



Counterfactual inference: calculating excess deaths due to COVID-19#
Causal reasoning and counterfactual thinking are really interesting but complex topics! Nevertheless, we can make headway into understanding the ideas through relatively simple examples. This notebook focuses on the concepts and the practical implementation of Bayesian causal reasoning using PyMC.
We do this using the sobering but important example of calculating excess deaths due to COVID-19. As such, the ideas in this notebook strongly overlap with Google’s CausalImpact (see Brodersen et al. [2015]). Practically, we will try to estimate the number of ‘excess deaths’ since the onset of COVID-19, using data from England and Wales. Excess deaths are defined as:
Making a claim about excess deaths requires causal/counterfactual reasoning. While the reported number of deaths is nothing but a (maybe noisy and/or lagged) measure of a real observable fact in the world, expected deaths is unmeasurable because these are never realised in our timeline. That is, the expected deaths is a counterfactual thought experiment where we can ask “What would/will happen if?”
Overall strategy#
How do we go about this, practically? We will follow this strategy:
Import data on reported number of deaths from all causes (our outcome variable), as well as a few reasonable predictor variables:
average monthly temperature
month of the year, which we use to model seasonal effects
and time which is used to model any underlying linear trend.
Split into
preandpostcovid datasets. This is an important step. We want to come up with a model based upon what we know before COVID-19 so that we can construct our counterfactual predictions based on data before COVID-19 had any impact.Estimate model parameters based on the
predataset.Retrodict the number of deaths expected by the model in the pre COVID-19 period. This is not a counterfactual, but acts to tell us how capable the model is at accounting for the already observed data.
Counterfactual inference - we use our model to construct a counterfactual forecast. What would we expect to see in the future if there was no COVID-19? This can be achieved by using the famous do-operator Practically, we do this with posterior prediction on out-of-sample data.
Calculate the excess deaths by comparing the reported deaths with our counterfactual (expected number of deaths).
Modelling strategy#
We could take many different approaches to the modelling. Because we are dealing with time series data, then it would be very sensible to use a time series modelling approach. For example, Google’s CausalImpact uses a Bayesian structural time-series model, but there are many alternative time series models we could choose.
But because the focus of this case study is on the counterfactual reasoning rather than the specifics of time-series modelling, I chose the simpler approach of linear regression for time-series model (see Martin et al. [2021] for more on this).
Causal inference disclaimer#
Readers should be aware that there are of course limits to the causal claims we can make here. If we were dealing with a marketing example where we ran a promotion for a period of time and wanted to make inferences about excess sales, then we could only make strong causal claims if we had done our due diligence in accounting for other factors which may have also taken place during our promotion period.
Similarly, there are many other things that changed in the UK since January 2020 (the well documented time of the first COVID-19 cases) in England and Wales. So if we wanted to be rock solid then we should account for other feasibly relevant factors.
Finally, we are not claiming that \(x\) people died directly from the COVID-19 virus. The beauty of the concept of excess deaths is that it captures deaths from all causes that are in excess of what we would expect. As such, it covers not only those who died directly from the COVID-19 virus, but also from all downstream effects of the virus and availability of care, for example.
import calendar
import os
import arviz as az
import matplotlib.dates as mdates
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
import pytensor.tensor as pt
import seaborn as sns
import xarray as xr
%config InlineBackend.figure_format = 'retina'
RANDOM_SEED = 8927
rng = np.random.default_rng(RANDOM_SEED)
az.style.use("arviz-darkgrid")
Now let’s define some helper functions
Import data#
For our purposes we will obtain number of deaths (per month) reported in England and Wales. This data is available from the Office of National Statistics dataset Deaths registered monthly in England and Wales. I manually downloaded this data for the years 2006-2022 and aggregated it into a single .csv file. I also added the average UK monthly temperature data as a predictor, obtained from the average UK temperature from the Met Office dataset.
try:
df = pd.read_csv(os.path.join("..", "data", "deaths_and_temps_england_wales.csv"))
except FileNotFoundError:
df = pd.read_csv(pm.get_data("deaths_and_temps_england_wales.csv"))
df["date"] = pd.to_datetime(df["date"])
df = df.set_index("date")
# split into separate dataframes for pre and post onset of COVID-19
pre = df[df.index < "2020"]
post = df[df.index >= "2020"]
Visualise data#
Reported deaths over time#
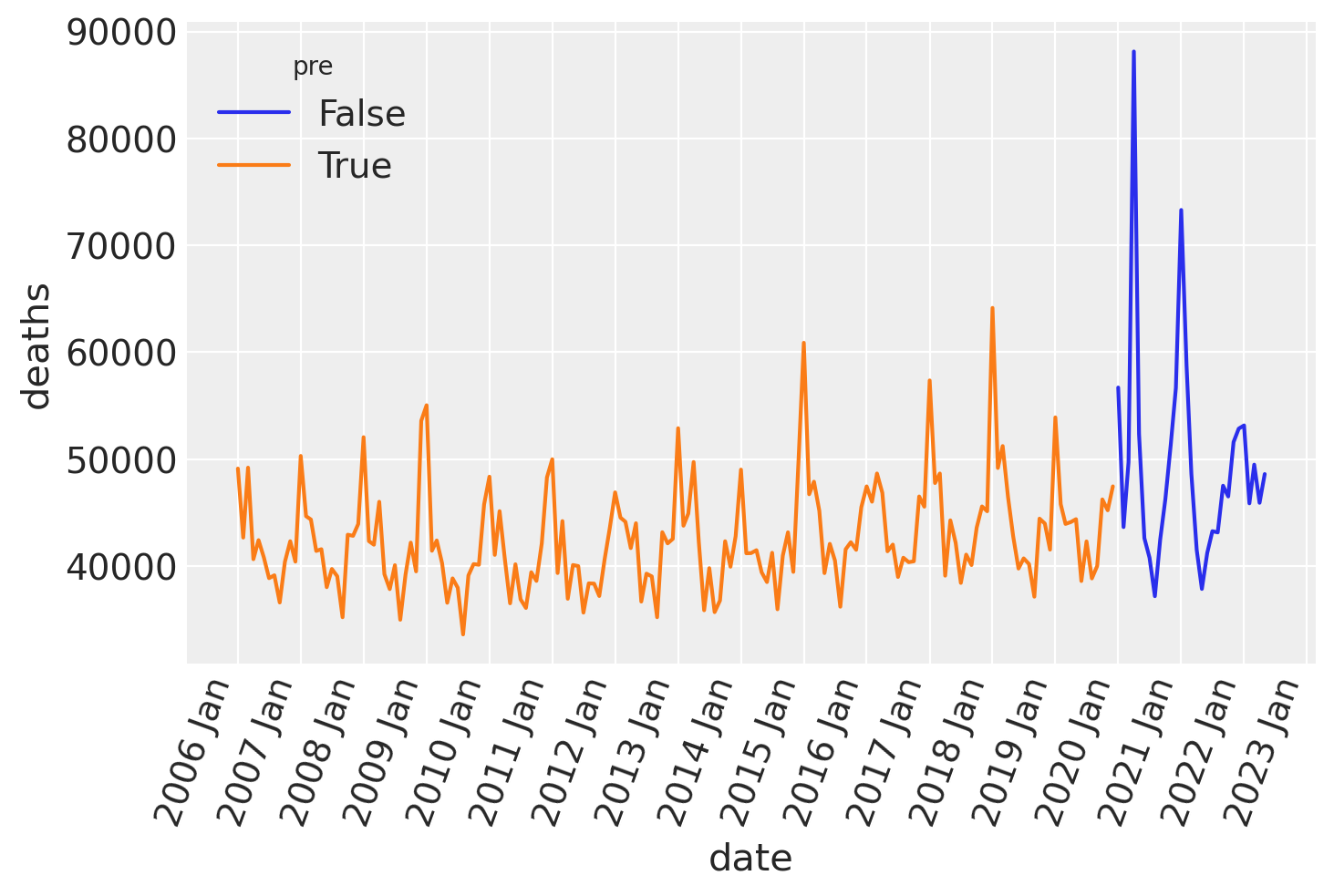
Plotting the time series shows that there is clear seasonality in the number of deaths, and we can also take a guess that there may be an increase in the average number of deaths per year.
ax = sns.lineplot(data=df, x="date", y="deaths", hue="pre")
format_x_axis(ax)
Seasonality#
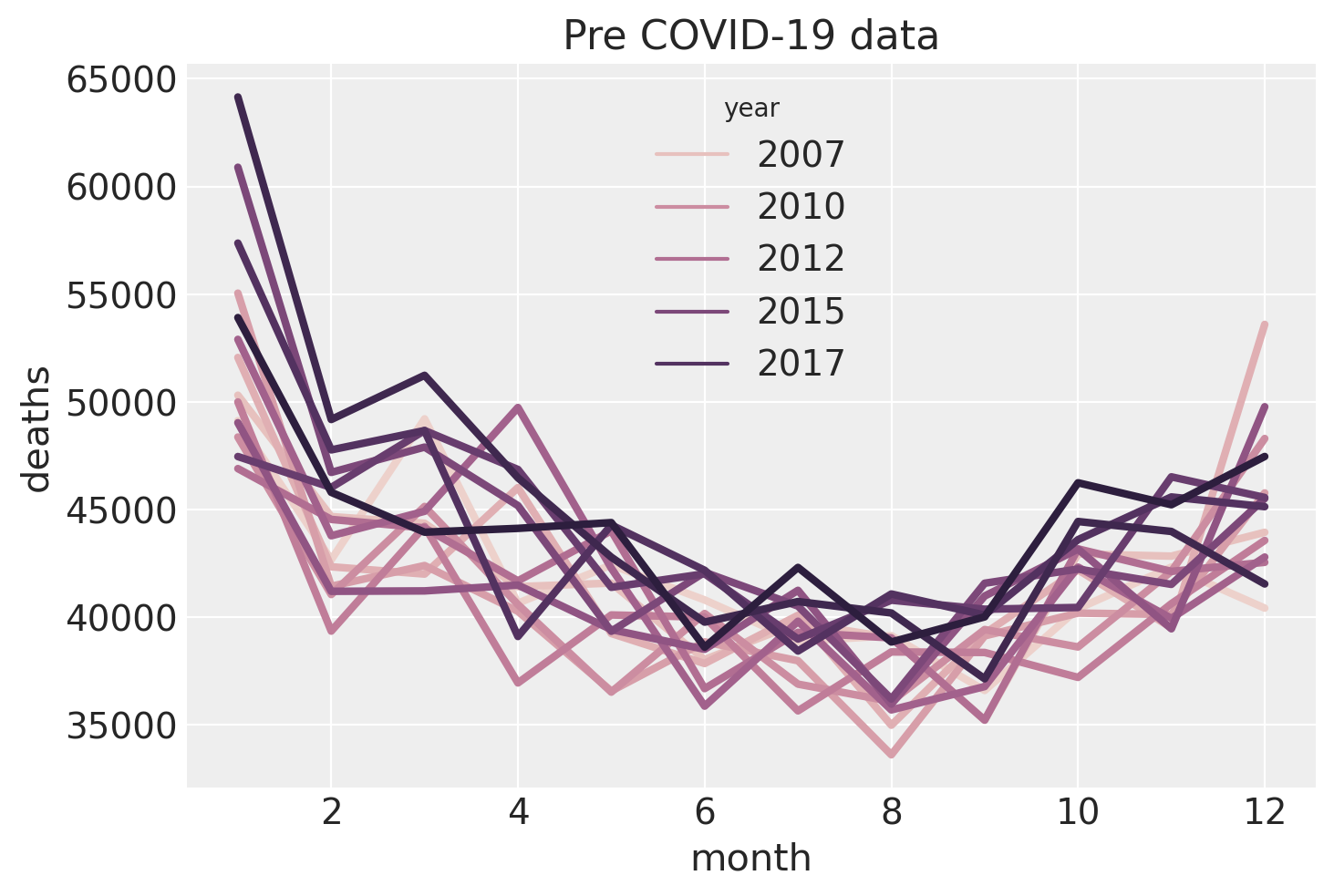
Let’s take a closer look at the seasonal pattern (just of the pre-covid data) by plotting deaths as a function of month, and we will color code the year. This confirms our suspicion of a seasonal trend in numbers of deaths with there being more deaths in the winter season than the summer. We can also see a large number of deaths in January, followed by a slight dip in February which bounces back in March. This could be due to a combination of:
push-backof deaths that actually occurred in December being registered in Januaryor
pull-forwardwhere many of the vulnerable people who would have died in February ended up dying in January, potentially due to the cold conditions.
The colour coding supports our suspicion that there is a positive main effect of year - that the baseline number of deaths per year is increasing.
ax = sns.lineplot(data=pre, x="month", y="deaths", hue="year", lw=3)
ax.set(title="Pre COVID-19 data");
Linear trend#
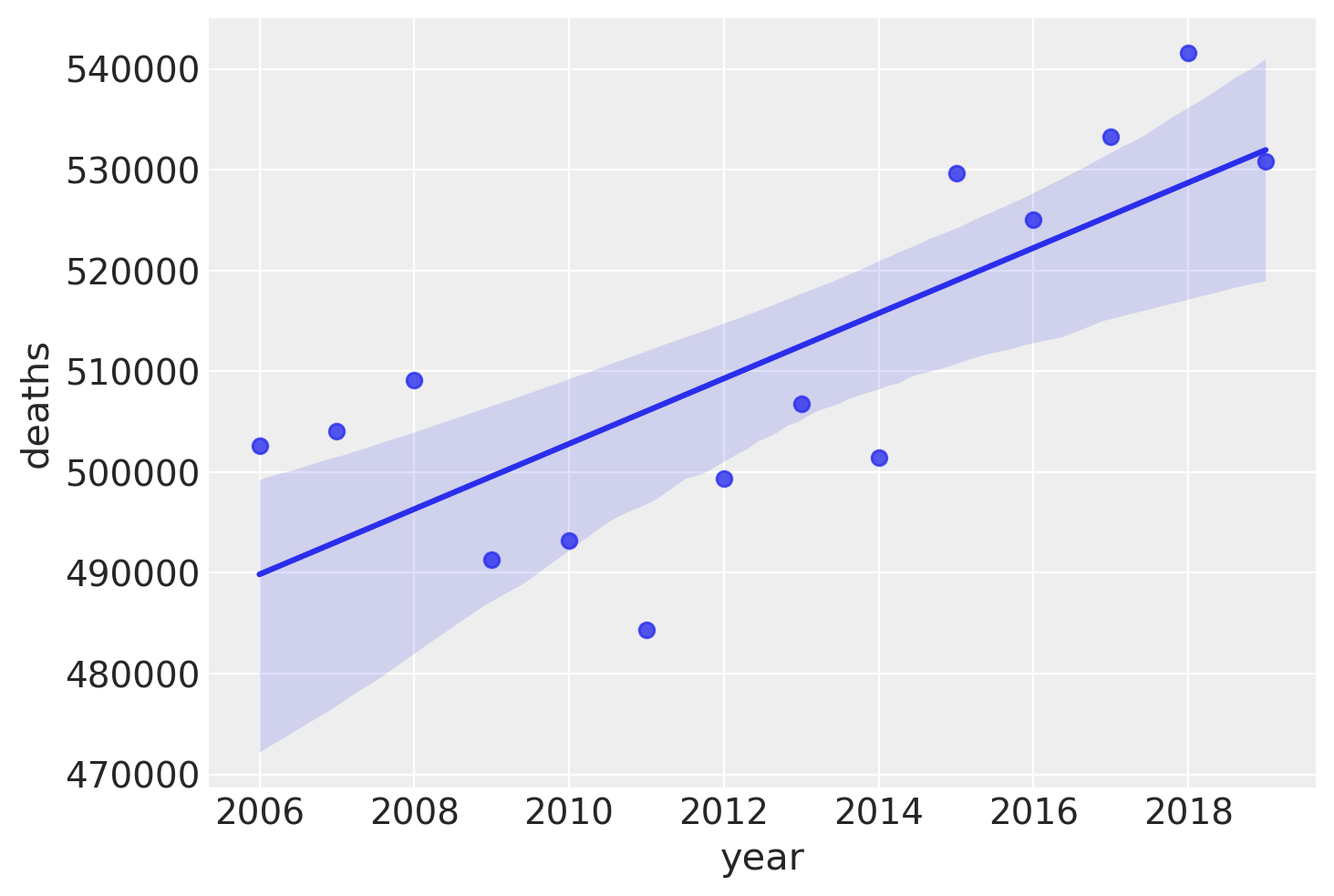
Let’s look at that more closely by plotting the total deaths over time, pre COVID-19. While there is some variability here, it seems like adding a linear trend as a predictor will capture some of the variance in reported deaths, and therefore make for a better model of reported deaths.
annual_deaths = pd.DataFrame(pre.groupby("year")["deaths"].sum()).reset_index()
sns.regplot(x="year", y="deaths", data=annual_deaths);
Effects of temperature on deaths#
Looking at the pre data alone, there is a clear negative relationship between monthly average temperature and the number of deaths. Over a wider range of temperatures it is clear that this deaths will have a U-shaped relationship with temperature. But the climate in England and Wales, we only see the lower side of this curve. Despite that, the relationship could plausibly be approximately quadratic, but for our purposes a linear relationship seems like a reasonable place to start.
fig, ax = plt.subplots(1, 2, figsize=figsize)
sns.regplot(x="temp", y="deaths", data=pre, scatter_kws={"s": 40}, order=1, ax=ax[0])
ax[0].set(title="Linear fit (pre COVID-19 data)")
sns.regplot(x="temp", y="deaths", data=pre, scatter_kws={"s": 40}, order=2, ax=ax[1])
ax[1].set(title="Quadratic fit (pre COVID-19 data)");
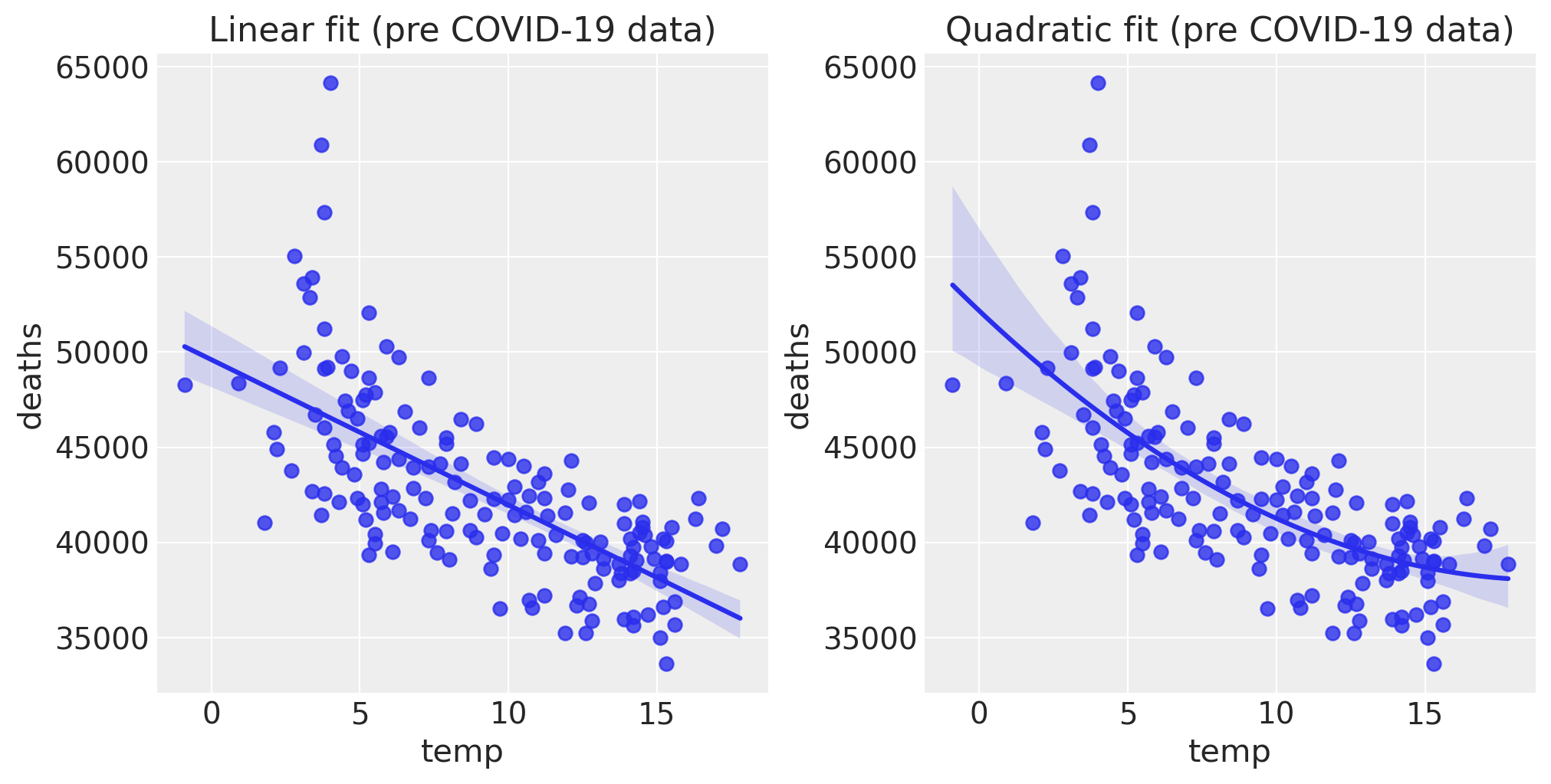
Let’s examine the slope of this relationship, which will be useful in defining a prior for a temperature coefficient in our model.
# NOTE: results are returned from higher to lower polynomial powers
slope, intercept = np.polyfit(pre["temp"], pre["deaths"], 1)
print(f"{slope:.0f} deaths/degree")
-764 deaths/degree
Based on this, if we focus only on the relationship between temperature and deaths, we expect there to be 764 fewer deaths for every \(1^\circ C\) increase in average monthly temperature. So we can use this figure when it comes to defining a prior over the coefficient for the temperature effect.
Modelling#
We are going to estimate reported deaths over time with an intercept, a linear trend, seasonal deflections (for each month), and average monthly temperature. So this is a pretty straightforward linear model. The only thing of note is that we transform the normally distributed monthly deflections to have a mean of zero in order to reduce the degrees of freedom of the model by one, which should help with parameter identifiability.
with pm.Model(coords={"month": month_strings}) as model:
# observed predictors and outcome
month = pm.MutableData("month", pre["month"].to_numpy(), dims="t")
time = pm.MutableData("time", pre["t"].to_numpy(), dims="t")
temp = pm.MutableData("temp", pre["temp"].to_numpy(), dims="t")
deaths = pm.MutableData("deaths", pre["deaths"].to_numpy(), dims="t")
# priors
intercept = pm.Normal("intercept", 40_000, 10_000)
month_mu = ZeroSumNormal("month mu", sigma=3000, dims="month")
linear_trend = pm.TruncatedNormal("linear trend", 0, 50, lower=0)
temp_coeff = pm.Normal("temp coeff", 0, 200)
# the actual linear model
mu = pm.Deterministic(
"mu",
intercept + (linear_trend * time) + month_mu[month - 1] + (temp_coeff * temp),
dims="t",
)
sigma = pm.HalfNormal("sigma", 2_000)
# likelihood
pm.TruncatedNormal("obs", mu=mu, sigma=sigma, lower=0, observed=deaths, dims="t")
pm.model_to_graphviz(model)

Prior predictive check#
As part of the Bayesian workflow, we will plot our prior predictions to see what outcomes the model finds before having observed any data.
with model:
idata = pm.sample_prior_predictive(random_seed=RANDOM_SEED)
fig, ax = plt.subplots(figsize=figsize)
plot_xY(pre.index, idata.prior_predictive["obs"], ax)
format_x_axis(ax)
ax.plot(pre.index, pre["deaths"], label="observed")
ax.set(title="Prior predictive distribution in the pre COVID-19 era")
plt.legend();
Sampling: [intercept, linear trend, month mu_raw, obs, sigma, temp coeff]
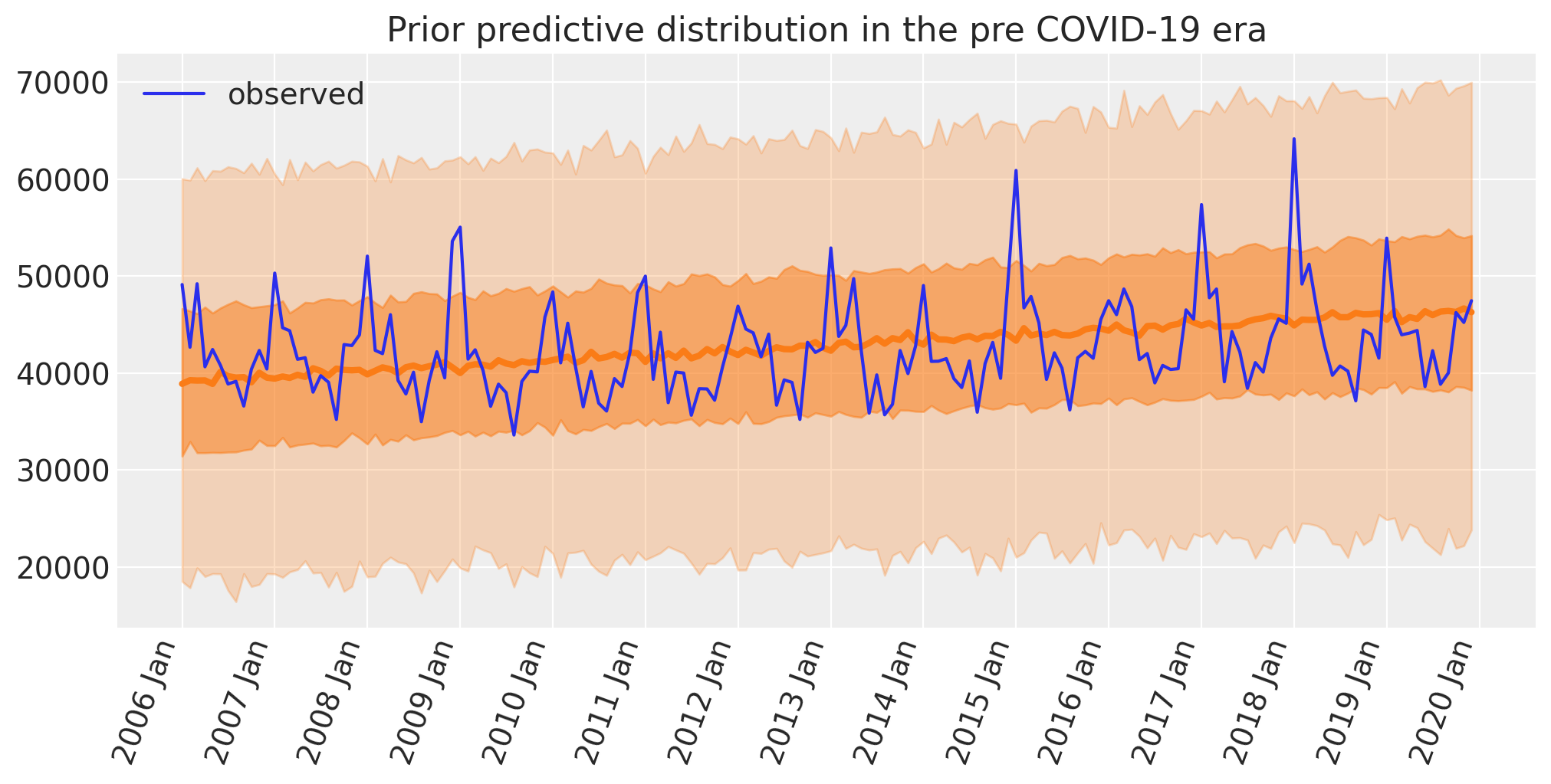
This seems reasonable:
The a priori number of deaths looks centred on the observed numbers.
Given the priors, the predicted range of deaths is quite broad, and so is unlikely to over-constrain the model.
The model does not predict negative numbers of deaths per month.
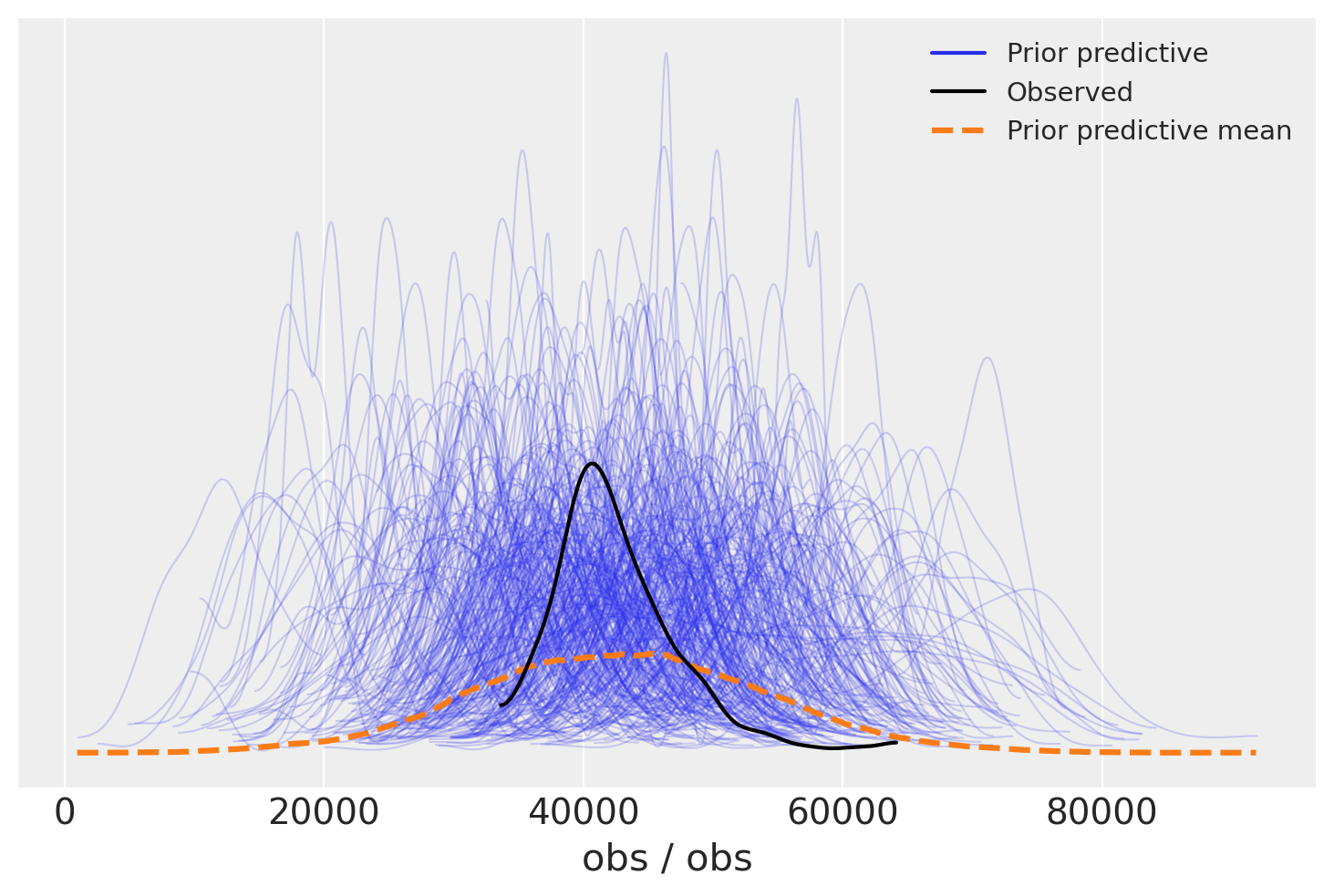
We can look at this in more detail with the Arviz prior predictive check (ppc) plot. Again we see that the distribution of the observations is centered on the actual observations but has more spread. This is useful as we know the priors are not too restrictive and are unlikely to systematically influence our posterior predictions upwards or downwards.
az.plot_ppc(idata, group="prior");
Inference#
Draw samples for the posterior distribution, and remember we are doing this for the pre COVID-19 data only.
with model:
idata.extend(pm.sample(random_seed=RANDOM_SEED))
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [intercept, month mu_raw, linear trend, temp coeff, sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 6 seconds.
az.plot_trace(idata, var_names=["~mu", "~month mu_raw"]);
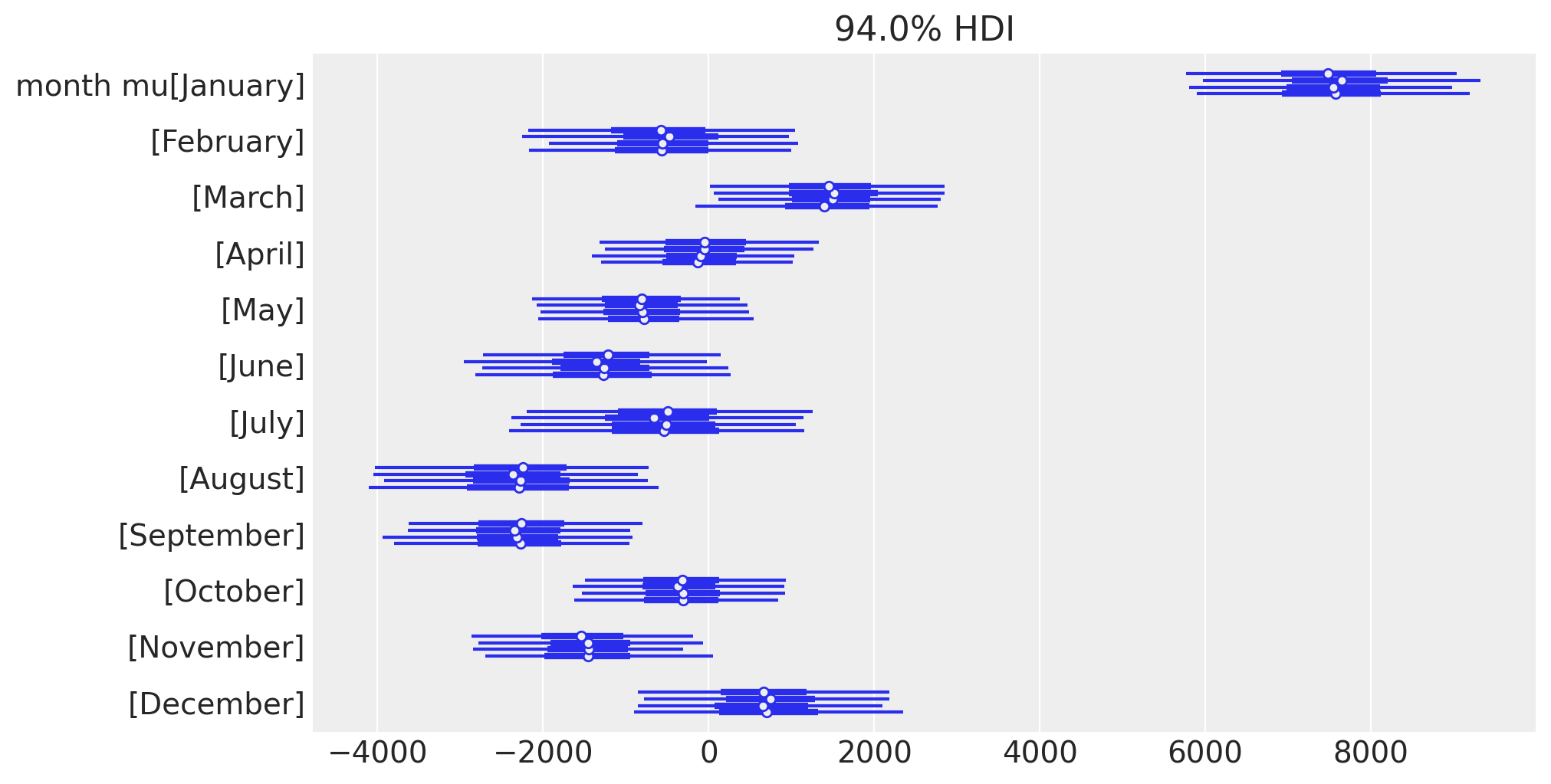
Let’s also look at the posterior estimates of the monthly deflections, in a different way to focus on the seasonal effect.
az.plot_forest(idata.posterior, var_names="month mu", figsize=figsize);
Posterior predictive check#
Another important aspect of the Bayesian workflow is to plot the model’s posterior predictions, allowing us to see how well the model can retrodict the already observed data. It is at this point that we can decide whether the model is too simple (then we’d build more complexity into the model) or if it’s fine.
with model:
idata.extend(pm.sample_posterior_predictive(idata, random_seed=RANDOM_SEED))
fig, ax = plt.subplots(figsize=figsize)
az.plot_hdi(pre.index, idata.posterior_predictive["obs"], hdi_prob=0.5, smooth=False)
az.plot_hdi(pre.index, idata.posterior_predictive["obs"], hdi_prob=0.95, smooth=False)
ax.plot(pre.index, pre["deaths"], label="observed")
format_x_axis(ax)
ax.set(title="Posterior predictive distribution in the pre COVID-19 era")
plt.legend();
Sampling: [obs]
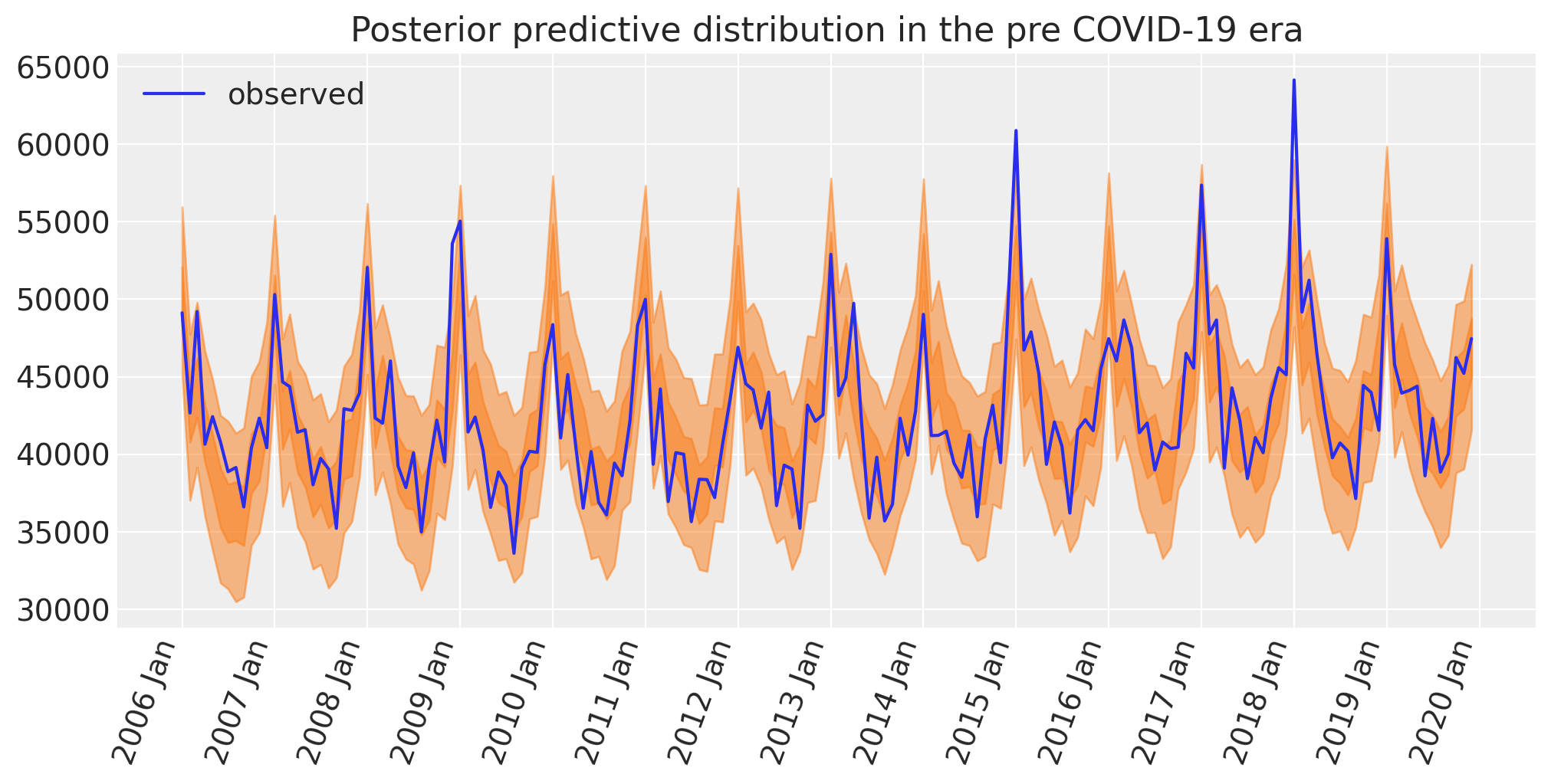
Let’s do another check now, but focussing on the seasonal effect. We will replicate the plot that we had above of deaths as a function of month of the year. And in order to keep the plot from being a complete mess, we will just plot the posterior mean. As such this is not a posterior predictive check, but a check of the posterior.
temp = idata.posterior["mu"].mean(dim=["chain", "draw"]).to_dataframe()
pre = pre.assign(deaths_predicted=temp["mu"].values)
fig, ax = plt.subplots(1, 2, figsize=figsize, sharey=True)
sns.lineplot(data=pre, x="month", y="deaths", hue="year", ax=ax[0], lw=3)
ax[0].set(title="Observed")
sns.lineplot(data=pre, x="month", y="deaths_predicted", hue="year", ax=ax[1], lw=3)
ax[1].set(title="Model predicted mean");
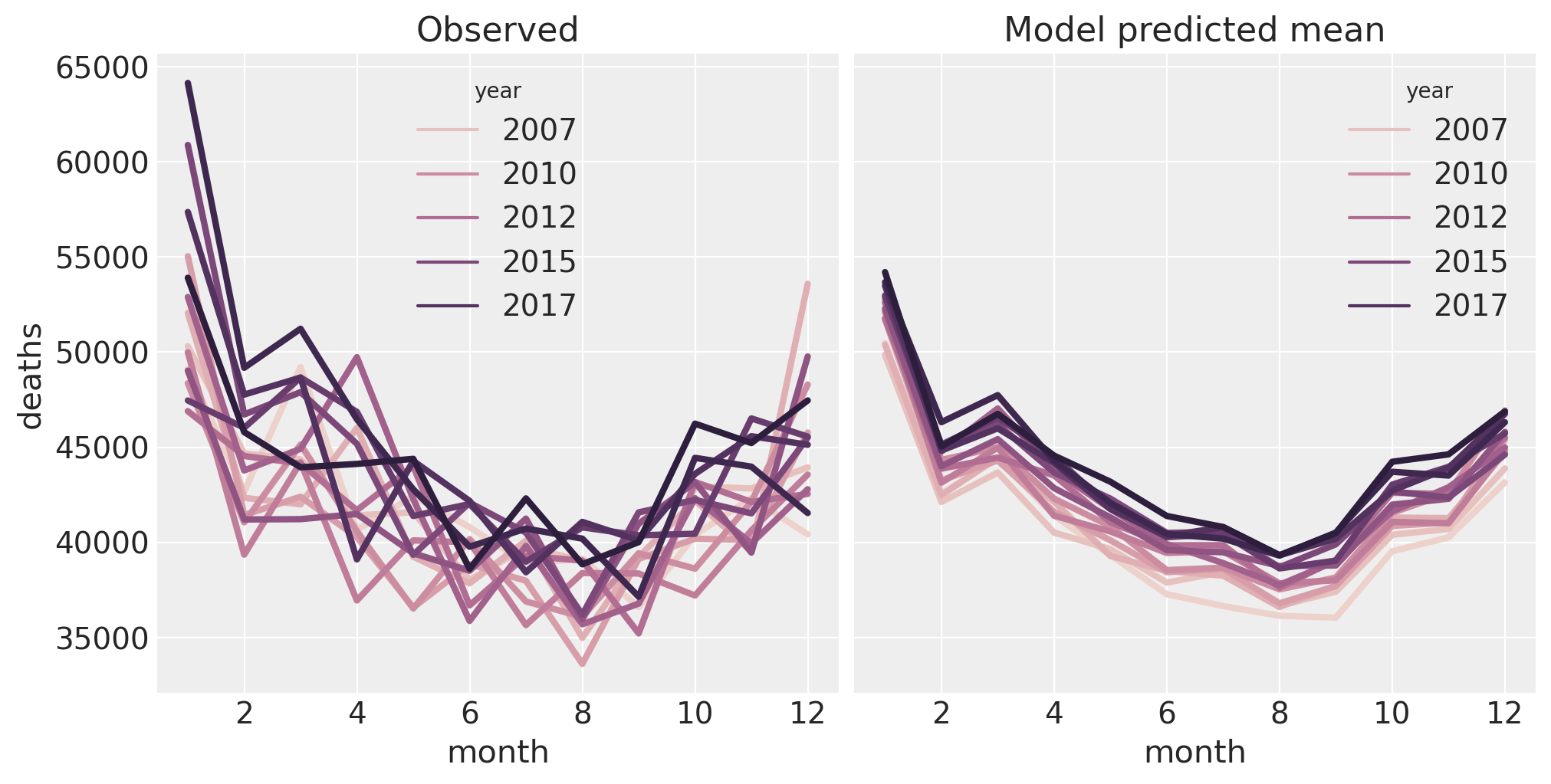
The model is doing a pretty good job of capturing the properties of the data. On the right, we can clearly see the main effects of month and year. However, we can see that there is something interesting happening in the data (left) in January which the model is not capturing. This might be able to be captured in the model by adding an interaction between month and year, but this is left as an exercise for the reader.
Excess deaths: Pre-Covid#
This step is not strictly necessary, but we can apply the excess deaths formula to the models’ retrodictions for the pre period. This is useful because we can examine how good the model is.
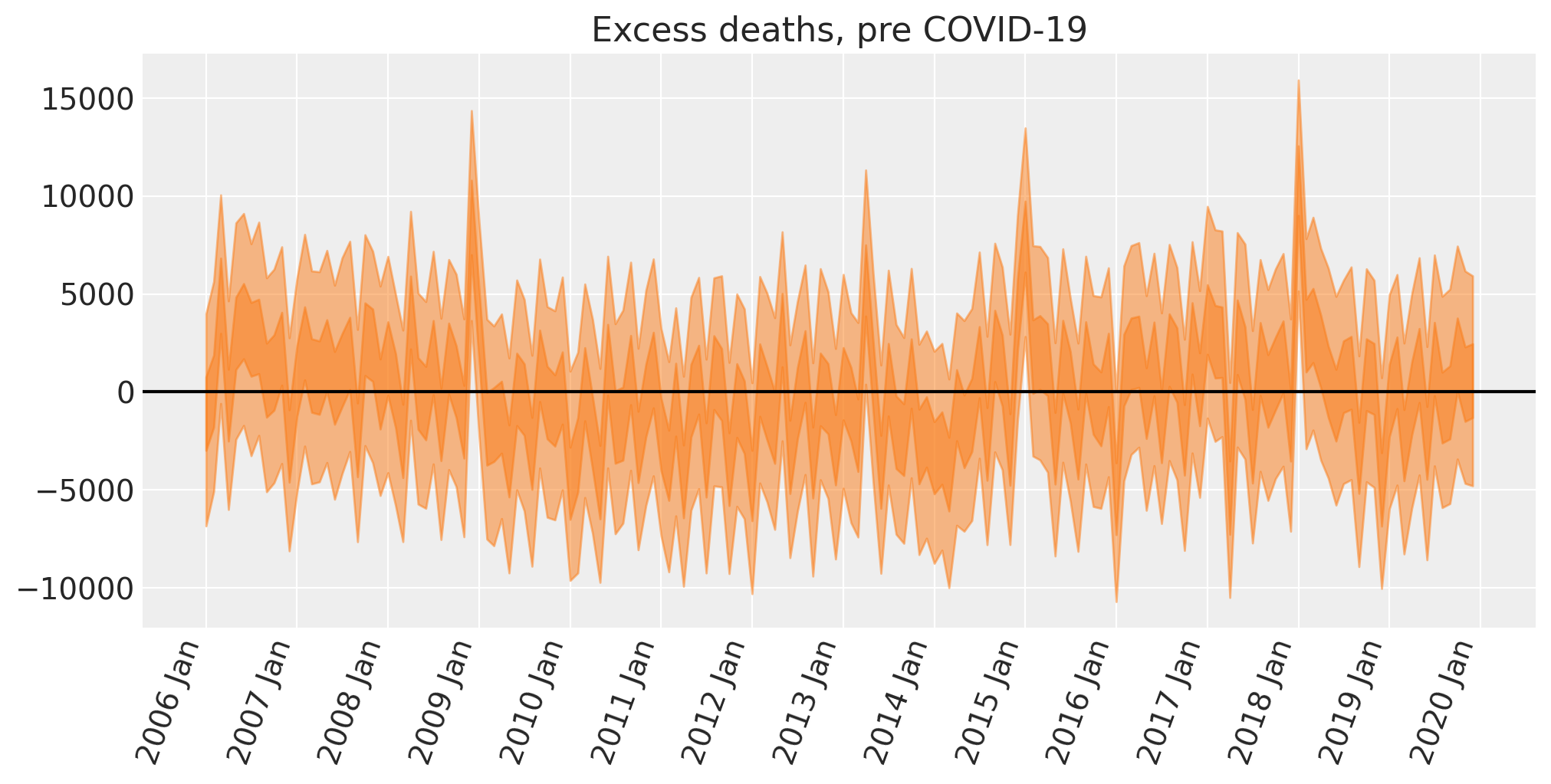
We can see that we have a few spikes here where the number of excess deaths is plausibly greater than zero. Such occasions are above and beyond what we could expect from: a) seasonal effects, b) the linearly increasing trend, c) the effect of cold winters.
If we were interested, then we could start to generate hypotheses about what additional predictors may account for this. Some ideas could include the prevalence of the common cold, or minimum monthly temperatures which could add extra predictive information not captured by the mean.
We can also see that there is some additional temporal trend that the model is not quite capturing. There is some systematic low-frequency drift from the posterior mean from zero. That is, there is additional variance in the data that our predictors are not quite capturing which could potentially be caused by changes in the size of vulnerable cohorts over time.
But we are close to our objective of calculating excess deaths during the COVID-19 period, so we will move on as the primary purpose here is on counterfactual thinking, not on building the most comprehensive model of reported deaths ever.
Counterfactual inference#
Now we will use our model to predict the reported deaths in the ‘what if?’ scenario of business as usual.
So we update the model with the month and time (t) and temp data from the post dataframe and run posterior predictive sampling to predict the number of reported deaths we would observe in this counterfactual scenario. We could also call this ‘forecasting’.
with model:
pm.set_data(
{
"month": post["month"].to_numpy(),
"time": post["t"].to_numpy(),
"temp": post["temp"].to_numpy(),
}
)
counterfactual = pm.sample_posterior_predictive(
idata, var_names=["obs"], random_seed=RANDOM_SEED
)
Sampling: [obs]
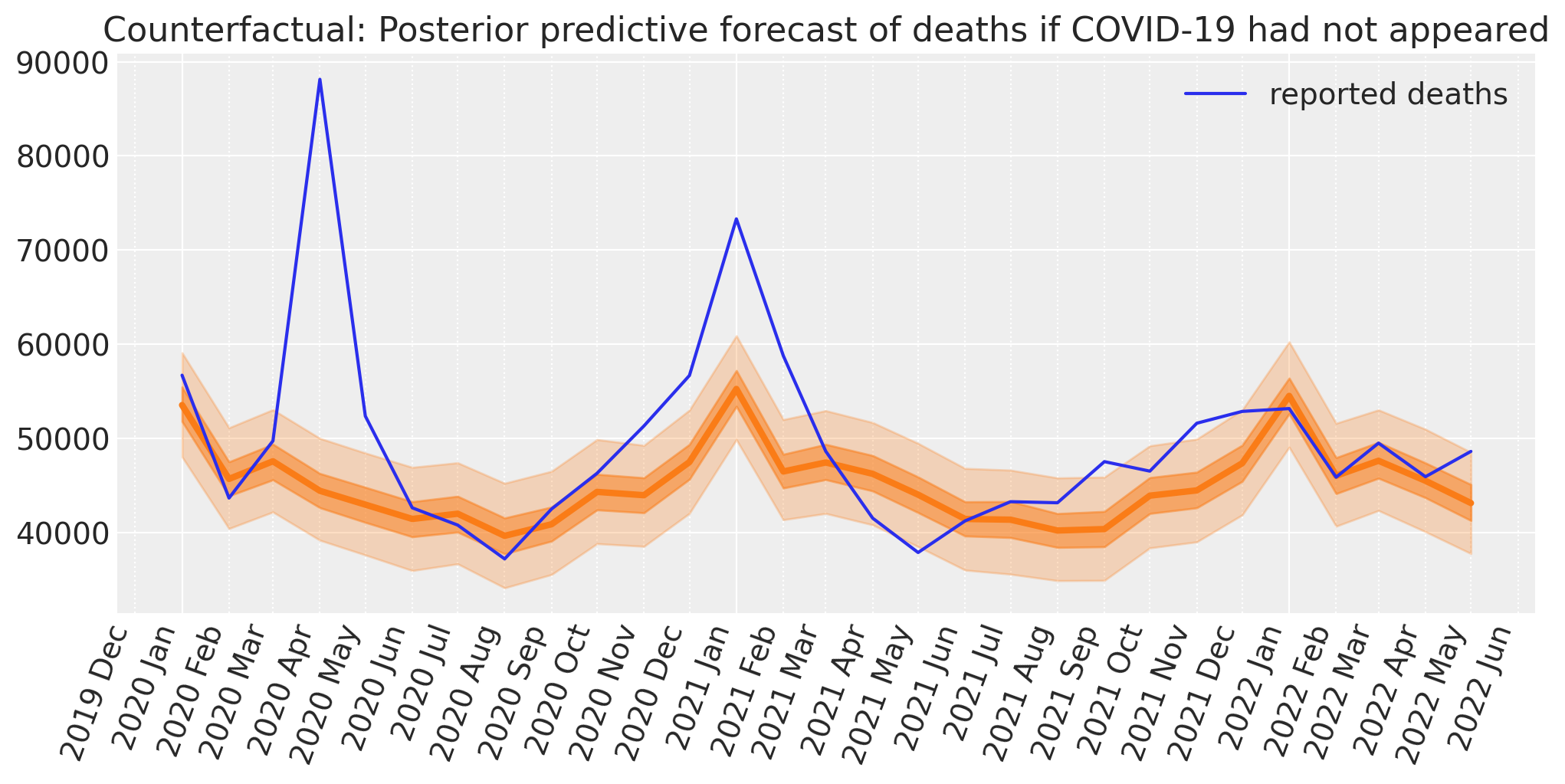
We now have the ingredients needed to calculate excess deaths. Namely, the reported number of deaths, and the Bayesian counterfactual prediction of how many would have died if nothing had changed from the pre to post COVID-19 era.
Excess deaths: since Covid onset#
Now we’ll use the predicted number of deaths under the counterfactual scenario and compare that to the reported number of deaths to come up with our counterfactual estimate of excess deaths.
# convert deaths into an XArray object with a labelled dimension to help in the next step
deaths = xr.DataArray(post["deaths"].to_numpy(), dims=["t"])
# do the calculation by taking the difference
excess_deaths = deaths - counterfactual.posterior_predictive["obs"]
And we can easily compute the cumulative excess deaths
# calculate the cumulative excess deaths
cumsum = excess_deaths.cumsum(dim="t")
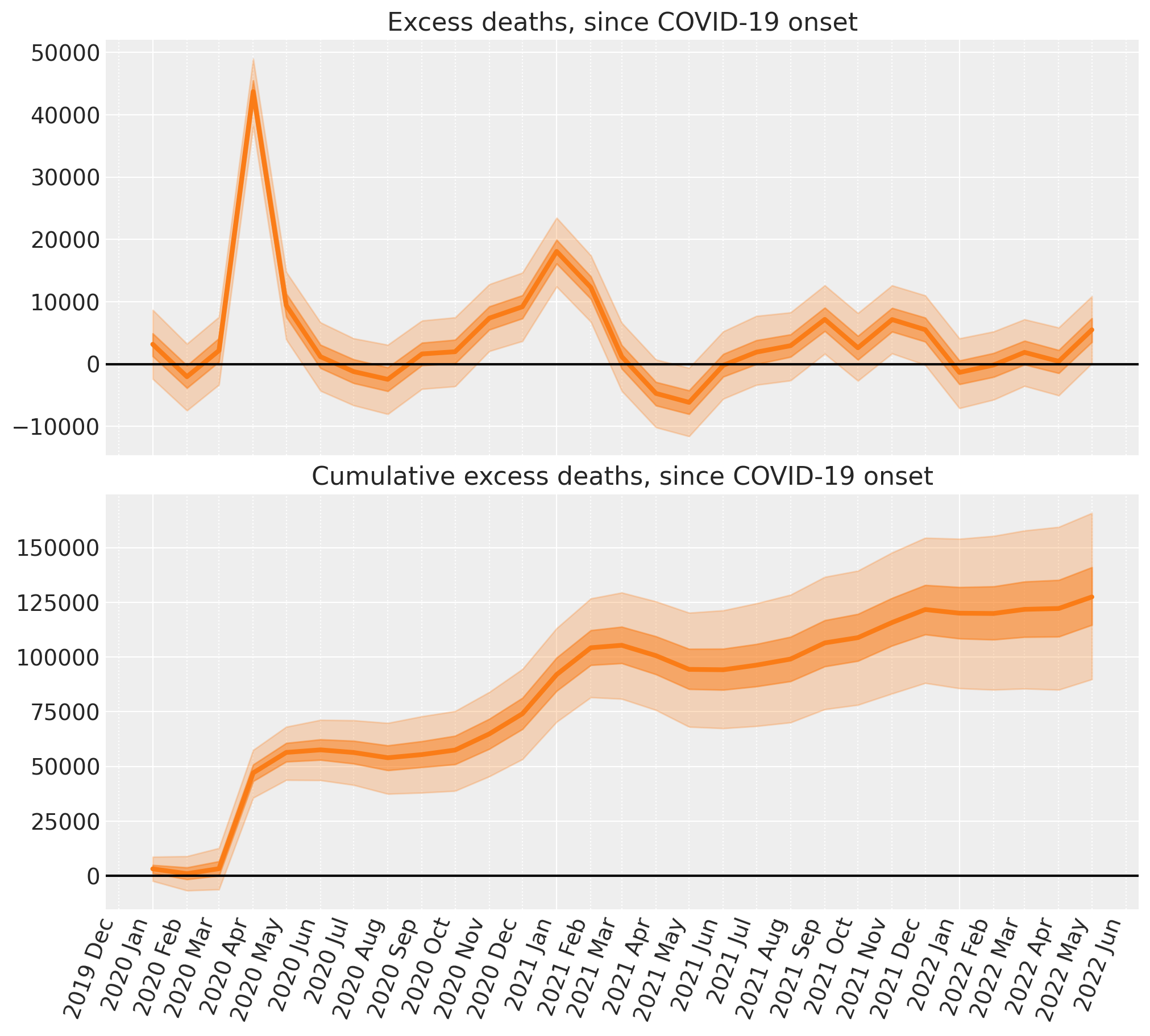
And there we have it - we’ve done some Bayesian counterfactual inference in PyMC! In just a few steps we’ve:
Built a simple linear regression model.
Inferred the model parameters based on pre COVID-19 data, running prior and posterior predictive checks. We note that the model is pretty good, but as always there might be ways to improve the model in the future.
Used the model to create counterfactual predictions of what would happen in the future (COVID-19 era) if nothing had changed.
Calculated the excess deaths (and cumulative excess deaths) by comparing the reported deaths to our counterfactual expected number of deaths.
The bad news of course, is that as of the last data point (May 2022) the number of excess deaths in England and Wales has started to rise again.
References#
Kay H. Brodersen, Fabian Gallusser, Jim Koehler, Nicolas Remy, and Steven L. Scott. Inferring causal impact using bayesian structural time-series models. Annals of Applied Statistics, 9:247–274, 2015.
Osvaldo A Martin, Ravin Kumar, and Junpeng Lao. Bayesian Modeling and Computation in Python. Chapman and Hall/CRC, 2021. doi:10.1201/9781003019169.
Watermark#
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor,aeppl,xarray
Last updated: Wed Feb 01 2023
Python implementation: CPython
Python version : 3.11.0
IPython version : 8.9.0
pytensor: 2.8.11
aeppl : not installed
xarray : 2023.1.0
pymc : 5.0.1
arviz : 0.14.0
matplotlib: 3.6.3
pandas : 1.5.3
numpy : 1.24.1
xarray : 2023.1.0
seaborn : 0.12.2
pytensor : 2.8.11
Watermark: 2.3.1
License notice#
All the notebooks in this example gallery are provided under the MIT License which allows modification, and redistribution for any use provided the copyright and license notices are preserved.
Citing PyMC examples#
To cite this notebook, use the DOI provided by Zenodo for the pymc-examples repository.
Important
Many notebooks are adapted from other sources: blogs, books… In such cases you should cite the original source as well.
Also remember to cite the relevant libraries used by your code.
Here is an citation template in bibtex:
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
which once rendered could look like: