



Interrupted time series analysis#
This notebook focuses on how to conduct a simple Bayesian interrupted time series analysis. This is useful in quasi-experimental settings where an intervention was applied to all treatment units.
For example, if a change to a website was made and you want to know the causal impact of the website change then if this change was applied selectively and randomly to a test group of website users, then you may be able to make causal claims using the A/B testing approach.
However, if the website change was rolled out to all users of the website then you do not have a control group. In this case you do not have a direct measurement of the counterfactual, what would have happened if the website change was not made. In this case, if you have data over a ‘good’ number of time points, then you may be able to make use of the interrupted time series approach.
Interested readers are directed to the excellent textbook The Effect [Huntington-Klein, 2021]. Chapter 17 covers ‘event studies’ which the author prefers to the interrupted time series terminology.
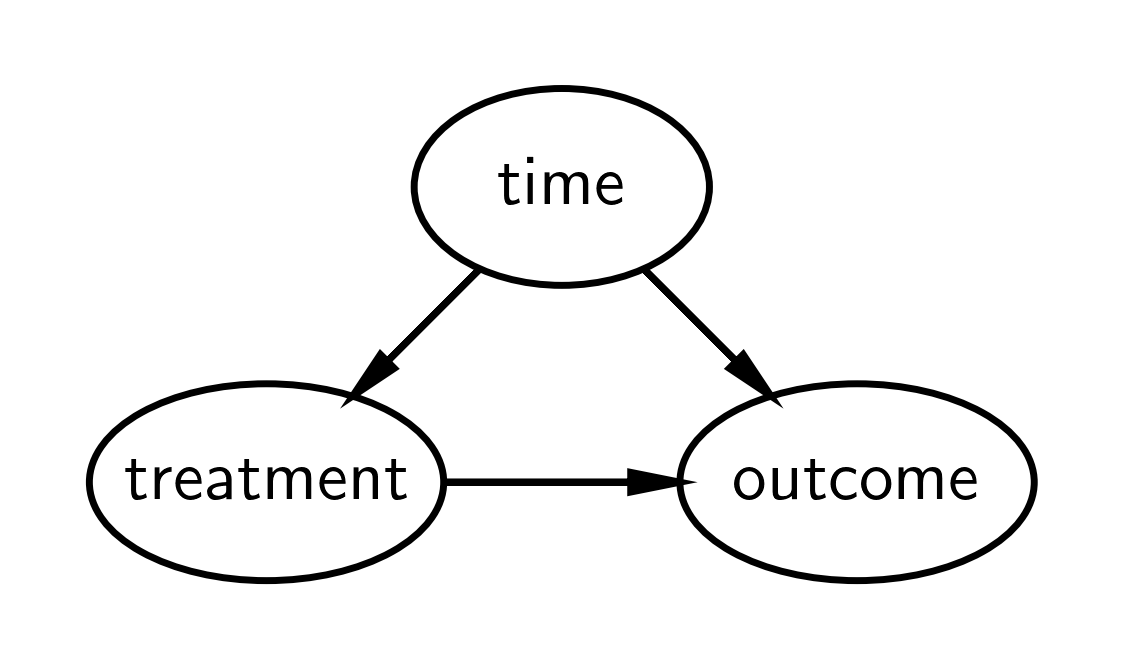
Causal DAG#
A simple causal DAG for the interrupted time series is given below, but see [Huntington-Klein, 2021] for a more general DAG. In short it says:
The outcome is causally influenced by time (e.g. other factors that change over time) and by the treatment.
The treatment is causally influenced by time.
Intuitively, we could describe the logic of the approach as:
We know that the outcome varies over time.
If we build a model of how the outcome varies over time before the treatment, then we can predit the counterfactual of what we would expect to happen if the treatment had not occurred.
We can compare this counterfactual with the observations from the time of the intervention onwards. If there is a meaningful discrepancy then we can attribute this as a causal impact of the intervention.
This is reasonable if we have ruled out other plausible causes occurring at the same point in time as (or after) the intervention. This becomes more tricky to justify the more time has passed since the intervention because it is more likely that other relevant events maye have occurred that could provide alternative causal explanations.
If this does not make sense immediately, I recommend checking the example data figure below then revisiting this section.
import arviz as az
import matplotlib.dates as mdates
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
import xarray as xr
from scipy.stats import norm
%config InlineBackend.figure_format = 'retina'
RANDOM_SEED = 8927
rng = np.random.default_rng(RANDOM_SEED)
az.style.use("arviz-darkgrid")
Now let’s define some helper functions
Generate data#
The focus of this example is on making causal claims using the interrupted time series approach. Therefore we will work with some relatively simple synthetic data which only requires a very simple model.
treatment_time = "2017-01-01"
β0 = 0
β1 = 0.1
dates = pd.date_range(
start=pd.to_datetime("2010-01-01"), end=pd.to_datetime("2020-01-01"), freq="ME"
)
N = len(dates)
def causal_effect(df):
return (df.index > treatment_time) * 2
df = (
pd.DataFrame()
.assign(time=np.arange(N), date=dates)
.set_index("date", drop=True)
.assign(y=lambda x: β0 + β1 * x.time + causal_effect(x) + norm(0, 0.5).rvs(N))
)
df
| time | y | |
|---|---|---|
| date | ||
| 2010-01-31 | 0 | 0.777161 |
| 2010-02-28 | 1 | -0.328507 |
| 2010-03-31 | 2 | 0.318300 |
| 2010-04-30 | 3 | 0.406740 |
| 2010-05-31 | 4 | 0.420023 |
| ... | ... | ... |
| 2019-08-31 | 115 | 13.440954 |
| 2019-09-30 | 116 | 12.698607 |
| 2019-10-31 | 117 | 13.414705 |
| 2019-11-30 | 118 | 13.853543 |
| 2019-12-31 | 119 | 13.574069 |
120 rows × 2 columns
# Split into pre and post intervention dataframes
pre = df[df.index < treatment_time]
post = df[df.index >= treatment_time]
fig, ax = plt.subplots()
ax = pre["y"].plot(label="pre")
post["y"].plot(ax=ax, label="post")
ax.axvline(treatment_time, c="k", ls=":")
plt.legend();

