
Posted in 2022
GLM: Poisson Regression
- 30 November 2022
This is a minimal reproducible example of Poisson regression to predict counts using dummy data.
Bayesian Vector Autoregressive Models
- 09 November 2022
Duplicate implicit target name: “bayesian vector autoregressive models”.
A Primer on Bayesian Methods for Multilevel Modeling
- 24 October 2022
Hierarchical or multilevel modeling is a generalization of regression modeling.
Forecasting with Structural AR Timeseries
- 20 October 2022
Bayesian structural timeseries models are an interesting way to learn about the structure inherent in any observed timeseries data. It also gives us the ability to project forward the implied predictive distribution granting us another view on forecasting problems. We can treat the learned characteristics of the timeseries data observed to-date as informative about the structure of the unrealised future state of the same measure.
Multi-output Gaussian Processes: Coregionalization models using Hamadard product
- 09 October 2022
This notebook shows how to implement the Intrinsic Coregionalization Model (ICM) and the Linear Coregionalization Model (LCM) using a Hamadard product between the Coregion kernel and input kernels. Multi-output Gaussian Process is discussed in this paper by Bonilla et al. [2007]. For further information about ICM and LCM, please check out the talk on Multi-output Gaussian Processes by Mauricio Alvarez, and his slides with more references at the last page.
Kronecker Structured Covariances
- 09 October 2022
PyMC contains implementations for models that have Kronecker structured covariances. This patterned structure enables Gaussian process models to work on much larger datasets. Kronecker structure can be exploited when
Interrupted time series analysis
- 09 October 2022
This notebook focuses on how to conduct a simple Bayesian interrupted time series analysis. This is useful in quasi-experimental settings where an intervention was applied to all treatment units.
Generalized Extreme Value Distribution
- 27 September 2022
The Generalized Extreme Value (GEV) distribution is a meta-distribution containing the Weibull, Gumbel, and Frechet families of extreme value distributions. It is used for modelling the distribution of extremes (maxima or minima) of stationary processes, such as the annual maximum wind speed, annual maximum truck weight on a bridge, and so on, without needing a priori decision on the tail behaviour.
Difference in differences
- 09 September 2022
This notebook provides a brief overview of the difference in differences approach to causal inference, and shows a working example of how to conduct this type of analysis under the Bayesian framework, using PyMC. While the notebooks provides a high level overview of the approach, I recommend consulting two excellent textbooks on causal inference. Both The Effect [Huntington-Klein, 2021] and Causal Inference: The Mixtape [Cunningham, 2021] have chapters devoted to difference in differences.
Bayesian regression with truncated or censored data
- 09 September 2022
The notebook provides an example of how to conduct linear regression when your outcome variable is either censored or truncated.
Fitting a Reinforcement Learning Model to Behavioral Data with PyMC
- 05 August 2022
Reinforcement Learning models are commonly used in behavioral research to model how animals and humans learn, in situtions where they get to make repeated choices that are followed by some form of feedback, such as a reward or a punishment.
How to debug a model
- 02 August 2022
There are various levels on which to debug a model. One of the simplest is to just print out the values that different variables are taking on.
Gaussian Processes using numpy kernel
- 31 July 2022
Example of simple Gaussian Process fit, adapted from Stan’s example-models repository.
Conditional Autoregressive (CAR) Models for Spatial Data
- 29 July 2022
This notebook uses libraries that are not PyMC dependencies and therefore need to be installed specifically to run this notebook. Open the dropdown below for extra guidance.
Counterfactual inference: calculating excess deaths due to COVID-19
- 09 July 2022
Causal reasoning and counterfactual thinking are really interesting but complex topics! Nevertheless, we can make headway into understanding the ideas through relatively simple examples. This notebook focuses on the concepts and the practical implementation of Bayesian causal reasoning using PyMC.
Stochastic Volatility model
- 17 June 2022
Asset prices have time-varying volatility (variance of day over day returns). In some periods, returns are highly variable, while in others very stable. Stochastic volatility models model this with a latent volatility variable, modeled as a stochastic process. The following model is similar to the one described in the No-U-Turn Sampler paper, [Hoffman and Gelman, 2014].
Splines
- 04 June 2022
Often, the model we want to fit is not a perfect line between some \(x\) and \(y\). Instead, the parameters of the model are expected to vary over \(x\). There are multiple ways to handle this situation, one of which is to fit a spline. Spline fit is effectively a sum of multiple individual curves (piecewise polynomials), each fit to a different section of \(x\), that are tied together at their boundaries, often called knots.
Probabilistic Matrix Factorization for Making Personalized Recommendations
- 03 June 2022
So you are browsing for something to watch on Netflix and just not liking the suggestions. You just know you can do better. All you need to do is collect some ratings data from yourself and friends and build a recommendation algorithm. This notebook will guide you in doing just that!
Sampler Statistics
- 31 May 2022
When checking for convergence or when debugging a badly behaving sampler, it is often helpful to take a closer look at what the sampler is doing. For this purpose some samplers export statistics for each generated sample.
General API quickstart
- 31 May 2022
Models in PyMC are centered around the Model class. It has references to all random variables (RVs) and computes the model logp and its gradients. Usually, you would instantiate it as part of a with context:
Approximate Bayesian Computation
- 31 May 2022
Approximate Bayesian Computation methods (also called likelihood free inference methods), are a group of techniques developed for inferring posterior distributions in cases where the likelihood function is intractable or costly to evaluate. This does not mean that the likelihood function is not part of the analysis, it just the we are approximating the likelihood, and hence the name of the ABC methods.
Variational Inference: Bayesian Neural Networks
- 30 May 2022
Probabilistic Programming, Deep Learning and “Big Data” are among the biggest topics in machine learning. Inside of PP, a lot of innovation is focused on making things scale using Variational Inference. In this example, I will show how to use Variational Inference in PyMC to fit a simple Bayesian Neural Network. I will also discuss how bridging Probabilistic Programming and Deep Learning can open up very interesting avenues to explore in future research.
Censored Data Models
- 09 May 2022
This example notebook on Bayesian survival analysis touches on the point of censored data. Censoring is a form of missing-data problem, in which observations greater than a certain threshold are clipped down to that threshold, or observations less than a certain threshold are clipped up to that threshold, or both. These are called right, left and interval censoring,respectively. In this example notebook we consider interval censoring.
NBA Foul Analysis with Item Response Theory
- 17 April 2022
This tutorial shows an application of Bayesian Item Response Theory [Fox, 2010] to NBA basketball foul calls data using PyMC. Based on Austin Rochford’s blogpost NBA Foul Calls and Bayesian Item Response Theory.
Regression discontinuity design analysis
- 09 April 2022
Quasi experiments involve experimental interventions and quantitative measures. However, quasi-experiments do not involve random assignment of units (e.g. cells, people, companies, schools, states) to test or control groups. This inability to conduct random assignment poses problems when making causal claims as it makes it harder to argue that any difference between a control and test group are because of an intervention and not because of a confounding factor.
Gaussian Process for CO2 at Mauna Loa
- 09 April 2022
This Gaussian Process (GP) example shows how to:
Gaussian Mixture Model
- 09 April 2022
A mixture model allows us to make inferences about the component contributors to a distribution of data. More specifically, a Gaussian Mixture Model allows us to make inferences about the means and standard deviations of a specified number of underlying component Gaussian distributions.
Air passengers - Prophet-like model
- 09 April 2022
We’re going to look at the “air passengers” dataset, which tracks the monthly totals of a US airline passengers from 1949 to 1960. We could fit this using the Prophet model [Taylor and Letham, 2018] (indeed, this dataset is one of the examples they provide in their documentation), but instead we’ll make our own Prophet-like model in PyMC3. This will make it a lot easier to inspect the model’s components and to do prior predictive checks (an integral component of the Bayesian workflow [Gelman et al., 2020]).
Model building and expansion for golf putting
- 02 April 2022
This uses and closely follows the case study from Andrew Gelman, written in Stan. There are some new visualizations and we steered away from using improper priors, but much credit to him and to the Stan group for the wonderful case study and software.
How to wrap a JAX function for use in PyMC
- 24 March 2022
This notebook uses libraries that are not PyMC dependencies and therefore need to be installed specifically to run this notebook. Open the dropdown below for extra guidance.
Mean and Covariance Functions
- 22 March 2022
A large set of mean and covariance functions are available in PyMC. It is relatively easy to define custom mean and covariance functions. Since PyMC uses PyTensor, their gradients do not need to be defined by the user.
Factor analysis
- 19 March 2022
Factor analysis is a widely used probabilistic model for identifying low-rank structure in multivariate data as encoded in latent variables. It is very closely related to principal components analysis, and differs only in the prior distributions assumed for these latent variables. It is also a good example of a linear Gaussian model as it can be described entirely as a linear transformation of underlying Gaussian variates. For a high-level view of how factor analysis relates to other models, you can check out this diagram originally published by Ghahramani and Roweis.
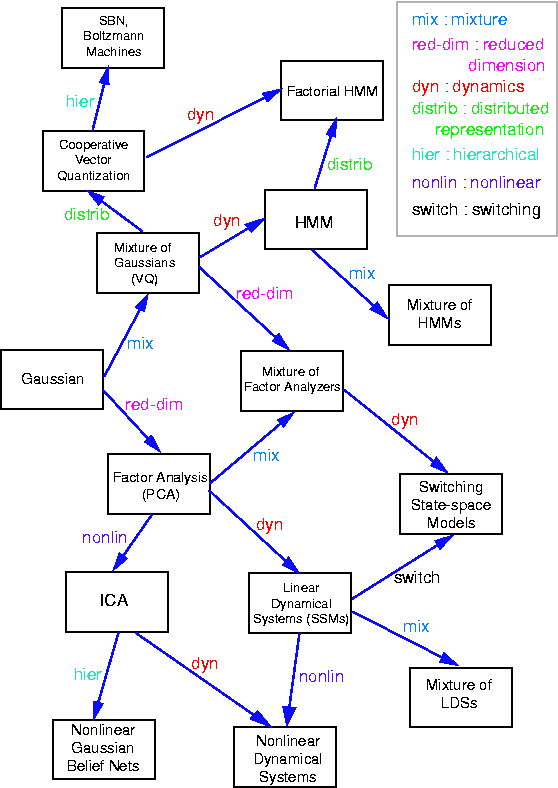{kind=link}
A Hierarchical model for Rugby prediction
- 19 March 2022
In this example, we’re going to reproduce the first model described in Baio and Blangiardo [2010] using PyMC. Then show how to sample from the posterior predictive to simulate championship outcomes from the scored goals which are the modeled quantities.
Bayesian moderation analysis
- 09 March 2022
This notebook covers Bayesian moderation analysis. This is appropriate when we believe that one predictor variable (the moderator) may influence the linear relationship between another predictor variable and an outcome. Here we look at an example where we look at the relationship between hours of training and muscle mass, where it may be that age (the moderating variable) affects this relationship.
Lasso regression with block updating
- 10 February 2022
Sometimes, it is very useful to update a set of parameters together. For example, variables that are highly correlated are often good to update together. In PyMC block updating is simple. This will be demonstrated using the parameter step of pymc.sample.
Binomial regression
- 09 February 2022
This notebook covers the logic behind Binomial regression, a specific instance of Generalized Linear Modelling. The example is kept very simple, with a single predictor variable.
Bayesian mediation analysis
- 09 February 2022
This notebook covers Bayesian mediation analysis. This is useful when we want to explore possible mediating pathways between a predictor and an outcome variable.
GLM: Model Selection
- 08 January 2022
A fairly minimal reproducible example of Model Selection using WAIC, and LOO as currently implemented in PyMC.
Dirichlet mixtures of multinomials
- 08 January 2022
This example notebook demonstrates the use of a Dirichlet mixture of multinomials (a.k.a Dirichlet-multinomial or DM) to model categorical count data. Models like this one are important in a variety of areas, including natural language processing, ecology, bioinformatics, and more.
Bayesian Estimation Supersedes the T-Test
- 07 January 2022
Non-consecutive header level increase; H1 to H3 [myst.header]