
Posts in how-to
The Bayesian Workflow: COVID-19 Outbreak Modeling
- 16 June 2025
Bayesian modeling is a robust approach for drawing conclusions from data. Successful modeling involves an interplay among statistical models, subject matter knowledge, and computational techniques. In building Bayesian models, it is easy to get carried away with complex models from the outset, often leading to an unsatisfactory final result (or a dead end). To avoid common model development pitfalls, a structured approach is helpful. The Bayesian workflow (Gelman et al.) is a systematic approach to building, validating, and refining probabilistic models, ensuring that the models are robust, interpretable, and useful for decision-making. The workflow’s iterative nature ensures that modeling assumptions are tested and refined as the model grows, leading to more reliable results.
Baby Births Modelling with HSGPs
- 30 January 2024
This notebook provides an example of using the Hilbert Space Gaussian Process (HSGP) technique, introduced in [Solin and Särkkä, 2020], in the context of time series modeling. This technique has proven successful in speeding up models with Gaussian process components.
Automatic marginalization of discrete variables
- 20 January 2024
PyMC is very amendable to sampling models with discrete latent variables. But if you insist on using the NUTS sampler exclusively, you will need to get rid of your discrete variables somehow. The best way to do this is by marginalizing them out, as then you benefit from Rao-Blackwell’s theorem and get a lower variance estimate of your parameters.
Pathfinder Variational Inference
- 05 February 2023
Pathfinder [Zhang et al., 2021] is a variational inference algorithm that produces samples from the posterior of a Bayesian model. It compares favorably to the widely used ADVI algorithm. On large problems, it should scale better than most MCMC algorithms, including dynamic HMC (i.e. NUTS), at the cost of a more biased estimate of the posterior. For details on the algorithm, see the arxiv preprint.
DEMetropolis(Z) Sampler Tuning
- 18 January 2023
For continuous variables, the default PyMC sampler (NUTS) requires that gradients are computed, which PyMC does through autodifferentiation. However, in some cases, a PyMC model may not be supplied with gradients (for example, by evaluating a numerical model outside of PyMC) and an alternative sampler is necessary. The DEMetropolisZ sampler is an efficient choice for gradient-free inference. The implementation of DEMetropolisZ in PyMC is based on ter Braak and Vrugt [2008] but with a modified tuning scheme. This notebook compares various tuning parameter settings for the sampler, including the drop_tune_fraction parameter which was introduced in PyMC.
DEMetropolis and DEMetropolis(Z) Algorithm Comparisons
- 18 January 2023
For continuous variables, the default PyMC sampler (NUTS) requires that gradients are computed, which PyMC does through autodifferentiation. However, in some cases, a PyMC model may not be supplied with gradients (for example, by evaluating a numerical model outside of PyMC) and an alternative sampler is necessary. Differential evolution (DE) Metropolis samplers are an efficient choice for gradient-free inference. This notebook compares the DEMetropolis and the DEMetropolisZ samplers in PyMC to help determine which is a better option for a given problem.
Reparameterizing the Weibull Accelerated Failure Time Model
- 17 January 2023
This notebook uses libraries that are not PyMC dependencies and therefore need to be installed specifically to run this notebook. Open the dropdown below for extra guidance.
Bayesian Survival Analysis
- 17 January 2023
Survival analysis studies the distribution of the time to an event. Its applications span many fields across medicine, biology, engineering, and social science. This tutorial shows how to fit and analyze a Bayesian survival model in Python using PyMC.
ODE Lotka-Volterra With Bayesian Inference in Multiple Ways
- 16 January 2023
The purpose of this notebook is to demonstrate how to perform Bayesian inference on a system of ordinary differential equations (ODEs), both with and without gradients. The accuracy and efficiency of different samplers are compared.
Introduction to Variational Inference with PyMC
- 13 January 2023
The most common strategy for computing posterior quantities of Bayesian models is via sampling, particularly Markov chain Monte Carlo (MCMC) algorithms. While sampling algorithms and associated computing have continually improved in performance and efficiency, MCMC methods still scale poorly with data size, and become prohibitive for more than a few thousand observations. A more scalable alternative to sampling is variational inference (VI), which re-frames the problem of computing the posterior distribution as an optimization problem.
Empirical Approximation overview
- 13 January 2023
For most models we use sampling MCMC algorithms like Metropolis or NUTS. In PyMC we got used to store traces of MCMC samples and then do analysis using them. There is a similar concept for the variational inference submodule in PyMC: Empirical. This type of approximation stores particles for the SVGD sampler. There is no difference between independent SVGD particles and MCMC samples. Empirical acts as a bridge between MCMC sampling output and full-fledged VI utils like apply_replacements or sample_node. For the interface description, see variational_api_quickstart. Here we will just focus on Emprical and give an overview of specific things for the Empirical approximation.
Fitting a Reinforcement Learning Model to Behavioral Data with PyMC
- 05 August 2022
Reinforcement Learning models are commonly used in behavioral research to model how animals and humans learn, in situtions where they get to make repeated choices that are followed by some form of feedback, such as a reward or a punishment.
Censored Data Models
- 30 May 2022
This example notebook on Bayesian survival analysis touches on the point of censored data. Censoring is a form of missing-data problem, in which observations greater than a certain threshold are clipped down to that threshold, or observations less than a certain threshold are clipped up to that threshold, or both. These are called right, left and interval censoring,respectively. In this example notebook we consider interval censoring.
Model building and expansion for golf putting
- 02 April 2022
This uses and closely follows the case study from Andrew Gelman, written in Stan. There are some new visualizations and we steered away from using improper priors, but much credit to him and to the Stan group for the wonderful case study and software.
How to wrap a JAX function for use in PyMC
- 24 March 2022
This notebook uses libraries that are not PyMC dependencies and therefore need to be installed specifically to run this notebook. Open the dropdown below for extra guidance.
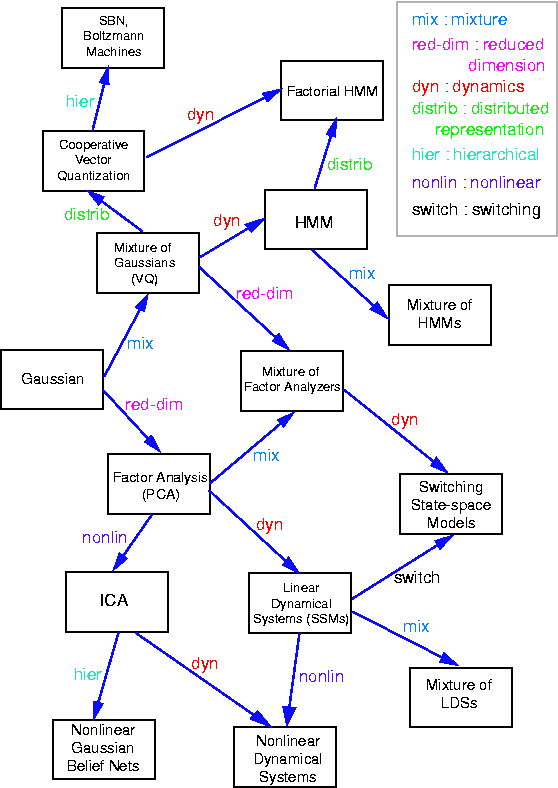
Factor analysis
- 19 March 2022
Factor analysis is a widely used probabilistic model for identifying low-rank structure in multivariate data as encoded in latent variables. It is very closely related to principal components analysis, and differs only in the prior distributions assumed for these latent variables. It is also a good example of a linear Gaussian model as it can be described entirely as a linear transformation of underlying Gaussian variates. For a high-level view of how factor analysis relates to other models, you can check out this diagram originally published by Ghahramani and Roweis.
{kind=link}
A Hierarchical model for Rugby prediction
- 19 March 2022
In this example, we’re going to reproduce the first model described in Baio and Blangiardo [2010] using PyMC. Then show how to sample from the posterior predictive to simulate championship outcomes from the scored goals which are the modeled quantities.
Using a “black box” likelihood function
- 16 December 2021
There is a related example that discusses how to use a likelihood implemented in JAX
Updating Priors
- 30 January 2017
In this notebook, we will show how, in principle, it is possible to update the priors as new data becomes available.