In this simple dataset, we have a noisy linear trend upwards, and because this data is synthetic we know that we have a step increase in the outcome at the intervention time, and this effect is persistent over time.
Modelling#
Here we build a simple linear model. Remember that we are building a model of the pre-intervention data with the goal that it would do a reasonable job of forecasting what would have happened if the intervention had not been applied. Put another way, we are not modelling any aspect of the post-intervention observations such as a change in intercept, slope or whether the effect is transient or permenent.
with pm.Model() as model:
# observed predictors and outcome
time = pm.Data("time", pre["time"].to_numpy(), dims="obs_id")
# priors
beta0 = pm.Normal("beta0", 0, 1)
beta1 = pm.Normal("beta1", 0, 0.2)
# the actual linear model
mu = pm.Deterministic("mu", beta0 + (beta1 * time), dims="obs_id")
sigma = pm.HalfNormal("sigma", 2)
# likelihood
pm.Normal("obs", mu=mu, sigma=sigma, observed=pre["y"].to_numpy(), dims="obs_id")
pm.model_to_graphviz(model)

Prior predictive check#
As part of the Bayesian workflow, we will plot our prior predictions to see what outcomes the model finds before having observed any data.
with model:
idata = pm.sample_prior_predictive(random_seed=RANDOM_SEED)
fig, ax = plt.subplots(figsize=figsize)
plot_xY(pre.index, idata.prior_predictive["obs"], ax)
format_x_axis(ax)
ax.plot(pre.index, pre["y"], label="observed")
ax.set(title="Prior predictive distribution in the pre intervention era")
plt.legend();
Sampling: [beta0, beta1, obs, sigma]

This seems reasonable in that the priors over the intercept and slope are broad enough to lead to predicted observations which easily contain the actual data. This means that the particular priors chosen will not unduly constrain the posterior parameter estimates.
Inference#
Draw samples for the posterior distribution, and remember we are doing this for the pre intervention data only.
with model:
idata.extend(pm.sample(random_seed=RANDOM_SEED))
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta0, beta1, sigma]
/Users/cassiebastress/miniconda3/envs/pymc-examples/lib/python3.11/site-packages/rich/live.py:256: UserWarning:
install "ipywidgets" for Jupyter support
warnings.warn('install "ipywidgets" for Jupyter support')
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
az.plot_trace(idata, var_names=["~mu"]);

Posterior predictive check#
Another important aspect of the Bayesian workflow is to plot the model’s posterior predictions, allowing us to see how well the model can retrodict the already observed data. It is at this point that we can decide whether the model is too simple (then we’d build more complexity into the model) or if it’s fine.
with model:
idata.extend(pm.sample_posterior_predictive(idata, random_seed=RANDOM_SEED))
fig, ax = plt.subplots(figsize=figsize)
az.plot_hdi(pre.index, idata.posterior_predictive["obs"], hdi_prob=0.5, smooth=False)
az.plot_hdi(pre.index, idata.posterior_predictive["obs"], hdi_prob=0.95, smooth=False)
ax.plot(pre.index, pre["y"], label="observed")
format_x_axis(ax)
ax.set(title="Posterior predictive distribution in the pre intervention era")
plt.legend();
Sampling: [obs]
/Users/cassiebastress/miniconda3/envs/pymc-examples/lib/python3.11/site-packages/rich/live.py:256: UserWarning:
install "ipywidgets" for Jupyter support
warnings.warn('install "ipywidgets" for Jupyter support')

The next step is not strictly necessary, but we can calculate the difference between the model retrodictions and the data to look at the errors. This can be useful to identify any unexpected inability to retrodict pre-intervention data.
fig, ax = plt.subplots(figsize=figsize)
# the transpose is to keep arviz happy, ordering the dimensions as (chain, draw, time)
az.plot_hdi(pre.index, excess.transpose(..., "obs_id"), hdi_prob=0.5, smooth=False)
az.plot_hdi(pre.index, excess.transpose(..., "obs_id"), hdi_prob=0.95, smooth=False)
format_x_axis(ax)
ax.axhline(y=0, color="k")
ax.set(title="Residuals, pre intervention");

Counterfactual inference#
Now we will use our model to predict the observed outcome in the ‘what if?’ scenario of no intervention.
So we update the model with the time data from the post intervention dataframe and run posterior predictive sampling to predict the observations we would observe in this counterfactual scenario. We could also call this ‘forecasting’.
with model:
pm.set_data(
{
"time": post["time"].to_numpy(),
}
)
counterfactual = pm.sample_posterior_predictive(
idata, var_names=["obs"], random_seed=RANDOM_SEED
)
Sampling: [obs]
/Users/cassiebastress/miniconda3/envs/pymc-examples/lib/python3.11/site-packages/rich/live.py:256: UserWarning:
install "ipywidgets" for Jupyter support
warnings.warn('install "ipywidgets" for Jupyter support')

We now have the ingredients needed to calculate the causal impact. This is simply the difference between the Bayesian counterfactual predictions and the observations.
Causal impact: since the intervention#
Now we’ll use the predicted outcome under the counterfactual scenario and compare that to the observed outcome to come up with our counterfactual estimate.
# convert outcome into an XArray object with a labelled dimension to help in the next step
outcome = xr.DataArray(post["y"].to_numpy(), dims=["obs_id"])
# do the calculation by taking the difference
excess = outcome - counterfactual.posterior_predictive["obs"]
And we can easily compute the cumulative causal impact
# calculate the cumulative causal impact
cumsum = excess.cumsum(dim="obs_id")

And there we have it - we’ve done some Bayesian counterfactual inference in PyMC using the interrupted time series approach! In just a few steps we’ve:
Built a simple model to predict a time series.
Inferred the model parameters based on pre intervention data, running prior and posterior predictive checks. We note that the model is pretty good.
Used the model to create counterfactual predictions of what would happen after the intervention time if the intervention had not occurred.
Calculated the causal impact (and cumulative causal impact) by comparing the observed outcome to our counterfactual expected outcome in the case of no intervention.
There are of course many ways that the interrupted time series approach could be more involved in real world settings. For example there could be more temporal structure, such as seasonality. If so then we might want to use a specific time series model, not just a linear regression model. There could also be additional informative predictor variables to incorporate into the model. Additionally some designs do not just consist of pre and post intervention periods (also known as A/B designs), but could also involve a period where the intervention is inactive, active, and then inactive (also known as an ABA design).
References#
Watermark#
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor,xarray
Last updated: Mon, 05 Jan 2026
Python implementation: CPython
Python version : 3.11.11
IPython version : 9.9.0
pytensor: 2.36.1
xarray : 2025.12.0
arviz : 0.23.0
matplotlib: 3.10.8
numpy : 2.3.5
pandas : 2.3.3
pymc : 5.27.0
xarray : 2025.12.0
Watermark: 2.6.0
License notice#
All the notebooks in this example gallery are provided under the MIT License which allows modification, and redistribution for any use provided the copyright and license notices are preserved.
Citing PyMC examples#
To cite this notebook, use the DOI provided by Zenodo for the pymc-examples repository.
Important
Many notebooks are adapted from other sources: blogs, books… In such cases you should cite the original source as well.
Also remember to cite the relevant libraries used by your code.
Here is an citation template in bibtex:
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
which once rendered could look like: