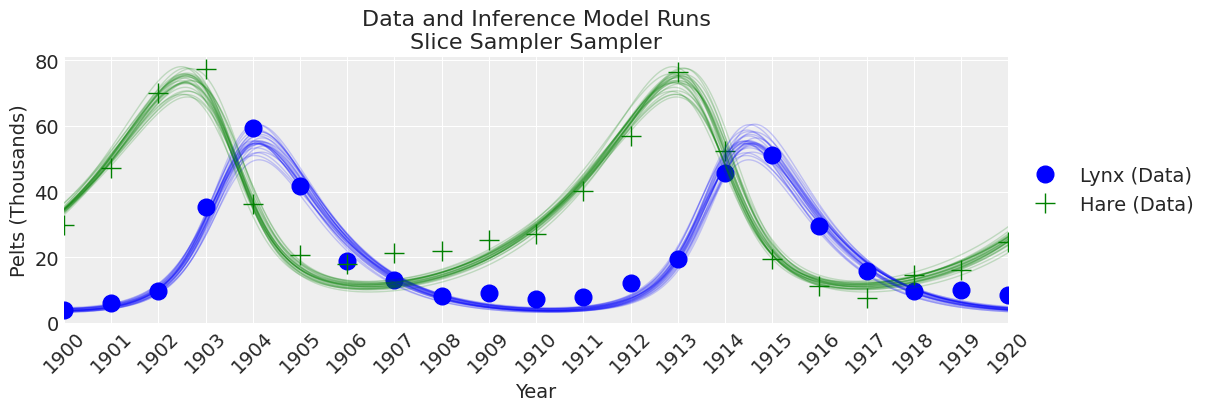
Notes:
The Slice sampler was slow and resulted in a low effective sample size. Despite this, the results are starting to look reasonable!
DE MetropolisZ Sampler#
sampler = "DEMetropolisZ"
tune = draws = 5000
with model:
trace_DEMZ = pm.sample(step=[pm.DEMetropolisZ(vars_list)], tune=tune, draws=draws)
trace = trace_DEMZ
az.summary(trace)
Multiprocess sampling (4 chains in 4 jobs)
DEMetropolisZ: [alpha, beta, gamma, delta, xto, yto, sigma]
Sampling 4 chains for 5_000 tune and 5_000 draw iterations (20_000 + 20_000 draws total) took 17 seconds.
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | 0.482 | 0.024 | 0.434 | 0.523 | 0.001 | 0.001 | 747.0 | 1341.0 | 1.01 |
| beta | 0.025 | 0.001 | 0.022 | 0.028 | 0.000 | 0.000 | 821.0 | 1415.0 | 1.00 |
| gamma | 0.927 | 0.051 | 0.834 | 1.023 | 0.002 | 0.001 | 896.0 | 1547.0 | 1.01 |
| delta | 0.028 | 0.002 | 0.025 | 0.031 | 0.000 | 0.000 | 783.0 | 1432.0 | 1.01 |
| xto | 34.938 | 0.847 | 33.314 | 36.479 | 0.029 | 0.021 | 855.0 | 1201.0 | 1.00 |
| yto | 3.887 | 0.473 | 2.983 | 4.724 | 0.017 | 0.012 | 777.0 | 1156.0 | 1.01 |
| sigma | 4.129 | 0.477 | 3.266 | 5.029 | 0.017 | 0.012 | 799.0 | 1466.0 | 1.00 |
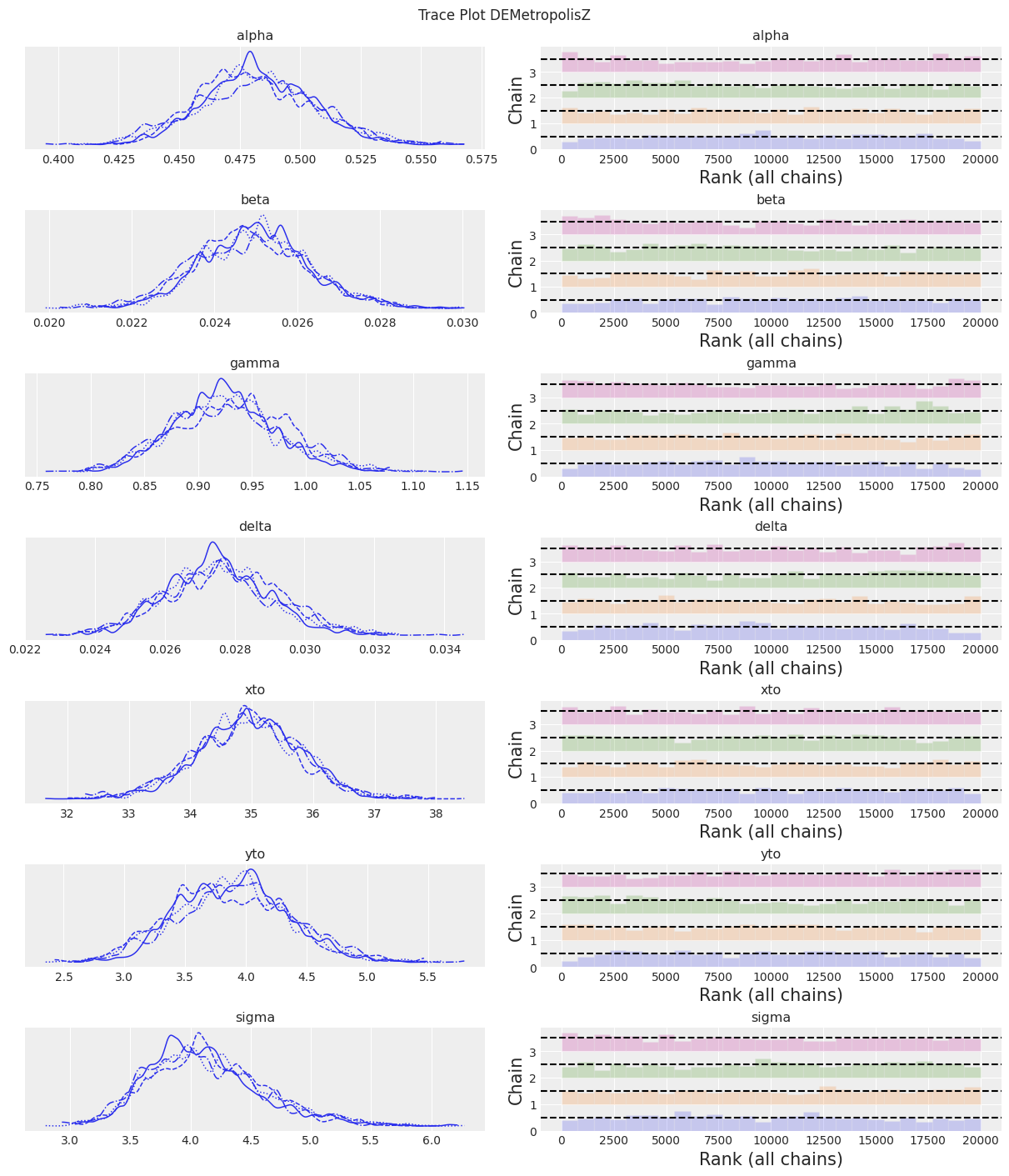
az.plot_trace(trace, kind="rank_bars")
plt.suptitle(f"Trace Plot {sampler}");
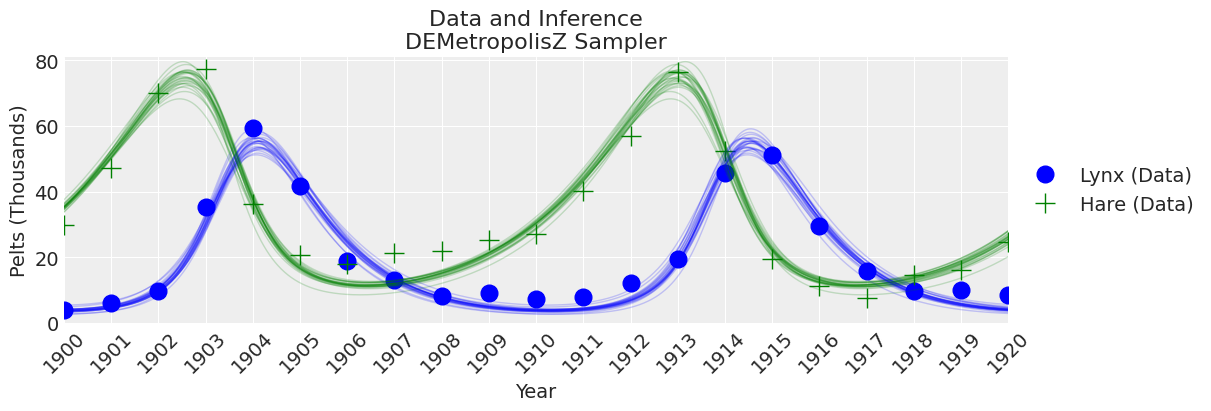
fig, ax = plt.subplots(figsize=(12, 4))
plot_inference(ax, trace, title=f"Data and Inference\n{sampler} Sampler")
Notes:
DEMetropolisZ sampled much quicker than the Slice sampler and therefore had a higher ESS per minute spent sampling. The parameter estimates are similar. A “final” inference would still need to beef up the number of samples.
DEMetropolis Sampler#
In these experiments, DEMetropolis sampler was not accepting tune and requiring chains to be at least 8. We set draws at 5000, lower number like 3000 produce bad mixing.
sampler = "DEMetropolis"
chains = 8
draws = 6000
with model:
trace_DEM = pm.sample(step=[pm.DEMetropolis(vars_list)], draws=draws, chains=chains)
trace = trace_DEM
az.summary(trace)
Population sampling (8 chains)
DEMetropolis: [alpha, beta, gamma, delta, xto, yto, sigma]
Attempting to parallelize chains to all cores. You can turn this off with `pm.sample(cores=1)`.
Sampling 8 chains for 1_000 tune and 6_000 draw iterations (8_000 + 48_000 draws total) took 40 seconds.
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | 0.483 | 0.021 | 0.443 | 0.520 | 0.000 | 0.000 | 1820.0 | 2647.0 | 1.00 |
| beta | 0.025 | 0.001 | 0.023 | 0.027 | 0.000 | 0.000 | 1891.0 | 3225.0 | 1.00 |
| gamma | 0.924 | 0.045 | 0.837 | 1.008 | 0.001 | 0.001 | 1818.0 | 2877.0 | 1.00 |
| delta | 0.027 | 0.001 | 0.025 | 0.030 | 0.000 | 0.000 | 1628.0 | 2469.0 | 1.00 |
| xto | 34.890 | 0.707 | 33.523 | 36.176 | 0.018 | 0.013 | 1484.0 | 2862.0 | 1.01 |
| yto | 3.897 | 0.403 | 3.126 | 4.644 | 0.010 | 0.007 | 1756.0 | 2468.0 | 1.00 |
| sigma | 4.042 | 0.405 | 3.335 | 4.836 | 0.011 | 0.008 | 1437.0 | 2902.0 | 1.00 |
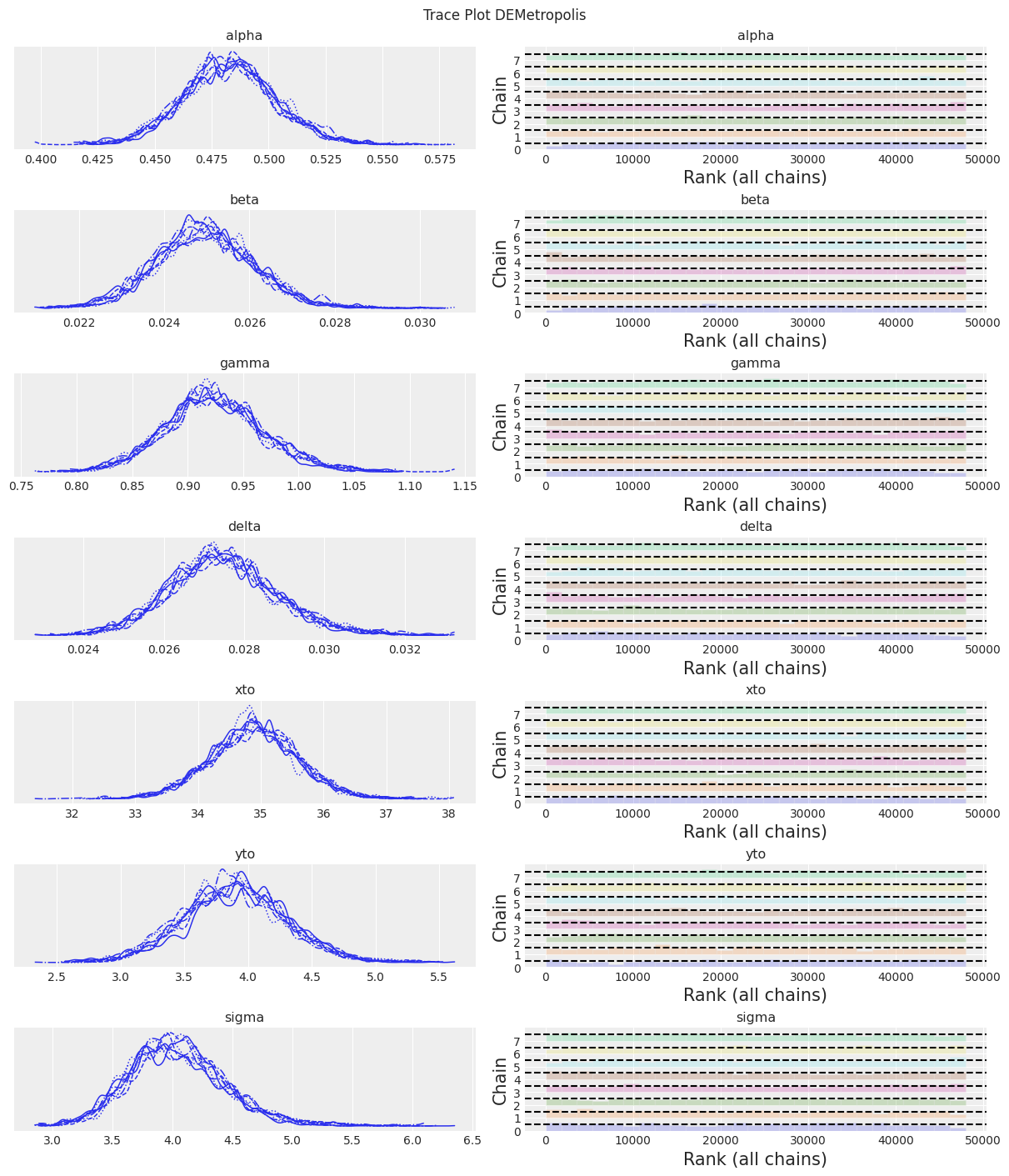
az.plot_trace(trace, kind="rank_bars")
plt.suptitle(f"Trace Plot {sampler}");
fig, ax = plt.subplots(figsize=(12, 4))
plot_inference(ax, trace, title=f"Data and Inference Model Runs\n{sampler} Sampler");
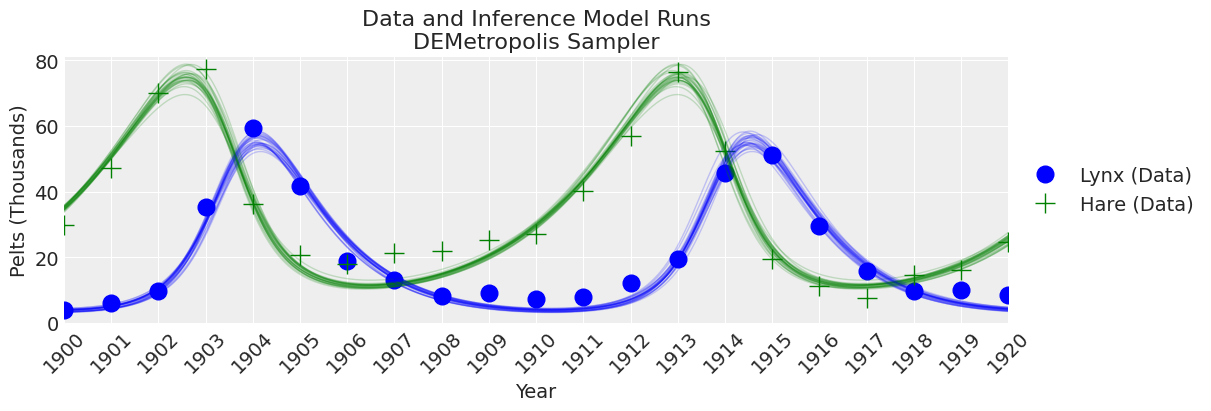
Notes:
KDEs looks too wiggly, but ESS is high R-hat is good and rank_plots also look good
Metropolis Sampler#
sampler = "Metropolis"
tune = draws = 5000
with model:
trace_M = pm.sample(step=[pm.Metropolis(vars_list)], tune=tune, draws=draws)
trace = trace_M
az.summary(trace)
Multiprocess sampling (4 chains in 4 jobs)
CompoundStep
>Metropolis: [alpha]
>Metropolis: [beta]
>Metropolis: [gamma]
>Metropolis: [delta]
>Metropolis: [xto]
>Metropolis: [yto]
>Metropolis: [sigma]
/home/osvaldo/anaconda3/envs/pymc/lib/python3.10/site-packages/scipy/integrate/_odepack_py.py:248: ODEintWarning: Excess work done on this call (perhaps wrong Dfun type). Run with full_output = 1 to get quantitative information.
warnings.warn(warning_msg, ODEintWarning)
/home/osvaldo/anaconda3/envs/pymc/lib/python3.10/site-packages/scipy/integrate/_odepack_py.py:248: ODEintWarning: Excess work done on this call (perhaps wrong Dfun type). Run with full_output = 1 to get quantitative information.
warnings.warn(warning_msg, ODEintWarning)
Sampling 4 chains for 5_000 tune and 5_000 draw iterations (20_000 + 20_000 draws total) took 106 seconds.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | 0.481 | 0.024 | 0.437 | 0.523 | 0.004 | 0.003 | 44.0 | 112.0 | 1.10 |
| beta | 0.025 | 0.001 | 0.023 | 0.027 | 0.000 | 0.000 | 123.0 | 569.0 | 1.05 |
| gamma | 0.928 | 0.052 | 0.836 | 1.022 | 0.008 | 0.005 | 44.0 | 93.0 | 1.10 |
| delta | 0.028 | 0.002 | 0.025 | 0.031 | 0.000 | 0.000 | 47.0 | 113.0 | 1.09 |
| xto | 34.928 | 0.833 | 33.396 | 36.513 | 0.029 | 0.021 | 808.0 | 1128.0 | 1.00 |
| yto | 3.892 | 0.492 | 3.026 | 4.878 | 0.055 | 0.039 | 81.0 | 307.0 | 1.04 |
| sigma | 4.116 | 0.496 | 3.272 | 5.076 | 0.009 | 0.007 | 2870.0 | 3372.0 | 1.00 |
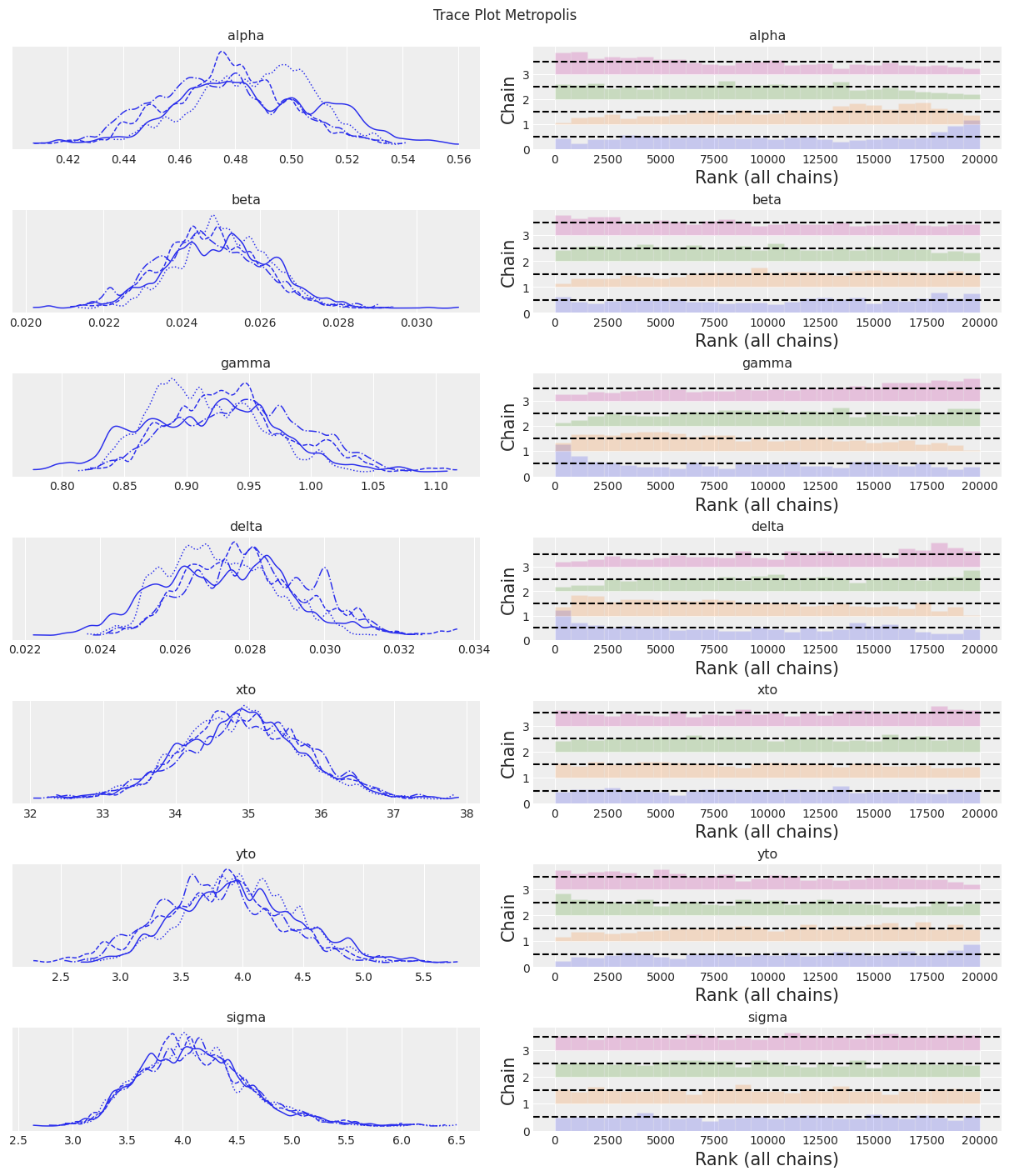
az.plot_trace(trace, kind="rank_bars")
plt.suptitle(f"Trace Plot {sampler}");
fig, ax = plt.subplots(figsize=(12, 4))
plot_inference(ax, trace, title=f"Data and Inference Model Runs\n{sampler} Sampler");
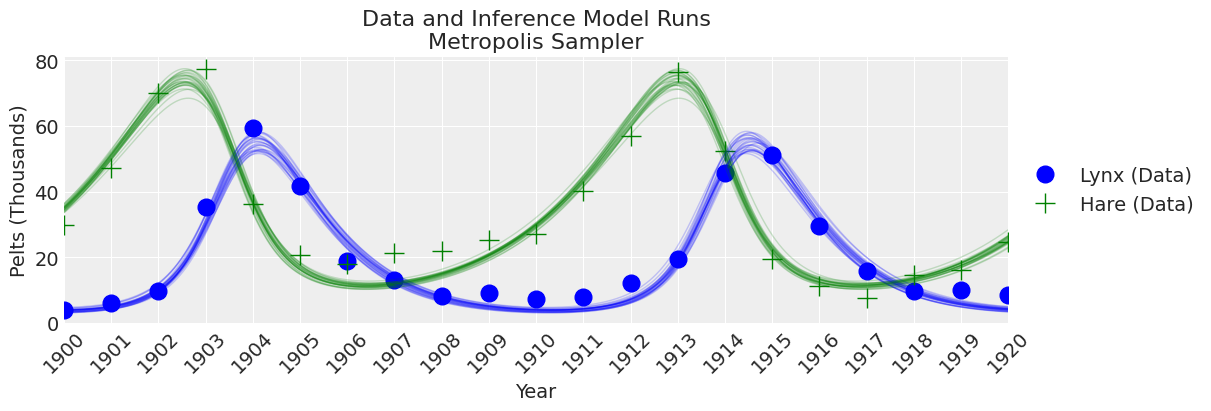
Notes:
The old-school Metropolis sampler is less reliable and slower than the DEMetroplis samplers. Not recommended.
SMC Sampler#
The Sequential Monte Carlo (SMC) sampler can be used to sample a regular Bayesian model or to run model without a likelihood (Approximate Bayesian Computation). Let’s try first with a regular model,
SMC with a Likelihood Function#
sampler = "SMC with Likelihood"
draws = 2000
with model:
trace_SMC_like = pm.sample_smc(draws)
trace = trace_SMC_like
az.summary(trace)
Initializing SMC sampler...
Sampling 4 chains in 4 jobs
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | 0.482 | 0.025 | 0.436 | 0.527 | 0.000 | 0.000 | 8093.0 | 7636.0 | 1.0 |
| beta | 0.025 | 0.001 | 0.022 | 0.027 | 0.000 | 0.000 | 8090.0 | 7582.0 | 1.0 |
| gamma | 0.927 | 0.053 | 0.826 | 1.023 | 0.001 | 0.000 | 8064.0 | 8142.0 | 1.0 |
| delta | 0.028 | 0.002 | 0.025 | 0.031 | 0.000 | 0.000 | 8028.0 | 8016.0 | 1.0 |
| xto | 34.893 | 0.843 | 33.324 | 36.500 | 0.009 | 0.007 | 8060.0 | 7716.0 | 1.0 |
| yto | 3.889 | 0.480 | 2.997 | 4.796 | 0.005 | 0.004 | 7773.0 | 7884.0 | 1.0 |
| sigma | 4.123 | 0.497 | 3.243 | 5.057 | 0.006 | 0.004 | 8169.0 | 7971.0 | 1.0 |
trace.sample_stats._t_sampling
64.09551501274109
az.plot_trace(trace, kind="rank_bars")
plt.suptitle(f"Trace Plot {sampler}");
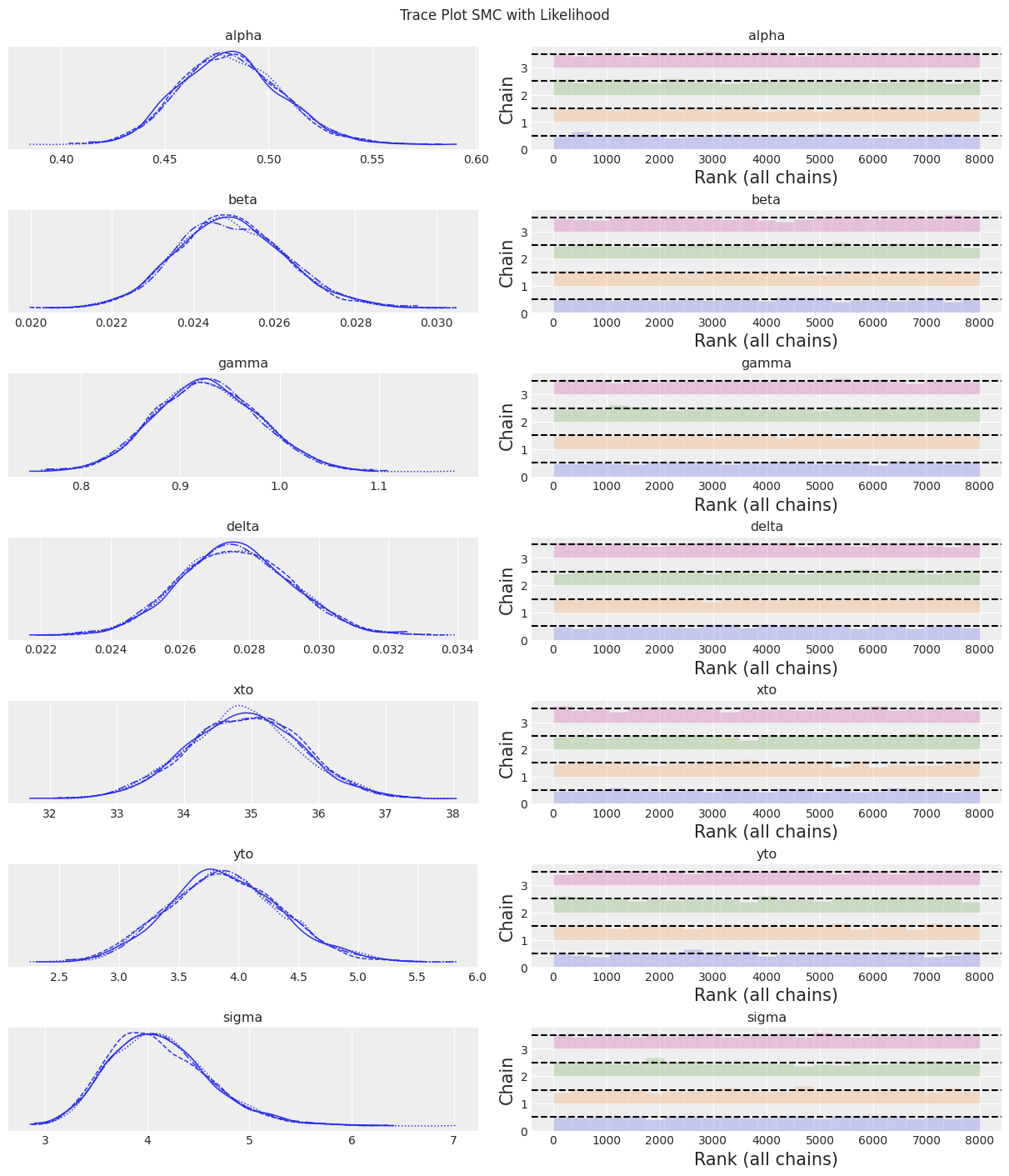
fig, ax = plt.subplots(figsize=(12, 4))
plot_inference(ax, trace, title=f"Data and Inference Model Runs\n{sampler} Sampler");
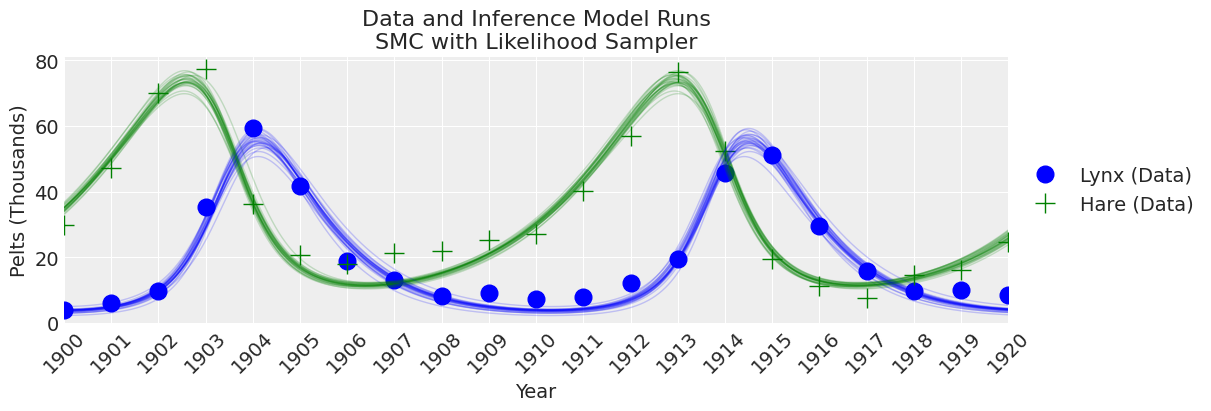
Notes:
At this number of samples and tuning scheme, the SMC algorithm results in wider uncertainty bounds compared with the other samplers.
SMC Using pm.Simulator Epsilon=1#
As outlined in the SMC tutorial on PyMC.io, the SMC sampler can be used for Approximate Bayesian Computation, i.e. we can use a pm.Simulator instead of a explicit likelihood. Here is a rewrite of the PyMC - odeint model for SMC-ABC.
The simulator function needs to have the correct signature (e.g., accept an rng argument first).
# simulator function based on the signature rng, parameters, size.
def simulator_forward_model(rng, alpha, beta, gamma, delta, xt0, yt0, sigma, size=None):
theta = alpha, beta, gamma, delta, xt0, yt0
mu = odeint(func=rhs, y0=theta[-2:], t=data.year, args=(theta,))
return rng.normal(mu, sigma)
Here is the model with the simulator function. Instead of a explicit likelihood function, the simulator uses distance metric (defaults to gaussian) between the simulated and observed values. When using a simulator we also need to specify epsilon, that is a tolerance value for the discrepancy between simulated and observed values. If epsilon is too low, SMC will not be able to move away from the initial values or a few values. We can easily see this with az.plot_trace. If epsilon is too high, the posterior will virtually be the prior. So
with pm.Model() as model:
# Specify prior distributions for model parameters
alpha = pm.TruncatedNormal("alpha", mu=theta[0], sigma=0.1, lower=0, initval=theta[0])
beta = pm.TruncatedNormal("beta", mu=theta[1], sigma=0.01, lower=0, initval=theta[1])
gamma = pm.TruncatedNormal("gamma", mu=theta[2], sigma=0.1, lower=0, initval=theta[2])
delta = pm.TruncatedNormal("delta", mu=theta[3], sigma=0.01, lower=0, initval=theta[3])
xt0 = pm.TruncatedNormal("xto", mu=theta[4], sigma=1, lower=0, initval=theta[4])
yt0 = pm.TruncatedNormal("yto", mu=theta[5], sigma=1, lower=0, initval=theta[5])
sigma = pm.HalfNormal("sigma", 10)
# ode_solution
pm.Simulator(
"Y_obs",
simulator_forward_model,
params=(alpha, beta, gamma, delta, xt0, yt0, sigma),
epsilon=1,
observed=data[["hare", "lynx"]].values,
)
Inference. Note the progressbar was throwing an error so it is turned off.
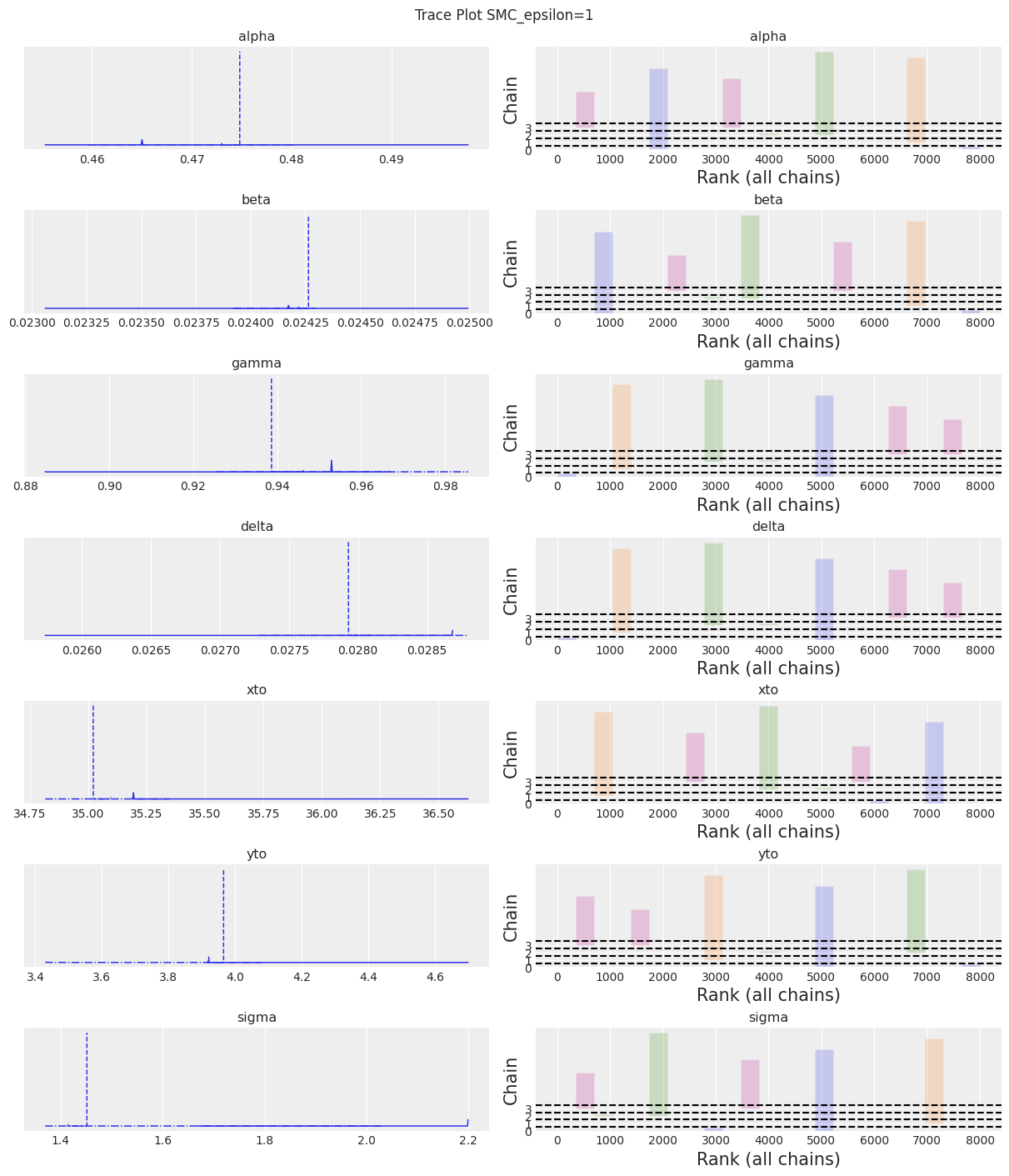
sampler = "SMC_epsilon=1"
draws = 2000
with model:
trace_SMC_e1 = pm.sample_smc(draws=draws, progressbar=False)
trace = trace_SMC_e1
az.summary(trace)
Initializing SMC sampler...
Sampling 4 chains in 4 jobs
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | 0.474 | 0.012 | 0.460 | 0.492 | 0.006 | 0.004 | 5.0 | 5.0 | 3.41 |
| beta | 0.024 | 0.000 | 0.024 | 0.025 | 0.000 | 0.000 | 5.0 | 4.0 | 4.01 |
| gamma | 0.946 | 0.023 | 0.918 | 0.986 | 0.011 | 0.008 | 4.0 | 4.0 | 3.43 |
| delta | 0.028 | 0.001 | 0.028 | 0.029 | 0.000 | 0.000 | 4.0 | 4.0 | 4.19 |
| xto | 34.734 | 0.582 | 33.747 | 35.194 | 0.289 | 0.221 | 4.0 | 4.0 | 7.21 |
| yto | 3.814 | 0.214 | 3.429 | 3.966 | 0.101 | 0.077 | 4.0 | 5.0 | 3.93 |
| sigma | 1.899 | 0.357 | 1.369 | 2.206 | 0.173 | 0.132 | 4.0 | 8000.0 | 4.65 |
az.plot_trace(trace, kind="rank_bars")
plt.suptitle(f"Trace Plot {sampler}");
/home/osvaldo/proyectos/00_BM/arviz/arviz/stats/density_utils.py:487: UserWarning: Your data appears to have a single value or no finite values
warnings.warn("Your data appears to have a single value or no finite values")
fig, ax = plt.subplots(figsize=(12, 4))
plot_inference(ax, trace, title=f"Data and Inference Model Runs\n{sampler} Sampler");
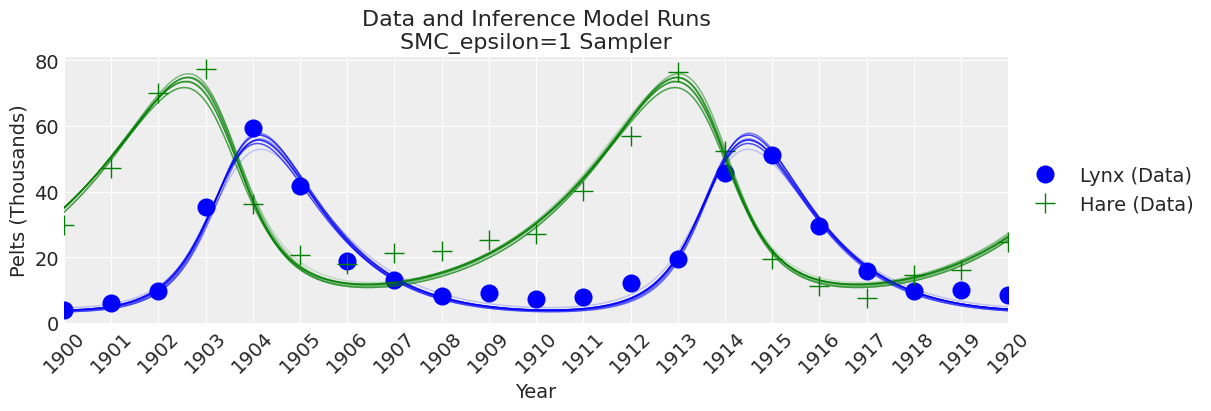
Notes:
We can see that if epsilon is too low plot_trace will clearly show it.
SMC with Epsilon = 10#
with pm.Model() as model:
# Specify prior distributions for model parameters
alpha = pm.TruncatedNormal("alpha", mu=theta[0], sigma=0.1, lower=0, initval=theta[0])
beta = pm.TruncatedNormal("beta", mu=theta[1], sigma=0.01, lower=0, initval=theta[1])
gamma = pm.TruncatedNormal("gamma", mu=theta[2], sigma=0.1, lower=0, initval=theta[2])
delta = pm.TruncatedNormal("delta", mu=theta[3], sigma=0.01, lower=0, initval=theta[3])
xt0 = pm.TruncatedNormal("xto", mu=theta[4], sigma=1, lower=0, initval=theta[4])
yt0 = pm.TruncatedNormal("yto", mu=theta[5], sigma=1, lower=0, initval=theta[5])
sigma = pm.HalfNormal("sigma", 10)
# ode_solution
pm.Simulator(
"Y_obs",
simulator_forward_model,
params=(alpha, beta, gamma, delta, xt0, yt0, sigma),
epsilon=10,
observed=data[["hare", "lynx"]].values,
)
sampler = "SMC epsilon=10"
draws = 2000
with model:
trace_SMC_e10 = pm.sample_smc(draws=draws)
trace = trace_SMC_e10
az.summary(trace)
Initializing SMC sampler...
Sampling 4 chains in 4 jobs
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | 0.483 | 0.035 | 0.416 | 0.548 | 0.000 | 0.000 | 7612.0 | 7414.0 | 1.0 |
| beta | 0.025 | 0.003 | 0.020 | 0.030 | 0.000 | 0.000 | 7222.0 | 7768.0 | 1.0 |
| gamma | 0.927 | 0.072 | 0.795 | 1.063 | 0.001 | 0.001 | 7710.0 | 7361.0 | 1.0 |
| delta | 0.028 | 0.002 | 0.023 | 0.032 | 0.000 | 0.000 | 7782.0 | 7565.0 | 1.0 |
| xto | 34.888 | 0.965 | 33.145 | 36.781 | 0.011 | 0.008 | 7921.0 | 7521.0 | 1.0 |
| yto | 3.902 | 0.723 | 2.594 | 5.319 | 0.008 | 0.006 | 7993.0 | 7835.0 | 1.0 |
| sigma | 1.450 | 1.080 | 0.024 | 3.409 | 0.013 | 0.009 | 7490.0 | 7172.0 | 1.0 |
az.plot_trace(trace, kind="rank_bars")
plt.suptitle(f"Trace Plot {sampler}");
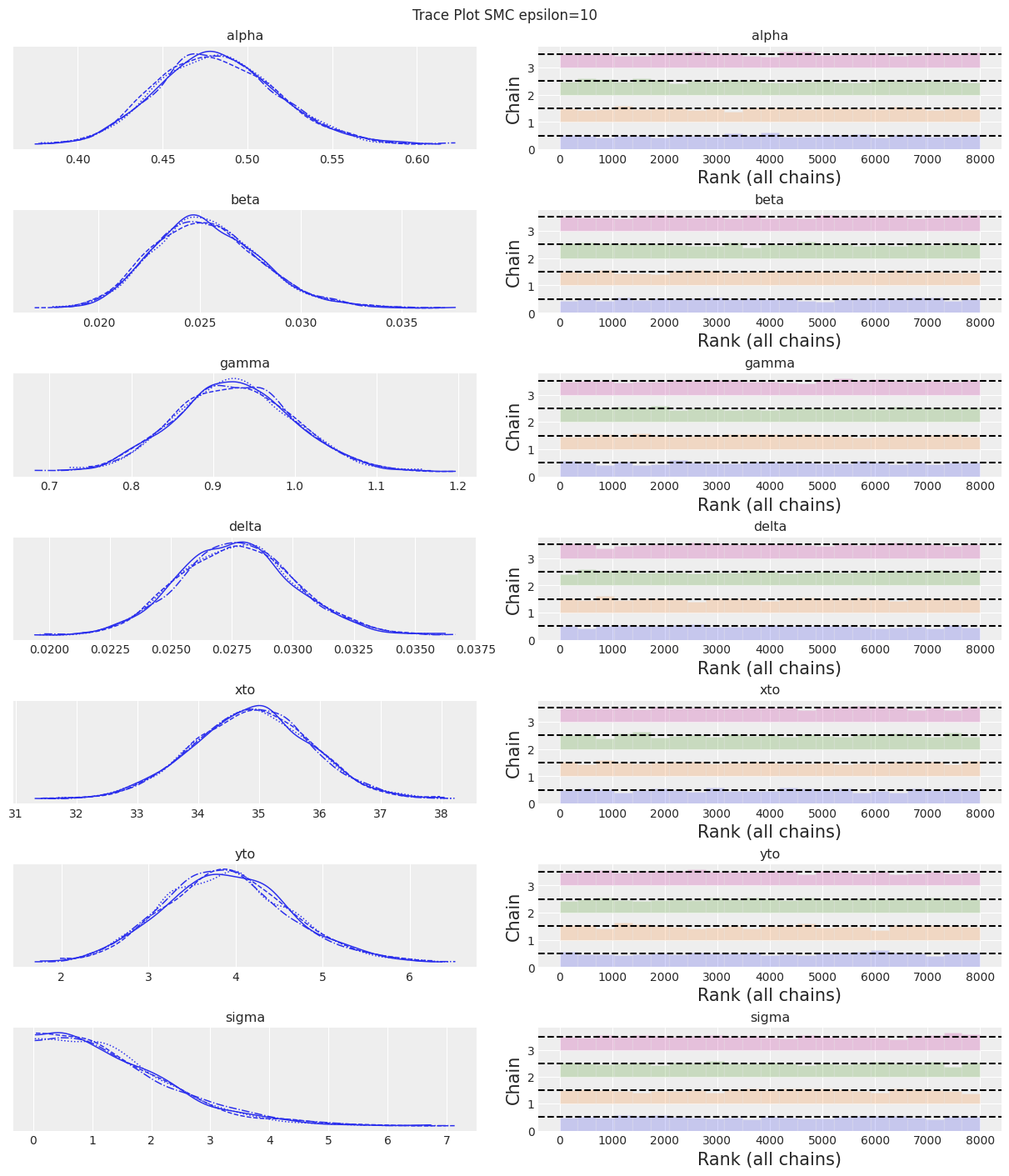
fig, ax = plt.subplots(figsize=(12, 4))
plot_inference(ax, trace, title=f"Data and Inference Model Runs\n{sampler} Sampler");
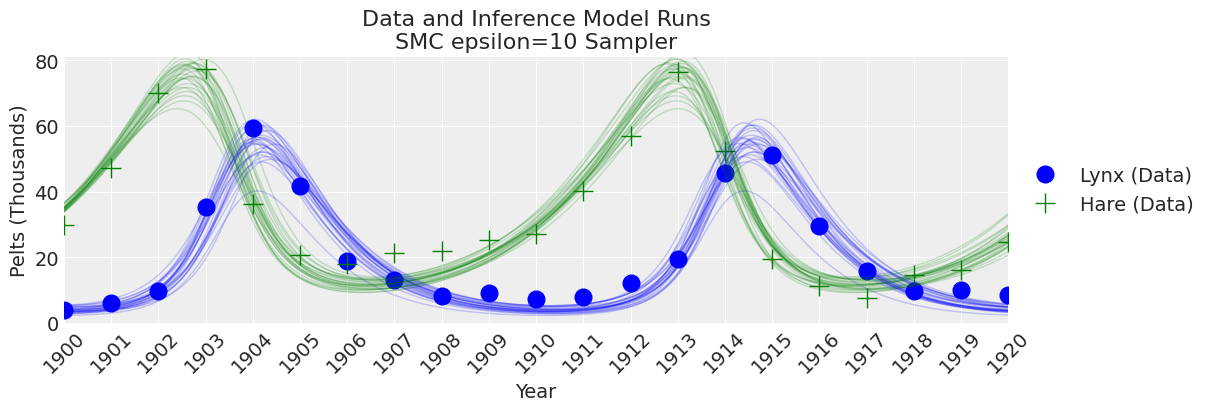
Notes:
Now that we set a larger value for epsilon we can see that the SMC sampler (plus simulator) provides good results. Choosing a value for epsilon will always involve some trial and error. So, what to do in practice? As epsilon is the scale of the distance function. If you don’t have any idea of how much error do you expected to get between simulated and observed values then a rule of thumb for picking an initial guess for epsilon is to use a number smaller than the standard deviation of the observed data, how much smaller maybe one order of magnitude or so.
Posterior Correlations#
As an aside, it is worth pointing out that the posterior parameter space is a difficult geometry for sampling.
az.plot_pair(trace_DEM, figsize=(8, 6), scatter_kwargs=dict(alpha=0.01), marginals=True)
plt.suptitle("Pair Plot Showing Posterior Correlations", size=18);
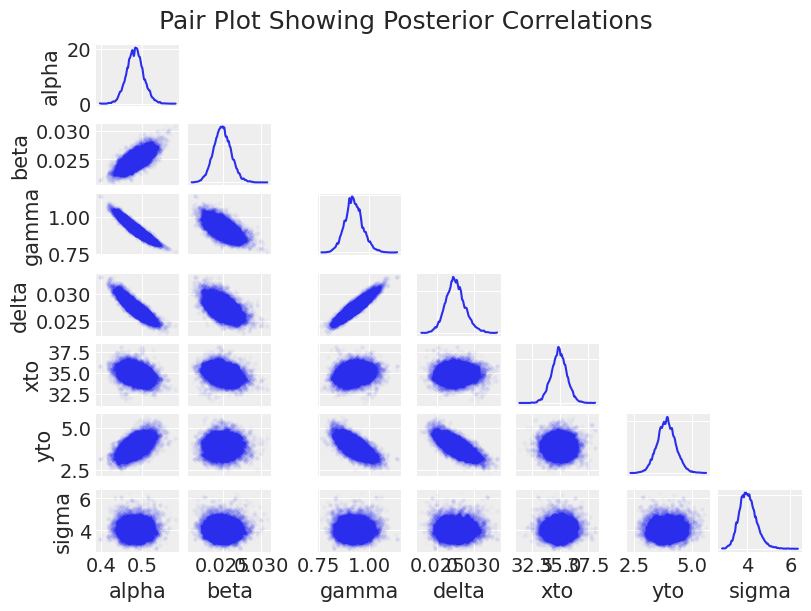
The major observation here is that the posterior shape is pretty difficult for a sampler to handle, with positive correlations, negative correlations, crecent-shapes, and large variations in scale. This contributes to the slow sampling (in addition to the computational overhead in solving the ODE thousands of times). This is also fun to look at for understanding how the model parameters impact each other.
Bayesian Inference with Gradients#
NUTS, the PyMC default sampler can only be used if gradients are supplied to the sampler. In this section, we will solve the system of ODEs within PyMC in two different ways that supply the sampler with gradients. The first is the built-in pymc.ode.DifferentialEquation solver, and the second is to forward simulate using pytensor.scan, which allows looping. Note that there may be other better and faster ways to perform Bayesian inference with ODEs using gradients, such as the sunode project, and diffrax, which relies on JAX.
PyMC ODE Module#
Pymc.ode uses scipy.odeint under the hood to estimate a solution and then estimate the gradient through finite differences.
The pymc.ode API is similar to scipy.odeint. The right-hand-side equations are put in a function and written as if y and p are vectors, as follows. (Even when your model has one state and/or one parameter, you should explicitly write y[0] and/or p[0].)
def rhs_pymcode(y, t, p):
dX_dt = p[0] * y[0] - p[1] * y[0] * y[1]
dY_dt = -p[2] * y[1] + p[3] * y[0] * y[1]
return [dX_dt, dY_dt]
DifferentialEquation takes as arguments:
func: A function specifying the differential equation (i.e. \(f(\mathbf{y},t,\mathbf{p})\)),times: An array of times at which data was observed,n_states: The dimension of \(f(\mathbf{y},t,\mathbf{p})\) (number of output parameters),n_theta: The dimension of \(\mathbf{p}\) (number of input parameters),t0: Optional time to which the initial condition belongs,
as follows:
ode_model = DifferentialEquation(
func=rhs_pymcode, times=data.year.values, n_states=2, n_theta=4, t0=data.year.values[0]
)
Once the ODE is specified, we can use it in our PyMC model.
Inference with NUTS#
pymc.ode is quite slow, so for demonstration purposes, we will only draw a few samples.
with pm.Model() as model:
# Priors
alpha = pm.TruncatedNormal("alpha", mu=theta[0], sigma=0.1, lower=0, initval=theta[0])
beta = pm.TruncatedNormal("beta", mu=theta[1], sigma=0.01, lower=0, initval=theta[1])
gamma = pm.TruncatedNormal("gamma", mu=theta[2], sigma=0.1, lower=0, initval=theta[2])
delta = pm.TruncatedNormal("delta", mu=theta[3], sigma=0.01, lower=0, initval=theta[3])
xt0 = pm.TruncatedNormal("xto", mu=theta[4], sigma=1, lower=0, initval=theta[4])
yt0 = pm.TruncatedNormal("yto", mu=theta[5], sigma=1, lower=0, initval=theta[5])
sigma = pm.HalfNormal("sigma", 10)
# ode_solution
ode_solution = ode_model(y0=[xt0, yt0], theta=[alpha, beta, gamma, delta])
# Likelihood
pm.Normal("Y_obs", mu=ode_solution, sigma=sigma, observed=data[["hare", "lynx"]].values)
sampler = "NUTS PyMC ODE"
tune = draws = 15
with model:
trace_pymc_ode = pm.sample(tune=tune, draws=draws)
Only 15 samples in chain.
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [alpha, beta, gamma, delta, xto, yto, sigma]
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.2340415876362D-14
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.2340415876362D-14
/home/osvaldo/anaconda3/envs/pymc/lib/python3.10/site-packages/scipy/integrate/_odepack_py.py:248: ODEintWarning: Excess work done on this call (perhaps wrong Dfun type). Run with full_output = 1 to get quantitative information.
warnings.warn(warning_msg, ODEintWarning)
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.7324477632756D-17
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.5527744901481D-17
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.1105548980296D-16
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.1105548980296D-16
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.1105548980296D-16
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.1105548980296D-15
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.1105548980296D-15
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.1105548980296D-15
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.1105548980296D-15
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.1105548980296D-14
lsoda-- above warning has been issued i1 times. it will not be issued again for this problem in above message, i1 = 10
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.5241493348134D-15
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.5241493348134D-15
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.1088694571877D-13
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.1088694571877D-13
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.1088694571877D-13
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.4463323525725D-13
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.3388355031231D-13
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.3388355031231D-13
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.3388355031231D-13
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.6776710062462D-13
lsoda-- above warning has been issued i1 times. it will not be issued again for this problem in above message, i1 = 10
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.4158457835953D-42
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.4158457835953D-42
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.1370912617246D-40
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.1370912617246D-40
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.1370912617246D-40
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.5948148309049D-40
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.4374718724784D-40
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.3628059832750D-40
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.3628059832750D-40
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.3628059832750D-40
lsoda-- above warning has been issued i1 times. it will not be issued again for this problem in above message, i1 = 10
/home/osvaldo/anaconda3/envs/pymc/lib/python3.10/site-packages/scipy/integrate/_odepack_py.py:248: ODEintWarning: Excess work done on this call (perhaps wrong Dfun type). Run with full_output = 1 to get quantitative information.
warnings.warn(warning_msg, ODEintWarning)
/home/osvaldo/anaconda3/envs/pymc/lib/python3.10/site-packages/scipy/integrate/_odepack_py.py:248: ODEintWarning: Excess work done on this call (perhaps wrong Dfun type). Run with full_output = 1 to get quantitative information.
warnings.warn(warning_msg, ODEintWarning)
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.8146615298522D-82
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.8146615298522D-82
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.8146615298522D-78
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.8146615298522D-78
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.8146615298522D-78
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.8146615298522D-77
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.8146615298522D-77
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.8146615298522D-77
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.8146615298522D-77
lsoda-- warning..internal t (=r1) and h (=r2) are such that in the machine, t + h = t on the next step
(h = step size). solver will continue anyway in above, r1 = 0.1900000000000D+04 r2 = 0.7775771408140D-76
lsoda-- above warning has been issued i1 times. it will not be issued again for this problem in above message, i1 = 10
Sampling 4 chains for 15 tune and 15 draw iterations (60 + 60 draws total) took 60 seconds.
The number of samples is too small to check convergence reliably.
trace = trace_pymc_ode
az.summary(trace)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | 0.472 | 0.031 | 0.389 | 0.506 | 0.008 | 0.006 | 17.0 | 33.0 | 1.36 |
| beta | 0.026 | 0.003 | 0.022 | 0.032 | 0.001 | 0.001 | 12.0 | 40.0 | 1.54 |
| gamma | 0.959 | 0.080 | 0.868 | 1.151 | 0.025 | 0.018 | 11.0 | 33.0 | 1.59 |
| delta | 0.029 | 0.003 | 0.026 | 0.035 | 0.001 | 0.001 | 14.0 | 37.0 | 1.33 |
| xto | 34.907 | 0.852 | 33.526 | 36.300 | 0.099 | 0.071 | 98.0 | 43.0 | 1.21 |
| yto | 3.347 | 0.772 | 1.742 | 4.342 | 0.278 | 0.205 | 10.0 | 16.0 | 1.78 |
| sigma | 6.117 | 4.425 | 3.502 | 16.420 | 1.353 | 0.984 | 9.0 | 16.0 | 1.87 |
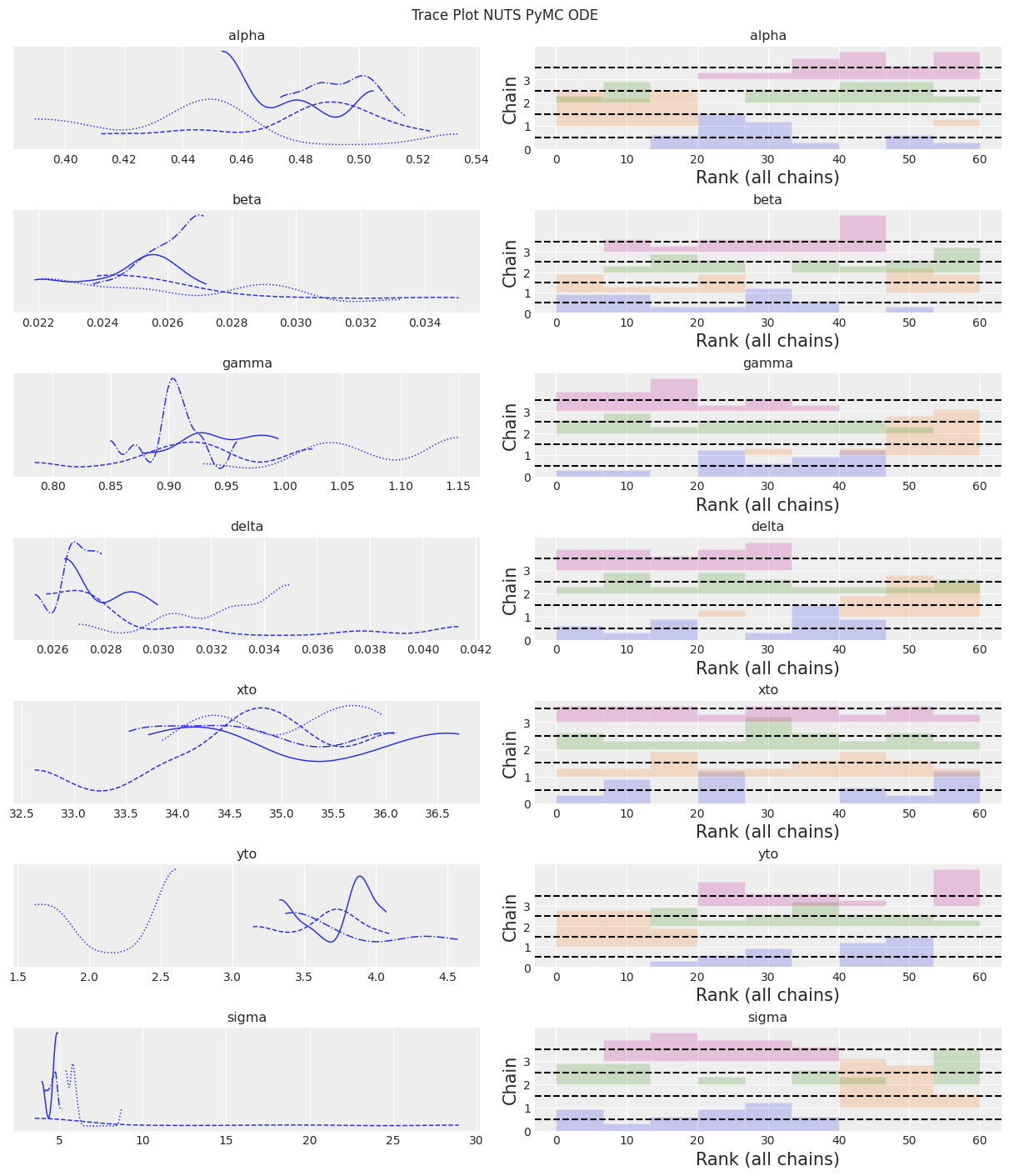
az.plot_trace(trace, kind="rank_bars")
plt.suptitle(f"Trace Plot {sampler}");
_, ax = plt.subplots(figsize=(12, 4))
plot_inference(ax, trace, title=f"Data and Inference Model Runs\n{sampler} Sampler");
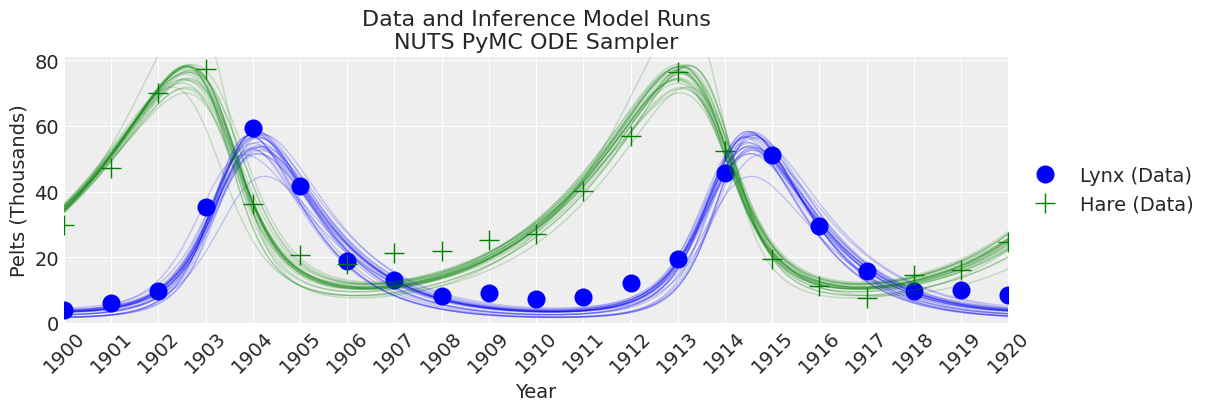
Notes:
NUTS is starting to find to the correct posterior, but would need a whole lot more time to make a good inference.
Simulate with Pytensor Scan#
Finally, we can write the system of ODEs as a forward simulation solver within PyMC. The way to write for-loops in PyMC is with pytensor.scan. Gradients are then supplied to the sampler via autodifferentiation.
First, we should test that the time steps are sufficiently small to get a reasonable estimate.
Check Time Steps#
Create a function that accepts different numbers of time steps for testing. The function also demonstrates how pytensor.scan is used.
# Lotka-Volterra forward simulation model using scan
def lv_scan_simulation_model(theta, steps_year=100, years=21):
# variables to control time steps
n_steps = years * steps_year
dt = 1 / steps_year
# PyMC model
with pm.Model() as model:
# Priors (these are static for testing)
alpha = theta[0]
beta = theta[1]
gamma = theta[2]
delta = theta[3]
xt0 = theta[4]
yt0 = theta[5]
# Lotka-Volterra calculation function
## Similar to the right-hand-side functions used earlier
## but with dt applied to the equations
def ode_update_function(x, y, alpha, beta, gamma, delta):
x_new = x + (alpha * x - beta * x * y) * dt
y_new = y + (-gamma * y + delta * x * y) * dt
return x_new, y_new
# Pytensor scan looping function
## The function argument names are not intuitive in this context!
result, updates = pytensor.scan(
fn=ode_update_function, # function
outputs_info=[xt0, yt0], # initial conditions
non_sequences=[alpha, beta, gamma, delta], # parameters
n_steps=n_steps, # number of loops
)
# Put the results together and track the result
pm.Deterministic("result", pm.math.stack([result[0], result[1]], axis=1))
return model
Run the simulation for various time steps and plot the results.
_, ax = plt.subplots(figsize=(12, 4))
steps_years = [12, 100, 1000, 10000]
for steps_year in steps_years:
time = np.arange(1900, 1921, 1 / steps_year)
model = lv_scan_simulation_model(theta, steps_year=steps_year)
with model:
prior = pm.sample_prior_predictive(1)
ax.plot(time, prior.prior.result[0][0].values, label=str(steps_year) + " steps/year")
ax.legend(loc="center left", bbox_to_anchor=(1, 0.5))
ax.set_title("Lotka-Volterra Forward Simulation Model with different step sizes");
Sampling: []
Sampling: []
Sampling: []
Sampling: []
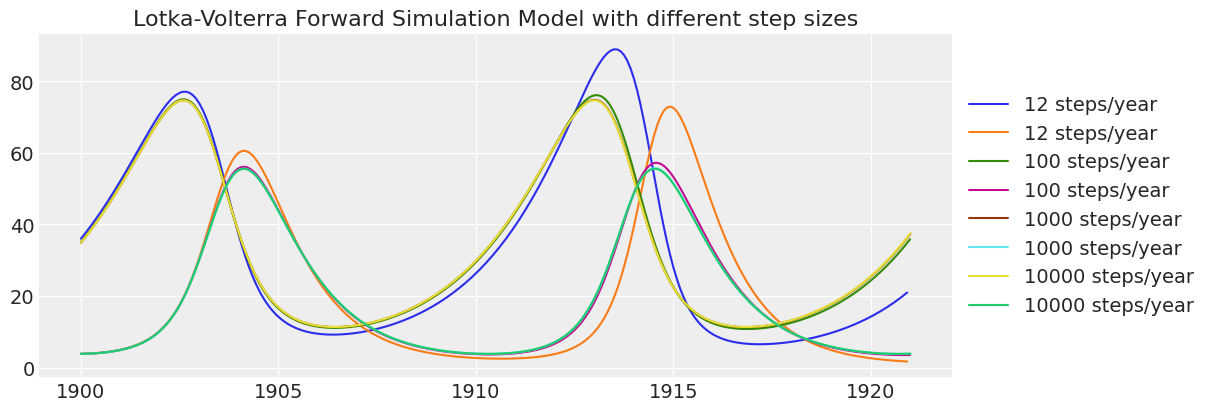
Notice how the lower resolution simulations are less accurate over time. Based on this check, 100 time steps per year is sufficiently accurate. 12 steps per year has too much “numerical diffusion” over 20 years of simulation.
Inference Using NUTs#
Now that we are OK with 100 time steps per year, we write the model with indexing to align the data with the results.
def lv_scan_inference_model(theta, steps_year=100, years=21):
# variables to control time steps
n_steps = years * steps_year
dt = 1 / steps_year
# variables to control indexing to get annual values
segment = [True] + [False] * (steps_year - 1)
boolist_idxs = []
for _ in range(years):
boolist_idxs += segment
# PyMC model
with pm.Model() as model:
# Priors
alpha = pm.TruncatedNormal("alpha", mu=theta[0], sigma=0.1, lower=0, initval=theta[0])
beta = pm.TruncatedNormal("beta", mu=theta[1], sigma=0.01, lower=0, initval=theta[1])
gamma = pm.TruncatedNormal("gamma", mu=theta[2], sigma=0.1, lower=0, initval=theta[2])
delta = pm.TruncatedNormal("delta", mu=theta[3], sigma=0.01, lower=0, initval=theta[3])
xt0 = pm.TruncatedNormal("xto", mu=theta[4], sigma=1, lower=0, initval=theta[4])
yt0 = pm.TruncatedNormal("yto", mu=theta[5], sigma=1, lower=0, initval=theta[5])
sigma = pm.HalfNormal("sigma", 10)
# Lotka-Volterra calculation function
def ode_update_function(x, y, alpha, beta, gamma, delta):
x_new = x + (alpha * x - beta * x * y) * dt
y_new = y + (-gamma * y + delta * x * y) * dt
return x_new, y_new
# Pytensor scan is a looping function
result, updates = pytensor.scan(
fn=ode_update_function, # function
outputs_info=[xt0, yt0], # initial conditions
non_sequences=[alpha, beta, gamma, delta], # parameters
n_steps=n_steps,
) # number of loops
# Put the results together
final_result = pm.math.stack([result[0], result[1]], axis=1)
# Filter the results down to annual values
annual_value = final_result[np.array(boolist_idxs), :]
# Likelihood function
pm.Normal("Y_obs", mu=annual_value, sigma=sigma, observed=data[["hare", "lynx"]].values)
return model
This is also quite slow, so we will just pull a few samples for demonstration purposes.
steps_year = 100
model = lv_scan_inference_model(theta, steps_year=steps_year)
sampler = "NUTS Pytensor Scan"
tune = draws = 50
with model:
trace_scan = pm.sample(tune=tune, draws=draws)
Only 50 samples in chain.
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [alpha, beta, gamma, delta, xto, yto, sigma]
Sampling 4 chains for 50 tune and 50 draw iterations (200 + 200 draws total) took 89 seconds.
The number of samples is too small to check convergence reliably.
trace = trace_scan
az.summary(trace)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | 0.480 | 0.025 | 0.432 | 0.526 | 0.003 | 0.002 | 77.0 | 94.0 | 1.02 |
| beta | 0.025 | 0.001 | 0.023 | 0.027 | 0.000 | 0.000 | 147.0 | 155.0 | 1.03 |
| gamma | 0.933 | 0.054 | 0.832 | 1.030 | 0.007 | 0.005 | 70.0 | 80.0 | 1.04 |
| delta | 0.028 | 0.002 | 0.024 | 0.031 | 0.000 | 0.000 | 70.0 | 94.0 | 1.04 |
| xto | 34.877 | 0.764 | 33.232 | 36.118 | 0.046 | 0.032 | 265.0 | 110.0 | 1.04 |
| yto | 3.987 | 0.504 | 2.887 | 4.749 | 0.069 | 0.049 | 58.0 | 102.0 | 1.06 |
| sigma | 4.173 | 0.488 | 3.361 | 5.005 | 0.056 | 0.039 | 83.0 | 104.0 | 1.03 |
az.plot_trace(trace, kind="rank_bars")
plt.suptitle(f"Trace Plot {sampler}");
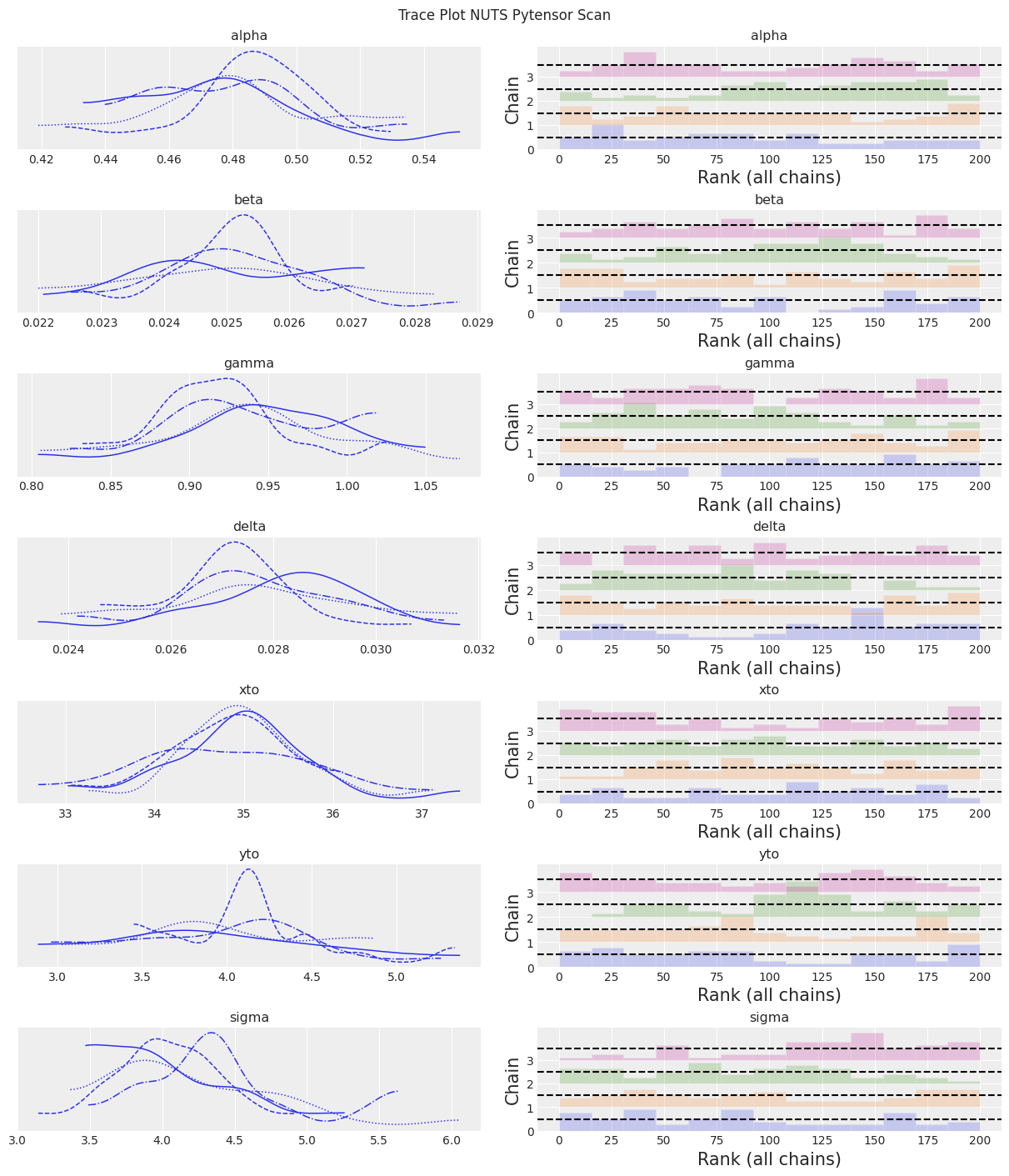
(2100, 2)
_, ax = plt.subplots(figsize=(12, 4))
plot_inference(ax, trace, title=f"Data and Inference Model Runs\n{sampler} Sampler");
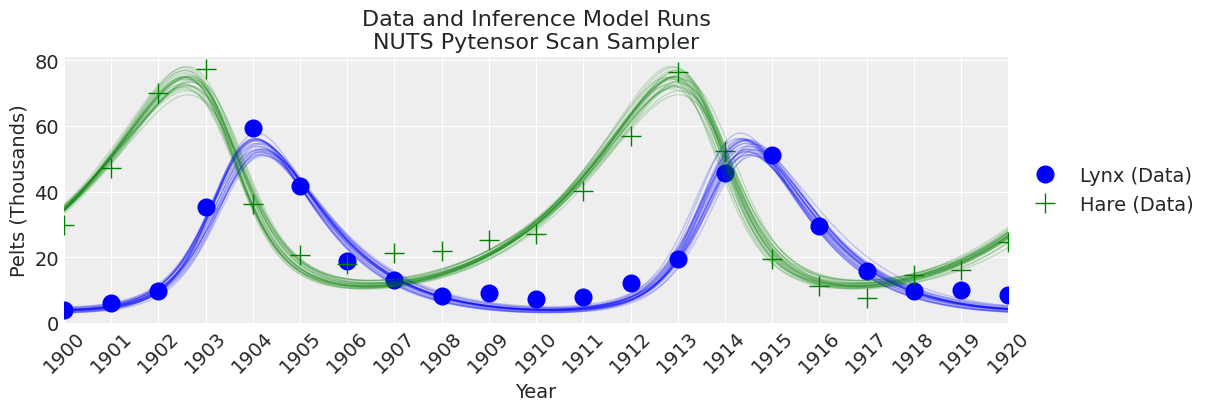
Notes:
The sampler is faster than the pymc.ode implementation, but still slower than scipy odeint combined with gradient-free inference methods.
Summary#
Let’s compare inference results among these different methods. Recall that, in order to run this notebook in a reasonable amount of time, we have an insufficient number of samples for many inference methods. For a fair comparison, we would need to bump up the number of samples and run the notebook for longer. Regardless, let’s take a look.
# Make lists with variable for looping
var_names = [str(s).split("_")[0] for s in list(model.values_to_rvs.keys())[:-1]]
# Make lists with model results and model names for plotting
inference_results = [
trace_slice,
trace_DEMZ,
trace_DEM,
trace_M,
trace_SMC_like,
trace_SMC_e1,
trace_SMC_e10,
trace_pymc_ode,
trace_scan,
]
model_names = [
"Slice Sampler",
"DEMetropolisZ",
"DEMetropolis",
"Metropolis",
"SMC with Likelihood",
"SMC e=1",
"SMC e=10",
"PyMC ODE NUTs",
"Pytensor Scan NUTs",
]
# Loop through variable names
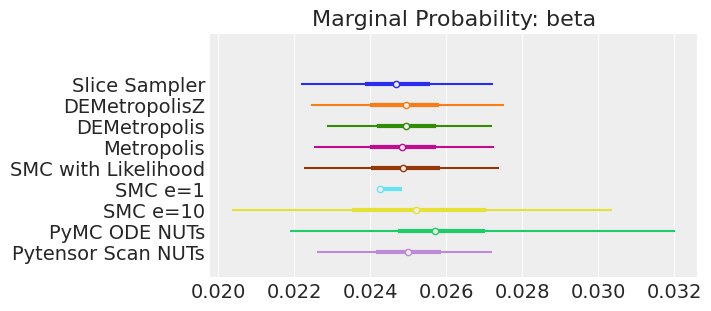
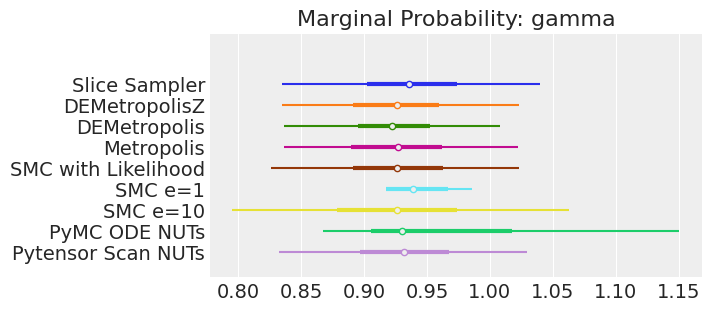
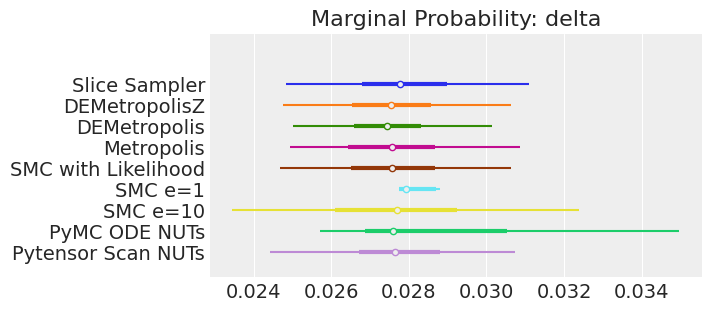
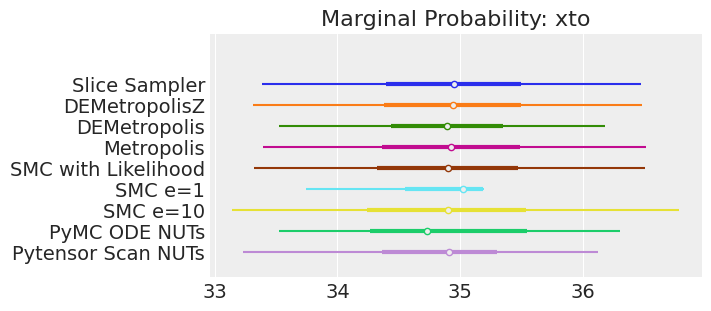
for var_name in var_names:
axes = az.plot_forest(
inference_results,
model_names=model_names,
var_names=var_name,
kind="forestplot",
legend=False,
combined=True,
figsize=(7, 3),
)
axes[0].set_title(f"Marginal Probability: {var_name}")
# Clean up ytick labels
ylabels = axes[0].get_yticklabels()
new_ylabels = []
for label in ylabels:
txt = label.get_text()
txt = txt.replace(": " + var_name, "")
label.set_text(txt)
new_ylabels.append(label)
axes[0].set_yticklabels(new_ylabels)
plt.show();
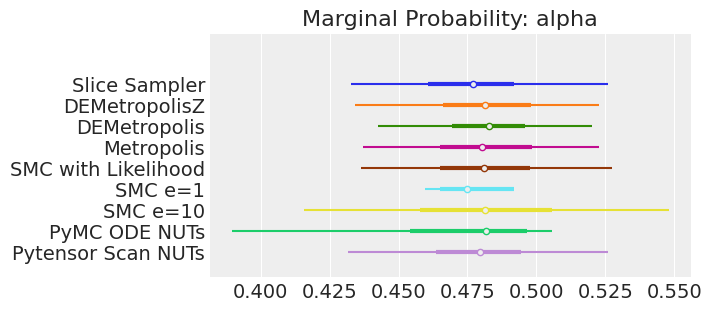
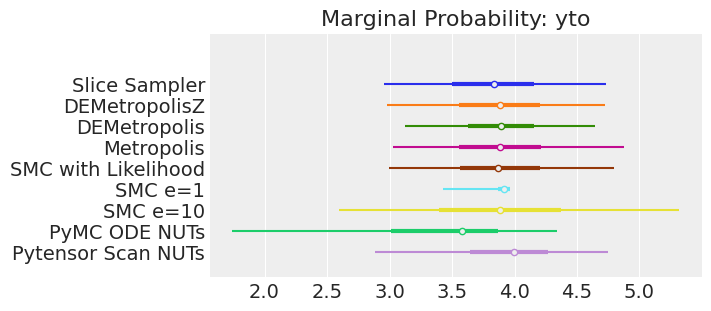
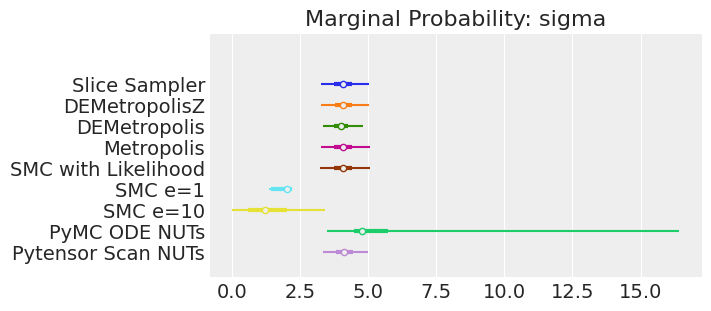
Notes:
If we ran the samplers for long enough to get good inferences, we would expect them to converge on the same posterior probability distributions. This is not necessarily true for Approximate Bayssian Computation, unless we first ensure that the approximation too the likelihood is good enough. For instance SMCe=1 is providing a wrong result, we have been warning that this was most likely the case when we use plot_trace as a diagnostic. For SMC e=10, we see that posterior mean agrees with the other samplers, but the posterior is wider. This is expected with ABC methods. A smaller value of epsilon, maybe 5, should provide a posterior closer to the true one.
Key Conclusions#
We performed Bayesian inference on a system of ODEs in 4 main ways:
Scipy
odeintwrapped in a Pytensoropand sampled with non-gradient-based samplers (comparing 5 different samplers).Scipy
odeintwrapped in apm.Simulatorfunction and sampled with a non-likelihood-based sequential Monte Carlo (SMC) sampler.PyMC
ode.DifferentialEquationsampled with NUTs.Forward simulation using
pytensor.scanand sampled with NUTs.
The “winner” for this problem was the Scipy odeint solver with a differential evolution (DE) Metropolis sampler and SMC (for a model with a Likelihood) provide good results with SMC being somewhat slower (but also better diagnostics). The improved efficiency of the NUTS sampler did not make up for the inefficiency in using the slow ODE solvers with gradients. Both DEMetropolis and SMC enable the simplest workflow for a scientist with a working numeric model and the desire to perform Bayesian inference. Just wrapping the numeric model in a Pytensor op and plugging it into a PyMC model can get you a long way!
References#
Richard McElreath. Statistical rethinking: A Bayesian course with examples in R and Stan. Chapman and Hall/CRC, 2018.
Watermark#
%watermark -n -u -v -iv -w
Last updated: Thu Mar 30 2023
Python implementation: CPython
Python version : 3.10.10
IPython version : 8.10.0
pytensor : 2.10.1
pandas : 1.5.3
matplotlib: 3.5.2
pymc : 5.1.2+12.g67925df69
numpy : 1.23.5
arviz : 0.16.0.dev0
Watermark: 2.3.1
License notice#
All the notebooks in this example gallery are provided under the MIT License which allows modification, and redistribution for any use provided the copyright and license notices are preserved.
Citing PyMC examples#
To cite this notebook, use the DOI provided by Zenodo for the pymc-examples repository.
Important
Many notebooks are adapted from other sources: blogs, books… In such cases you should cite the original source as well.
Also remember to cite the relevant libraries used by your code.
Here is an citation template in bibtex:
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
which once rendered could look like: