



Bayesian Survival Analysis#
Survival analysis studies the distribution of the time to an event. Its applications span many fields across medicine, biology, engineering, and social science. This tutorial shows how to fit and analyze a Bayesian survival model in Python using PyMC.
We illustrate these concepts by analyzing a mastectomy data set from R’s HSAUR package.
import arviz as az
import numpy as np
import pandas as pd
import pymc as pm
import pytensor
from matplotlib import pyplot as plt
from pymc.distributions.timeseries import GaussianRandomWalk
from pytensor import tensor as T
print(f"Running on PyMC v{pm.__version__}")
Running on PyMC v5.0.1+42.g99dd7158
RANDOM_SEED = 8927
rng = np.random.default_rng(RANDOM_SEED)
az.style.use("arviz-darkgrid")
try:
df = pd.read_csv("../data/mastectomy.csv")
except FileNotFoundError:
df = pd.read_csv(pm.get_data("mastectomy.csv"))
df.event = df.event.astype(np.int64)
df.metastasized = (df.metastasized == "yes").astype(np.int64)
n_patients = df.shape[0]
patients = np.arange(n_patients)
df.head()
| time | event | metastasized | |
|---|---|---|---|
| 0 | 23 | 1 | 0 |
| 1 | 47 | 1 | 0 |
| 2 | 69 | 1 | 0 |
| 3 | 70 | 0 | 0 |
| 4 | 100 | 0 | 0 |
n_patients
44
Each row represents observations from a woman diagnosed with breast cancer that underwent a mastectomy. The column time represents the time (in months) post-surgery that the woman was observed. The column event indicates whether or not the woman died during the observation period. The column metastasized represents whether the cancer had metastasized prior to surgery.
This tutorial analyzes the relationship between survival time post-mastectomy and whether or not the cancer had metastasized.
A crash course in survival analysis#
First we introduce a (very little) bit of theory. If the random variable \(T\) is the time to the event we are studying, survival analysis is primarily concerned with the survival function
where \(F\) is the CDF of \(T\). It is mathematically convenient to express the survival function in terms of the hazard rate, \(\lambda(t)\). The hazard rate is the instantaneous probability that the event occurs at time \(t\) given that it has not yet occurred. That is,
Solving this differential equation for the survival function shows that
This representation of the survival function shows that the cumulative hazard function
is an important quantity in survival analysis, since we may concisely write \(S(t) = \exp(-\Lambda(t)).\)
An important, but subtle, point in survival analysis is censoring. Even though the quantity we are interested in estimating is the time between surgery and death, we do not observe the death of every subject. At the point in time that we perform our analysis, some of our subjects will thankfully still be alive. In the case of our mastectomy study, df.event is one if the subject’s death was observed (the observation is not censored) and is zero if the death was not observed (the observation is censored).
df.event.mean()
0.5909090909090909
Just over 40% of our observations are censored. We visualize the observed durations and indicate which observations are censored below.
fig, ax = plt.subplots(figsize=(8, 6))
ax.hlines(
patients[df.event.values == 0], 0, df[df.event.values == 0].time, color="C3", label="Censored"
)
ax.hlines(
patients[df.event.values == 1], 0, df[df.event.values == 1].time, color="C7", label="Uncensored"
)
ax.scatter(
df[df.metastasized.values == 1].time,
patients[df.metastasized.values == 1],
color="k",
zorder=10,
label="Metastasized",
)
ax.set_xlim(left=0)
ax.set_xlabel("Months since mastectomy")
ax.set_yticks([])
ax.set_ylabel("Subject")
ax.set_ylim(-0.25, n_patients + 0.25)
ax.legend(loc="center right");
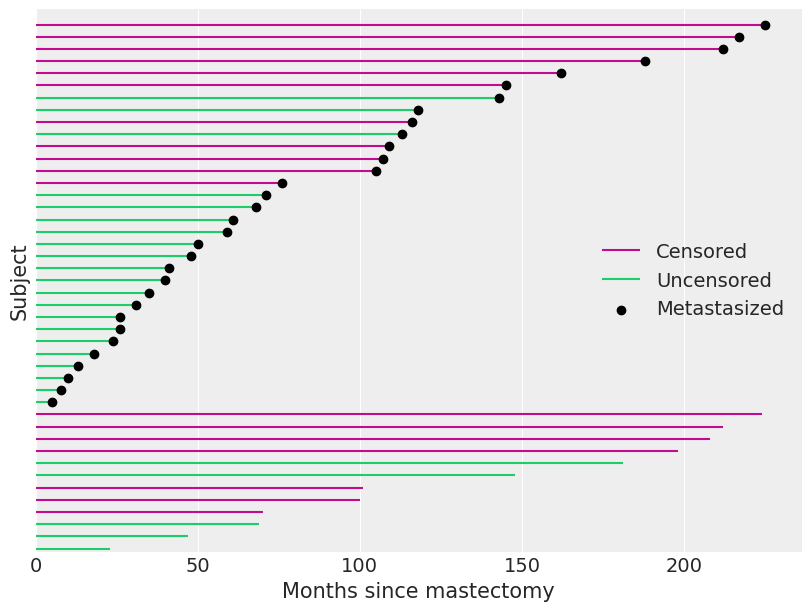
When an observation is censored (df.event is zero), df.time is not the subject’s survival time. All we can conclude from such a censored observation is that the subject’s true survival time exceeds df.time.
This is enough basic survival analysis theory for the purposes of this tutorial; for a more extensive introduction, consult Aalen et al.^[Aalen, Odd, Ornulf Borgan, and Hakon Gjessing. Survival and event history analysis: a process point of view. Springer Science & Business Media, 2008.]
Bayesian proportional hazards model#
The two most basic estimators in survival analysis are the Kaplan-Meier estimator of the survival function and the Nelson-Aalen estimator of the cumulative hazard function. However, since we want to understand the impact of metastization on survival time, a risk regression model is more appropriate. Perhaps the most commonly used risk regression model is Cox’s proportional hazards model. In this model, if we have covariates \(\mathbf{x}\) and regression coefficients \(\beta\), the hazard rate is modeled as
Here \(\lambda_0(t)\) is the baseline hazard, which is independent of the covariates \(\mathbf{x}\). In this example, the covariates are the one-dimensional vector df.metastasized.
Unlike in many regression situations, \(\mathbf{x}\) should not include a constant term corresponding to an intercept. If \(\mathbf{x}\) includes a constant term corresponding to an intercept, the model becomes unidentifiable. To illustrate this unidentifiability, suppose that
If \(\tilde{\beta}_0 = \beta_0 + \delta\) and \(\tilde{\lambda}_0(t) = \lambda_0(t) \exp(-\delta)\), then \(\lambda(t) = \tilde{\lambda}_0(t) \exp(\tilde{\beta}_0 + \mathbf{x} \beta)\) as well, making the model with \(\beta_0\) unidentifiable.
In order to perform Bayesian inference with the Cox model, we must specify priors on \(\beta\) and \(\lambda_0(t)\). We place a normal prior on \(\beta\), \(\beta \sim N(\mu_{\beta}, \sigma_{\beta}^2),\) where \(\mu_{\beta} \sim N(0, 10^2)\) and \(\sigma_{\beta} \sim U(0, 10)\).
A suitable prior on \(\lambda_0(t)\) is less obvious. We choose a semiparametric prior, where \(\lambda_0(t)\) is a piecewise constant function. This prior requires us to partition the time range in question into intervals with endpoints \(0 \leq s_1 < s_2 < \cdots < s_N\). With this partition, \(\lambda_0 (t) = \lambda_j\) if \(s_j \leq t < s_{j + 1}\). With \(\lambda_0(t)\) constrained to have this form, all we need to do is choose priors for the \(N - 1\) values \(\lambda_j\). We use independent vague priors \(\lambda_j \sim \operatorname{Gamma}(10^{-2}, 10^{-2}).\) For our mastectomy example, we make each interval three months long.
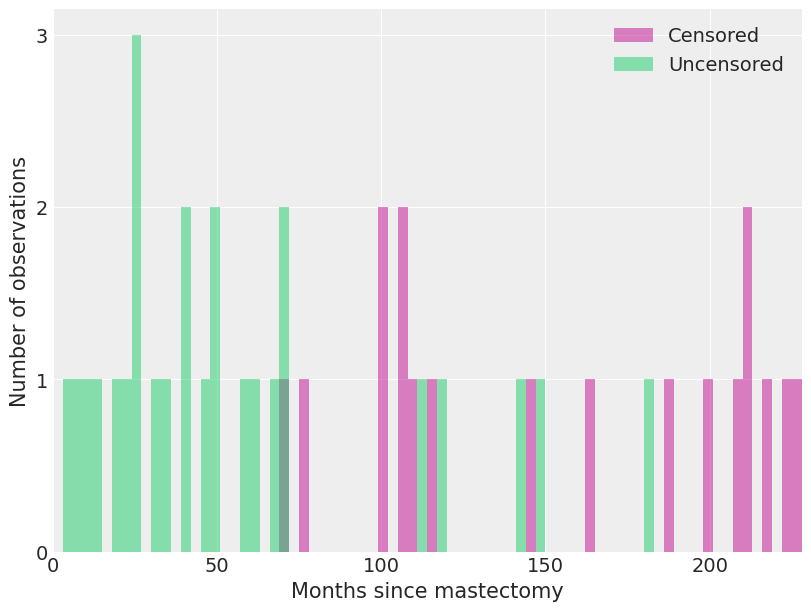
We see how deaths and censored observations are distributed in these intervals.
fig, ax = plt.subplots(figsize=(8, 6))
ax.hist(
df[df.event == 0].time.values,
bins=interval_bounds,
lw=0,
color="C3",
alpha=0.5,
label="Censored",
)
ax.hist(
df[df.event == 1].time.values,
bins=interval_bounds,
lw=0,
color="C7",
alpha=0.5,
label="Uncensored",
)
ax.set_xlim(0, interval_bounds[-1])
ax.set_xlabel("Months since mastectomy")
ax.set_yticks([0, 1, 2, 3])
ax.set_ylabel("Number of observations")
ax.legend();
With the prior distributions on \(\beta\) and \(\lambda_0(t)\) chosen, we now show how the model may be fit using MCMC simulation with pymc. The key observation is that the piecewise-constant proportional hazard model is closely related to a Poisson regression model. (The models are not identical, but their likelihoods differ by a factor that depends only on the observed data and not the parameters \(\beta\) and \(\lambda_j\). For details, see Germán Rodríguez’s WWS 509 course notes.)
We define indicator variables based on whether the \(i\)-th subject died in the \(j\)-th interval,
We also define \(t_{i, j}\) to be the amount of time the \(i\)-th subject was at risk in the \(j\)-th interval.
exposure = np.greater_equal.outer(df.time.to_numpy(), interval_bounds[:-1]) * interval_length
exposure[patients, last_period] = df.time - interval_bounds[last_period]
Finally, denote the risk incurred by the \(i\)-th subject in the \(j\)-th interval as \(\lambda_{i, j} = \lambda_j \exp(\mathbf{x}_i \beta)\).
We may approximate \(d_{i, j}\) with a Poisson random variable with mean \(t_{i, j}\ \lambda_{i, j}\). This approximation leads to the following pymc model.
coords = {"intervals": intervals}
with pm.Model(coords=coords) as model:
lambda0 = pm.Gamma("lambda0", 0.01, 0.01, dims="intervals")
beta = pm.Normal("beta", 0, sigma=1000)
lambda_ = pm.Deterministic("lambda_", T.outer(T.exp(beta * df.metastasized), lambda0))
mu = pm.Deterministic("mu", exposure * lambda_)
obs = pm.Poisson("obs", mu, observed=death)
We now sample from the model.
n_samples = 1000
n_tune = 1000
with model:
idata = pm.sample(
n_samples,
tune=n_tune,
target_accept=0.99,
random_seed=RANDOM_SEED,
)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [lambda0, beta]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 304 seconds.
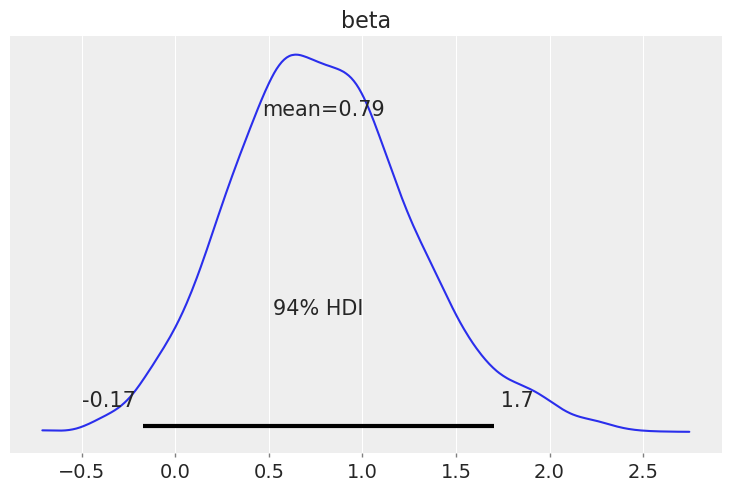
We see that the hazard rate for subjects whose cancer has metastasized is about one and a half times the rate of those whose cancer has not metastasized.
np.exp(idata.posterior["beta"]).mean()
<xarray.DataArray 'beta' ()> array(2.51161491)
az.plot_posterior(idata, var_names=["beta"]);
az.plot_autocorr(idata, var_names=["beta"]);

We now examine the effect of metastization on both the cumulative hazard and on the survival function.
base_hazard = idata.posterior["lambda0"]
met_hazard = idata.posterior["lambda0"] * np.exp(idata.posterior["beta"])
def cum_hazard(hazard):
return (interval_length * hazard).cumsum(axis=-1)
def survival(hazard):
return np.exp(-cum_hazard(hazard))
def get_mean(trace):
return trace.mean(("chain", "draw"))
fig, (hazard_ax, surv_ax) = plt.subplots(ncols=2, sharex=True, sharey=False, figsize=(16, 6))
az.plot_hdi(
interval_bounds[:-1],
cum_hazard(base_hazard),
ax=hazard_ax,
smooth=False,
color="C0",
fill_kwargs={"label": "Had not metastasized"},
)
az.plot_hdi(
interval_bounds[:-1],
cum_hazard(met_hazard),
ax=hazard_ax,
smooth=False,
color="C1",
fill_kwargs={"label": "Metastasized"},
)
hazard_ax.plot(interval_bounds[:-1], get_mean(cum_hazard(base_hazard)), color="darkblue")
hazard_ax.plot(interval_bounds[:-1], get_mean(cum_hazard(met_hazard)), color="maroon")
hazard_ax.set_xlim(0, df.time.max())
hazard_ax.set_xlabel("Months since mastectomy")
hazard_ax.set_ylabel(r"Cumulative hazard $\Lambda(t)$")
hazard_ax.legend(loc=2)
az.plot_hdi(interval_bounds[:-1], survival(base_hazard), ax=surv_ax, smooth=False, color="C0")
az.plot_hdi(interval_bounds[:-1], survival(met_hazard), ax=surv_ax, smooth=False, color="C1")
surv_ax.plot(interval_bounds[:-1], get_mean(survival(base_hazard)), color="darkblue")
surv_ax.plot(interval_bounds[:-1], get_mean(survival(met_hazard)), color="maroon")
surv_ax.set_xlim(0, df.time.max())
surv_ax.set_xlabel("Months since mastectomy")
surv_ax.set_ylabel("Survival function $S(t)$")
fig.suptitle("Bayesian survival model");
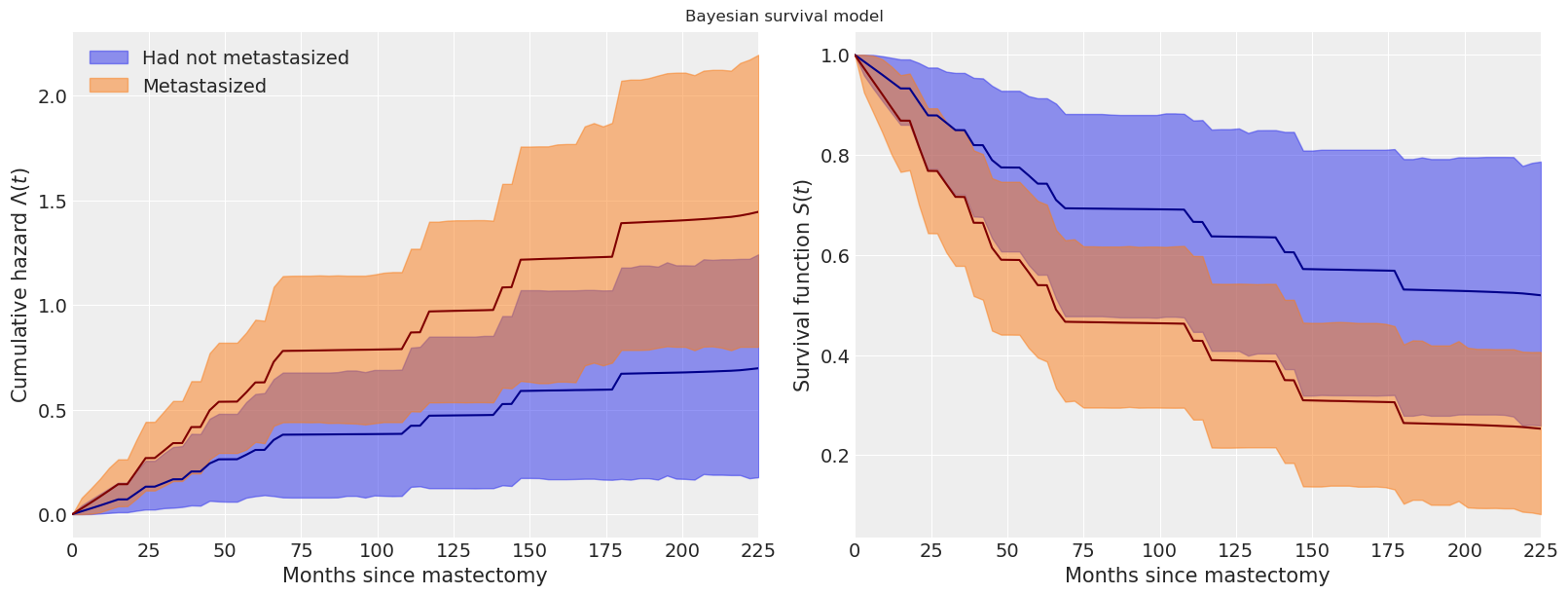
We see that the cumulative hazard for metastasized subjects increases more rapidly initially (through about seventy months), after which it increases roughly in parallel with the baseline cumulative hazard.
These plots also show the pointwise 95% high posterior density interval for each function. One of the distinct advantages of the Bayesian model fit with pymc is the inherent quantification of uncertainty in our estimates.
Time varying effects#
Another of the advantages of the model we have built is its flexibility. From the plots above, we may reasonable believe that the additional hazard due to metastization varies over time; it seems plausible that cancer that has metastasized increases the hazard rate immediately after the mastectomy, but that the risk due to metastization decreases over time. We can accommodate this mechanism in our model by allowing the regression coefficients to vary over time. In the time-varying coefficient model, if \(s_j \leq t < s_{j + 1}\), we let \(\lambda(t) = \lambda_j \exp(\mathbf{x} \beta_j).\) The sequence of regression coefficients \(\beta_1, \beta_2, \ldots, \beta_{N - 1}\) form a normal random walk with \(\beta_1 \sim N(0, 1)\), \(\beta_j\ |\ \beta_{j - 1} \sim N(\beta_{j - 1}, 1)\).
We implement this model in pymc as follows.
coords = {"intervals": intervals}
with pm.Model(coords=coords) as time_varying_model:
lambda0 = pm.Gamma("lambda0", 0.01, 0.01, dims="intervals")
beta = GaussianRandomWalk("beta", init_dist=pm.Normal.dist(), sigma=1.0, dims="intervals")
lambda_ = pm.Deterministic("h", lambda0 * T.exp(T.outer(T.constant(df.metastasized), beta)))
mu = pm.Deterministic("mu", exposure * lambda_)
obs = pm.Poisson("obs", mu, observed=death)
We proceed to sample from this model.
with time_varying_model:
time_varying_idata = pm.sample(
n_samples,
tune=n_tune,
return_inferencedata=True,
target_accept=0.99,
random_seed=RANDOM_SEED,
)
/home/cfonnesbeck/GitHub/pymc/pymc/logprob/joint_logprob.py:167: UserWarning: Found a random variable that was neither among the observations nor the conditioned variables: [normal_rv{0, (0, 0), floatX, False}.0, normal_rv{0, (0, 0), floatX, False}.out]
warnings.warn(
/home/cfonnesbeck/GitHub/pymc/pymc/logprob/joint_logprob.py:167: UserWarning: Found a random variable that was neither among the observations nor the conditioned variables: [normal_rv{0, (0, 0), floatX, False}.0, normal_rv{0, (0, 0), floatX, False}.out]
warnings.warn(
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
/home/cfonnesbeck/GitHub/pymc/pymc/logprob/joint_logprob.py:167: UserWarning: Found a random variable that was neither among the observations nor the conditioned variables: [normal_rv{0, (0, 0), floatX, False}.0, normal_rv{0, (0, 0), floatX, False}.out]
warnings.warn(
/home/cfonnesbeck/GitHub/pymc/pymc/logprob/joint_logprob.py:167: UserWarning: Found a random variable that was neither among the observations nor the conditioned variables: [normal_rv{0, (0, 0), floatX, False}.0, normal_rv{0, (0, 0), floatX, False}.out]
warnings.warn(
/home/cfonnesbeck/GitHub/pymc/pymc/logprob/joint_logprob.py:167: UserWarning: Found a random variable that was neither among the observations nor the conditioned variables: [normal_rv{0, (0, 0), floatX, False}.0, normal_rv{0, (0, 0), floatX, False}.out]
warnings.warn(
/home/cfonnesbeck/GitHub/pymc/pymc/logprob/joint_logprob.py:167: UserWarning: Found a random variable that was neither among the observations nor the conditioned variables: [normal_rv{0, (0, 0), floatX, False}.0, normal_rv{0, (0, 0), floatX, False}.out]
warnings.warn(
/home/cfonnesbeck/GitHub/pymc/pymc/logprob/joint_logprob.py:167: UserWarning: Found a random variable that was neither among the observations nor the conditioned variables: [normal_rv{0, (0, 0), floatX, False}.0, normal_rv{0, (0, 0), floatX, False}.out]
warnings.warn(
/home/cfonnesbeck/GitHub/pymc/pymc/logprob/joint_logprob.py:167: UserWarning: Found a random variable that was neither among the observations nor the conditioned variables: [normal_rv{0, (0, 0), floatX, False}.0, normal_rv{0, (0, 0), floatX, False}.out]
warnings.warn(
/home/cfonnesbeck/GitHub/pymc/pymc/logprob/joint_logprob.py:167: UserWarning: Found a random variable that was neither among the observations nor the conditioned variables: [normal_rv{0, (0, 0), floatX, False}.0, normal_rv{0, (0, 0), floatX, False}.out]
warnings.warn(
/home/cfonnesbeck/GitHub/pymc/pymc/logprob/joint_logprob.py:167: UserWarning: Found a random variable that was neither among the observations nor the conditioned variables: [normal_rv{0, (0, 0), floatX, False}.0, normal_rv{0, (0, 0), floatX, False}.out]
warnings.warn(
/home/cfonnesbeck/GitHub/pymc/pymc/logprob/joint_logprob.py:167: UserWarning: Found a random variable that was neither among the observations nor the conditioned variables: [normal_rv{0, (0, 0), floatX, False}.0, normal_rv{0, (0, 0), floatX, False}.out]
warnings.warn(
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [lambda0, beta]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 536 seconds.
az.plot_forest(time_varying_idata, var_names=["beta"]);

We see from the plot of \(\beta_j\) over time below that initially \(\beta_j > 0\), indicating an elevated hazard rate due to metastization, but that this risk declines as \(\beta_j < 0\) eventually.
fig, ax = plt.subplots(figsize=(8, 6))
beta_eti = time_varying_idata.posterior["beta"].quantile((0.025, 0.975), dim=("chain", "draw"))
beta_eti_low = beta_eti.sel(quantile=0.025)
beta_eti_high = beta_eti.sel(quantile=0.975)
ax.fill_between(interval_bounds[:-1], beta_eti_low, beta_eti_high, color="C0", alpha=0.25)
beta_hat = time_varying_idata.posterior["beta"].mean(("chain", "draw"))
ax.step(interval_bounds[:-1], beta_hat, color="C0")
ax.scatter(
interval_bounds[last_period[(df.event.values == 1) & (df.metastasized == 1)]],
beta_hat.isel(intervals=last_period[(df.event.values == 1) & (df.metastasized == 1)]),
color="C1",
zorder=10,
label="Died, cancer metastasized",
)
ax.scatter(
interval_bounds[last_period[(df.event.values == 0) & (df.metastasized == 1)]],
beta_hat.isel(intervals=last_period[(df.event.values == 0) & (df.metastasized == 1)]),
color="C0",
zorder=10,
label="Censored, cancer metastasized",
)
ax.set_xlim(0, df.time.max())
ax.set_xlabel("Months since mastectomy")
ax.set_ylabel(r"$\beta_j$")
ax.legend();
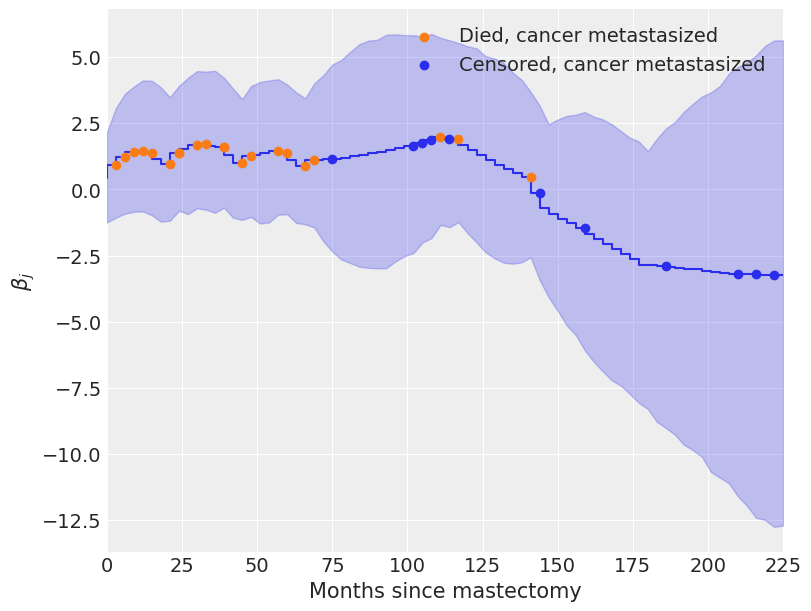
The coefficients \(\beta_j\) begin declining rapidly around one hundred months post-mastectomy, which seems reasonable, given that only three of twelve subjects whose cancer had metastasized lived past this point died during the study.
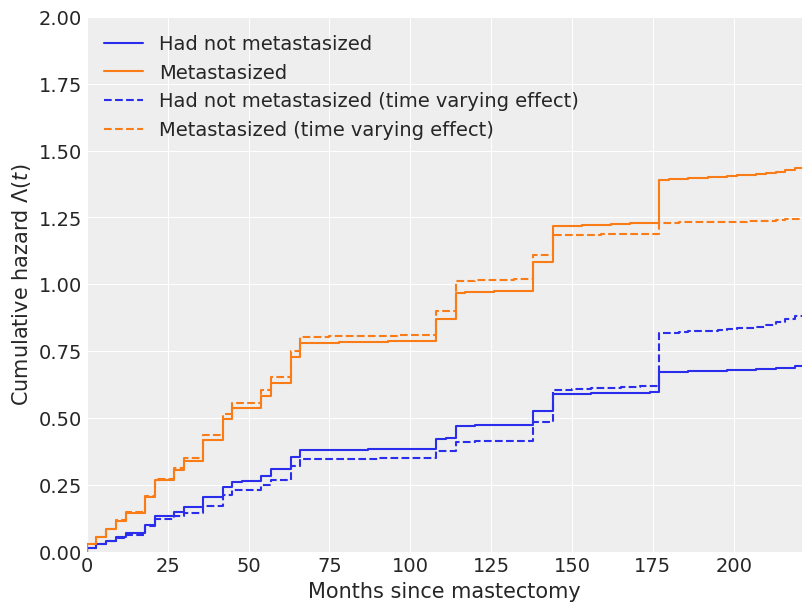
The change in our estimate of the cumulative hazard and survival functions due to time-varying effects is also quite apparent in the following plots.
tv_base_hazard = time_varying_idata.posterior["lambda0"]
tv_met_hazard = time_varying_idata.posterior["lambda0"] * np.exp(
time_varying_idata.posterior["beta"]
)
fig, ax = plt.subplots(figsize=(8, 6))
ax.step(
interval_bounds[:-1],
cum_hazard(base_hazard.mean(("chain", "draw"))),
color="C0",
label="Had not metastasized",
)
ax.step(
interval_bounds[:-1],
cum_hazard(met_hazard.mean(("chain", "draw"))),
color="C1",
label="Metastasized",
)
ax.step(
interval_bounds[:-1],
cum_hazard(tv_base_hazard.mean(("chain", "draw"))),
color="C0",
linestyle="--",
label="Had not metastasized (time varying effect)",
)
ax.step(
interval_bounds[:-1],
cum_hazard(tv_met_hazard.mean(dim=("chain", "draw"))),
color="C1",
linestyle="--",
label="Metastasized (time varying effect)",
)
ax.set_xlim(0, df.time.max() - 4)
ax.set_xlabel("Months since mastectomy")
ax.set_ylim(0, 2)
ax.set_ylabel(r"Cumulative hazard $\Lambda(t)$")
ax.legend(loc=2);
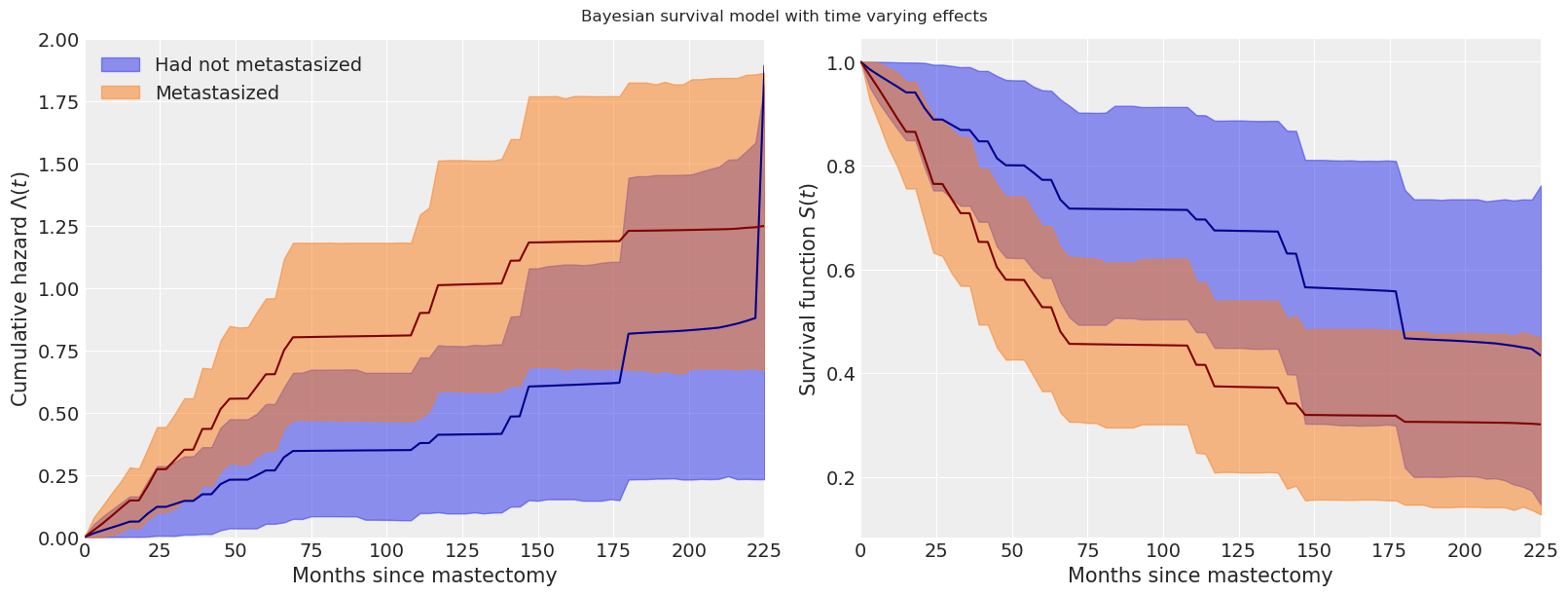
fig, (hazard_ax, surv_ax) = plt.subplots(ncols=2, sharex=True, sharey=False, figsize=(16, 6))
az.plot_hdi(
interval_bounds[:-1],
cum_hazard(tv_base_hazard),
ax=hazard_ax,
color="C0",
smooth=False,
fill_kwargs={"label": "Had not metastasized"},
)
az.plot_hdi(
interval_bounds[:-1],
cum_hazard(tv_met_hazard),
ax=hazard_ax,
smooth=False,
color="C1",
fill_kwargs={"label": "Metastasized"},
)
hazard_ax.plot(interval_bounds[:-1], get_mean(cum_hazard(tv_base_hazard)), color="darkblue")
hazard_ax.plot(interval_bounds[:-1], get_mean(cum_hazard(tv_met_hazard)), color="maroon")
hazard_ax.set_xlim(0, df.time.max())
hazard_ax.set_xlabel("Months since mastectomy")
hazard_ax.set_ylim(0, 2)
hazard_ax.set_ylabel(r"Cumulative hazard $\Lambda(t)$")
hazard_ax.legend(loc=2)
az.plot_hdi(interval_bounds[:-1], survival(tv_base_hazard), ax=surv_ax, smooth=False, color="C0")
az.plot_hdi(interval_bounds[:-1], survival(tv_met_hazard), ax=surv_ax, smooth=False, color="C1")
surv_ax.plot(interval_bounds[:-1], get_mean(survival(tv_base_hazard)), color="darkblue")
surv_ax.plot(interval_bounds[:-1], get_mean(survival(tv_met_hazard)), color="maroon")
surv_ax.set_xlim(0, df.time.max())
surv_ax.set_xlabel("Months since mastectomy")
surv_ax.set_ylabel("Survival function $S(t)$")
fig.suptitle("Bayesian survival model with time varying effects");
We have really only scratched the surface of both survival analysis and the Bayesian approach to survival analysis. More information on Bayesian survival analysis is available in Ibrahim et al. (2005). (For example, we may want to account for individual frailty in either or original or time-varying models.)
This tutorial is available as an IPython notebook here. It is adapted from a blog post that first appeared here.
License notice#
All the notebooks in this example gallery are provided under the MIT License which allows modification, and redistribution for any use provided the copyright and license notices are preserved.
Citing PyMC examples#
To cite this notebook, use the DOI provided by Zenodo for the pymc-examples repository.
Important
Many notebooks are adapted from other sources: blogs, books… In such cases you should cite the original source as well.
Also remember to cite the relevant libraries used by your code.
Here is an citation template in bibtex:
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
which once rendered could look like: