



Sensitivity Analysis for Unmeasured Confounding#

The experimentation lifecycle as a Bosch triptych. Left, Bayesian Assurance: before any data arrive, the planner reads possible effects from the prior and asks what the experiment will likely conclude. Centre, Sensitivity Analysis (this notebook): a single experiment is wracked by the biases it cannot rule out, and the model is contorted to see which commitments its conclusion can survive. Right, Meta-Analysis: many experiments are pooled through a hierarchy of levels into a synthesis that becomes the next plan’s prior. Three panels, one posterior machinery.#
All applied inference is argument. Against every experiment you can set the contention that the working conditions were imperfect. Some aspect of the evaluation was flawed. Maybe treatment assignment introduced a subtle kind of bias, or the subjects didn’t comply fully with the design. Against every experiment you can contrast the scientific ideal of perfect randomisation and clear adherence. Holding an experiment against that ideal is due diligence. Sensitivity analysis does it systematically, by varying how far the working conditions fall short of perfect randomisation.
The randomisation gap#
Randomisation is an assumption you maintain by design, not a fact you assert by intention. The checkout experiment ran, the headline effect on revenue-per-visitor looks positive, and somewhere in the diagnostic notes there is a line about compliance being 73%: users on slow connections were silently routed back to the old flow by a CDN edge case, and the routing was not random in the way it touched the population. The intent-to-treat estimate now depends on a counterfactual the experiment did not produce: what those users would have done under the new flow. Without further assumptions, the data cannot say what the treatment effect would have been if randomisation had held.
This notebook develops the Bayesian response to this situation. Where Rosenbaum’s \(\Gamma\) [Rosenbaum, 2002] and the E-value [VanderWeele and Ding, 2017] give point summaries of how strong an unmeasured confounder would need to be to nullify the result, the Bayesian framing makes the same unmeasured confounder a parameter in the model, with a prior over its plausible strength and a posterior shaped by both the data and the analyst’s commitments [Imbens, 2003], [Cinelli and Hazlett, 2020]. We develop the machinery on a continuous outcome (revenue per visitor) and then re-run it on a binary outcome (conversion). This is the second of three notebooks on the lifecycle of a Bayesian experiment; see Assurance Planning via Simulation for the planning counterpart and Multiple Experiments and Bayesian Meta-analysis for the synthesis counterpart. The clean primary analysis of a well-run experiment, the posterior on the effect with the decision rule applied, appears as the demonstration step in Assurance Planning via Simulation; this notebook takes up the interpretation once that clean identification is itself in question.
Where this lands in regulatory practice
The sensitivity construction here follows the regulatory recommendation directly. The FDA’s 2026 draft guidance on Bayesian methodology in clinical trials describes sensitivity analysis as varying the prior over a critical assumption, and notes that “some approaches can build uncertainty about specific assumptions into the prior itself” [U.S. Food and Drug Administration, 2026], which is the move made below. The guidance goes further and sanctions modelling a discrepancy between data sources with “an assumed bias parameter in the model”, the exact object this notebook places a prior on and sweeps. The clinical-trial setting differs from a product quasi-experiment; the bias parameter is the same.
import warnings
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
warnings.filterwarnings("ignore", category=RuntimeWarning)
warnings.filterwarnings("ignore", category=UserWarning)
%config InlineBackend.figure_format = 'retina'
az.style.use("arviz-variat")
rng = np.random.default_rng(7)
RANDOM_SEED = 7
What the data can and cannot say#
The structural picture is small and the notation traditional. Let \(T\) be the observed treatment indicator (which flow the visitor actually saw), let \(Y\) be the outcome (revenue), and let \(U\) be an unmeasured user characteristic: connection quality, engagement disposition, whatever drives the differential compliance. Under randomisation \(U\) is independent of \(T\) by construction; under compliance failure \(U\) is associated with \(T\) and unobservable.
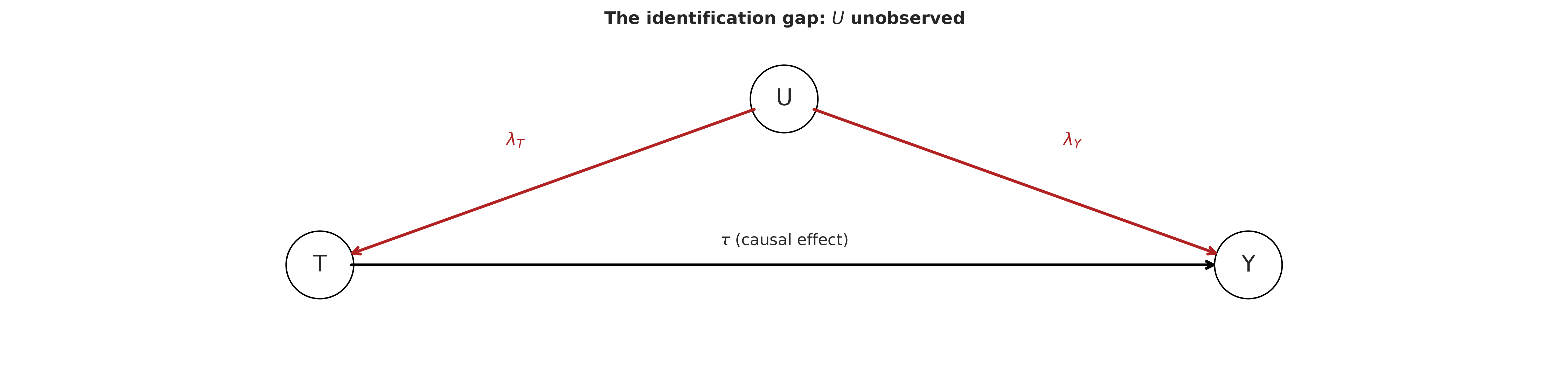
What we want is \(\tau\), the causal effect of \(T\) on \(Y\). What the data identify is \(\tau\) plus the contribution of any path that flows through \(U\): the product of the two red edges, collected into a single bias term \(\beta = \lambda_T \cdot \lambda_Y / \mathrm{var}(T)\) at the scale of the observed difference in means [Hernán and Robins, 2020], [Cunningham, 2021]. The naïve estimator returns \(\tau + \beta\). The data are silent on the decomposition; the prior is what sets it.
The bias parameter#
The Bayesian sensitivity analysis makes \(\beta\) a model parameter with a prior. The data inform the sum \(\tau + \beta\) through the observed difference; the prior on \(\beta\) controls how much of that sum is attributed to the unmeasured confounder rather than to the treatment. Three prior commitments:
Dismissive prior (\(\beta \sim \mathcal{N}(0, 0.05)\)): “I am confident there is essentially no confounding.”
Moderate prior (\(\beta \sim \mathcal{N}(0, 0.3)\)): “I will allow that confounding may have shifted the apparent effect by up to a few tenths of a revenue unit.”
Sceptical prior (\(\beta \sim \mathcal{N}(0, 0.7)\)): “I will not commit to confounding being small; the data must speak loudly to be heard.”
Each is an auditable commitment.
N = 4000
TRUE_TAU = 0.30
TRUE_BIAS = 0.50
SIGMA_OBS = 4.0
def simulate_quasi_experimental_gaussian(N, true_tau, true_bias, sigma_obs, rng):
baseline = 10.0
y_A = rng.normal(baseline, sigma_obs, size=N)
y_B = rng.normal(baseline + true_tau + true_bias, sigma_obs, size=N)
return y_A, y_B
y_A_obs, y_B_obs = simulate_quasi_experimental_gaussian(N, TRUE_TAU, TRUE_BIAS, SIGMA_OBS, rng)
d_hat = y_B_obs.mean() - y_A_obs.mean()
sigma_d = np.sqrt(2 * SIGMA_OBS**2 / N)
print(f"Observed difference d_hat = {d_hat:.3f} (sampling SE = {sigma_d:.3f})")
print(f"True tau = {TRUE_TAU}, true bias = {TRUE_BIAS}, true sum = {TRUE_TAU + TRUE_BIAS}")
Observed difference d_hat = 0.793 (sampling SE = 0.089)
True tau = 0.3, true bias = 0.5, true sum = 0.8
The observed difference recovers the biased effect, as it must. \(\tau\) is what we want; \(\beta\) is what we cannot observe. Before asking how a prior reshapes that sum, confirm the machinery is faithful: hand the model the belief an analyst would hold if they knew the confounder exactly, a prior on \(\beta\) centred at the true bias, and the treatment effect should return unbiased across repeated experiments.
def gaussian_sensitivity_posterior(
d_hat, sigma_d, tau_prior_sd, bias_prior_sd, tau_prior_mean=0.0, bias_prior_mean=0.0
):
"""Closed-form posterior over (tau, beta) given the observed effect."""
prior_precision = np.diag([1.0 / tau_prior_sd**2, 1.0 / bias_prior_sd**2])
F = np.array([[1.0, 1.0]])
data_precision = F.T @ F / sigma_d**2
post_precision = prior_precision + data_precision
post_cov = np.linalg.inv(post_precision)
prior_mean = np.array([tau_prior_mean, bias_prior_mean])
rhs = prior_precision @ prior_mean + F.flatten() * d_hat / sigma_d**2
post_mean = post_cov @ rhs
return post_mean, post_cov
# Across many synthetic quasi-experiments, where does the posterior mean of tau land
# when the analyst's prior on the bias is centred at the true confounding strength?
recovery_rng = np.random.default_rng(RANDOM_SEED)
n_recovery = 500
tau_posterior_means = np.empty(n_recovery)
for i in range(n_recovery):
y_A_i, y_B_i = simulate_quasi_experimental_gaussian(
N, TRUE_TAU, TRUE_BIAS, SIGMA_OBS, recovery_rng
)
d_hat_i = y_B_i.mean() - y_A_i.mean()
post_mean_i, _ = gaussian_sensitivity_posterior(
d_hat_i, sigma_d, tau_prior_sd=1.0, bias_prior_sd=0.1, bias_prior_mean=TRUE_BIAS
)
tau_posterior_means[i] = post_mean_i[0]
fig, ax = plt.subplots(figsize=(20, 4))
ax.hist(tau_posterior_means, bins=30, color="C0", alpha=0.7, edgecolor="white")
ax.axvline(TRUE_TAU, color="C2", linestyle="--", linewidth=2, label=f"true \u03c4 = {TRUE_TAU:.2f}")
ax.axvline(
tau_posterior_means.mean(),
color="C3",
linewidth=2,
label=f"mean estimate = {tau_posterior_means.mean():.3f}",
)
ax.set_xlabel(r"Posterior mean of $\tau$ across simulated experiments")
ax.set_ylabel("Frequency")
ax.set_title(r"Recovery of $\tau$ when the bias prior is correctly centred")
ax.legend();
The sampling distribution of the posterior mean sits on the true \(\tau = 0.30\): with the confounder’s strength correctly specified, the estimator is unbiased across repeated experiments. The recovery is real, but read what produced it. The data fixed the sum \(\tau + \beta\) through the observed difference; the correctly-centred prior on \(\beta\) is what split that sum into its parts. A single difference in means cannot separate a treatment effect from a confound that imitates it. The data identify the two only in combination with a commitment about the confounder. The prior is the content of that decomposition, which is why an honest analysis varies it rather than fixing it. Recentre the prior on \(\beta\) at zero, where an analyst lands by default with no oracle for the confounder’s size, and the estimate moves. The moderate prior below makes the shift concrete.
def gaussian_sensitivity_model(d_hat, sigma_d, tau_prior=(0.0, 1.0), bias_prior=(0.0, 0.3)):
with pm.Model() as model:
tau = pm.Normal("tau", mu=tau_prior[0], sigma=tau_prior[1])
beta = pm.Normal("beta", mu=bias_prior[0], sigma=bias_prior[1])
observed_effect = pm.Deterministic("observed_effect", tau + beta)
pm.Normal("d_hat", mu=observed_effect, sigma=sigma_d, observed=d_hat)
return model
with gaussian_sensitivity_model(d_hat, sigma_d, bias_prior=(0.0, 0.3)):
idata_moderate = pm.sample(
draws=2000,
tune=2000,
chains=2,
target_accept=0.95,
random_seed=RANDOM_SEED,
progressbar=False,
)
az.plot_dist(idata_moderate, var_names=["tau", "beta"])
axes = plt.gcf().axes
for a in axes:
a.set_title("")
axes[0].axvline(TRUE_TAU, color="C2", linestyle="--", label=f"true τ = {TRUE_TAU:.2f}")
axes[0].legend()
axes[1].axvline(TRUE_BIAS, color="C2", linestyle="--", label=f"true β = {TRUE_BIAS:.2f}")
axes[1].legend()
plt.suptitle(r"Posterior of $\tau$ and $\beta$ under a moderate bias prior");
NUTS[nutpie]: [tau, beta]
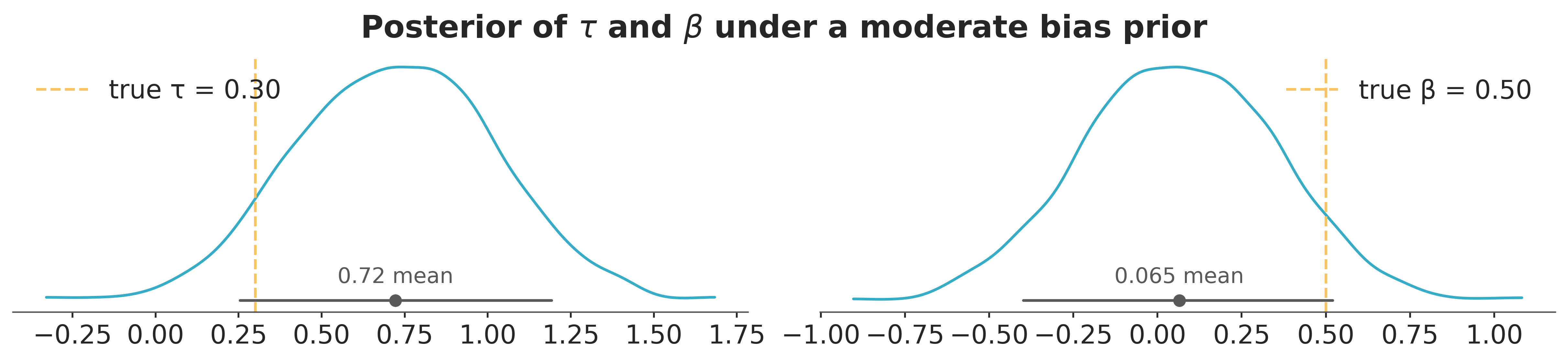
Under the moderate prior, centred at zero, the posterior of \(\tau\) is pulled well above the true 0.30 and the posterior of \(\beta\) settles near zero: with no prior reason to expect a confounder, the treatment absorbs the sum. The true \(\beta = 0.50\) falls in the prior’s right tail. The data informed the sum; the prior shaped the split.
Tipping-point analysis under a Gaussian outcome#
The model with a flat prior on \(\tau\) and a Gaussian prior on \(\beta\) is fully conjugate; the posterior is a closed-form bivariate Normal that we can compute analytically. This lets us trace the tipping point: the bias prior strength at which the posterior probability of a positive treatment effect drops below the team’s decision threshold.
# Verify the closed form agrees with MCMC under the moderate prior
post_mean_anly, post_cov_anly = gaussian_sensitivity_posterior(
d_hat, sigma_d, tau_prior_sd=1.0, bias_prior_sd=0.3
)
mcmc_summary = az.summary(idata_moderate, var_names=["tau", "beta"], kind="stats")[["mean", "sd"]]
analytical_summary = pd.DataFrame(
{"mean": post_mean_anly, "sd": np.sqrt(np.diag(post_cov_anly))},
index=["tau", "beta"],
)
pd.concat({"MCMC": mcmc_summary, "Analytical": analytical_summary}, axis=1).round(3)
| MCMC | Analytical | |||
|---|---|---|---|---|
| mean | sd | mean | sd | |
| tau | 0.72 | 0.3 | 0.722 | 0.299 |
| beta | 0.065 | 0.29 | 0.065 | 0.287 |
The two posteriors agree. The analytical form carries the sweep.
from scipy import stats
bias_sd_grid = np.linspace(0.001, 1.0, 40)
sweep_records = []
for bias_sd in bias_sd_grid:
pm_a, pc_a = gaussian_sensitivity_posterior(
d_hat, sigma_d, tau_prior_sd=1.0, bias_prior_sd=bias_sd
)
tau_mean, tau_sd = pm_a[0], np.sqrt(pc_a[0, 0])
prob_positive = 1.0 - stats.norm.cdf(0.0, loc=tau_mean, scale=tau_sd)
sweep_records.append(
{"bias_sd": bias_sd, "tau_mean": tau_mean, "tau_sd": tau_sd, "prob_positive": prob_positive}
)
sweep_df = pd.DataFrame(sweep_records)
decision_threshold = 0.95
above_threshold = sweep_df[sweep_df["prob_positive"] >= decision_threshold]
tipping_point = above_threshold["bias_sd"].max() if len(above_threshold) else np.nan
fig, axes = plt.subplots(1, 2, figsize=(20, 4))
axes[0].plot(
sweep_df["bias_sd"],
sweep_df["tau_mean"],
linewidth=2,
color="C0",
label=r"Posterior mean of $\tau$",
)
axes[0].fill_between(
sweep_df["bias_sd"],
sweep_df["tau_mean"] - sweep_df["tau_sd"],
sweep_df["tau_mean"] + sweep_df["tau_sd"],
alpha=0.25,
color="C0",
label=r"$\pm 1$ SD",
)
axes[0].axhline(0.0, color="black", linestyle=":")
axes[0].set_xlabel(r"Prior SD on bias $\beta$")
axes[0].set_ylabel(r"Posterior of $\tau$")
axes[0].set_title("Posterior shifts as the bias prior loosens")
axes[0].legend()
axes[1].plot(sweep_df["bias_sd"], sweep_df["prob_positive"], linewidth=2, color="C3")
axes[1].axhline(
decision_threshold,
color="black",
linestyle="--",
label=f"Decision threshold = {decision_threshold}",
)
if not np.isnan(tipping_point):
axes[1].axvline(
tipping_point,
color="C3",
linestyle=":",
alpha=0.7,
label=f"Tipping point ≈ {tipping_point:.2f}",
)
axes[1].set_xlabel(r"Prior SD on bias $\beta$")
axes[1].set_ylabel(r"$P(\tau > 0 \mid d_{\text{obs}})$")
axes[1].set_title("Tipping point in the decision rule")
axes[1].legend();
Read the left panel from left to right: as the analyst loosens their prior on the bias, the posterior mean of \(\tau\) drifts downward and the posterior interval widens. Read the right panel: there is a bias prior strength at which the posterior probability of a positive effect falls below the conventional decision threshold. The tipping point is a price tag on the claim rather than a refutation of the experiment. To assert a positive effect requires a stated belief that the bias prior is tighter than the tipping point. The honest version of the conversation with stakeholders runs through this number. The posterior is what makes that conversation possible: the same inference machinery that reads the experiment’s results in a clean world is what traces the contour of its fragility here. The question has shifted from what the treatment did to which commitments about the unmeasured bias are needed to believe it did anything, and a posterior answers the new question as readily as the old.
The same machinery runs on the log-odds scale. Before mapping the full topology of the bias-prior space, we confirm that the one-dimensional fragility picture is not an artefact of the Gaussian likelihood.
The same machinery on a binary outcome#
The conversion-rate version of the experiment uses the same structural model on the log-odds scale. The bias parameter now lives on the logit, but the framing is identical: the observed log-odds difference is the sum of a treatment effect and an unmeasured-confounder contribution, and a prior over the latter is the only thing that separates them.
def simulate_quasi_experimental_bernoulli(N, baseline_rate, true_tau_logit, true_bias_logit, rng):
from scipy.special import expit
p_A = expit(np.log(baseline_rate / (1 - baseline_rate)))
p_B = expit(np.log(baseline_rate / (1 - baseline_rate)) + true_tau_logit + true_bias_logit)
n_A = rng.binomial(N, p_A)
n_B = rng.binomial(N, p_B)
return n_A, n_B, p_A, p_B
BASELINE_RATE_B = 0.10
TRUE_TAU_LOGIT = 0.15
TRUE_BIAS_LOGIT = 0.30
n_A_obs, n_B_obs, p_A_true, p_B_true = simulate_quasi_experimental_bernoulli(
N=8000,
baseline_rate=BASELINE_RATE_B,
true_tau_logit=TRUE_TAU_LOGIT,
true_bias_logit=TRUE_BIAS_LOGIT,
rng=rng,
)
print(f"Observed conversions: A = {n_A_obs}/8000, B = {n_B_obs}/8000")
print(f"True p_A = {p_A_true:.4f}, p_B (with bias) = {p_B_true:.4f}")
Observed conversions: A = 834/8000, B = 1165/8000
True p_A = 0.1000, p_B (with bias) = 0.1484
def bernoulli_sensitivity_model(
n_A, n_B, N, baseline_logit_prior=(-2.0, 0.5), tau_prior=(0.0, 0.5), bias_prior=(0.0, 0.3)
):
with pm.Model() as model:
logit_p_A = pm.Normal(
"logit_p_A", mu=baseline_logit_prior[0], sigma=baseline_logit_prior[1]
)
tau = pm.Normal("tau", mu=tau_prior[0], sigma=tau_prior[1])
beta = pm.Normal("beta", mu=bias_prior[0], sigma=bias_prior[1])
logit_p_B = pm.Deterministic("logit_p_B", logit_p_A + tau + beta)
p_A = pm.Deterministic("p_A", pm.math.invlogit(logit_p_A))
p_B = pm.Deterministic("p_B", pm.math.invlogit(logit_p_B))
pm.Binomial("obs_A", n=N, p=p_A, observed=n_A)
pm.Binomial("obs_B", n=N, p=p_B, observed=n_B)
return model
tipping_records_bern = []
for bias_sd in [0.05, 0.15, 0.2, 0.30, 0.50, 0.80]:
with bernoulli_sensitivity_model(n_A_obs, n_B_obs, N=8000, bias_prior=(0.0, bias_sd)):
idata = pm.sample(
draws=1000,
tune=1000,
chains=2,
target_accept=0.95,
random_seed=RANDOM_SEED,
progressbar=False,
)
tau_samples = idata.posterior["tau"].values.flatten()
tipping_records_bern.append(
{
"bias_sd": bias_sd,
"tau_mean": tau_samples.mean(),
"tau_sd": tau_samples.std(),
"prob_positive": float((tau_samples > 0).mean()),
}
)
tipping_bern_df = pd.DataFrame(tipping_records_bern)
# prob_positive decreases as the bias prior loosens; interpolate to the threshold crossing
tip_bern = float(
np.interp(
decision_threshold,
tipping_bern_df["prob_positive"].values[::-1],
tipping_bern_df["bias_sd"].values[::-1],
)
)
tipping_bern_df.round(3)
NUTS[nutpie]: [logit_p_A, tau, beta]
NUTS[nutpie]: [logit_p_A, tau, beta]
NUTS[nutpie]: [logit_p_A, tau, beta]
NUTS[nutpie]: [logit_p_A, tau, beta]
NUTS[nutpie]: [logit_p_A, tau, beta]
NUTS[nutpie]: [logit_p_A, tau, beta]
| bias_sd | tau_mean | tau_sd | prob_positive | |
|---|---|---|---|---|
| 0 | 0.05 | 0.369 | 0.070 | 1.000 |
| 1 | 0.15 | 0.358 | 0.146 | 0.998 |
| 2 | 0.20 | 0.324 | 0.193 | 0.955 |
| 3 | 0.30 | 0.273 | 0.267 | 0.835 |
| 4 | 0.50 | 0.191 | 0.342 | 0.716 |
| 5 | 0.80 | 0.110 | 0.401 | 0.600 |
fig, axes = plt.subplots(1, 2, figsize=(20, 4))
axes[0].errorbar(
tipping_bern_df["bias_sd"],
tipping_bern_df["tau_mean"],
yerr=tipping_bern_df["tau_sd"],
marker="o",
linewidth=2,
capsize=4,
)
axes[0].axhline(0.0, color="black", linestyle=":")
axes[0].set_xlabel(r"Prior SD on bias $\beta$ (log-odds)")
axes[0].set_ylabel(r"Posterior of $\tau$ (log-odds)")
axes[0].set_title("Bernoulli case: posterior of treatment effect")
axes[1].plot(
tipping_bern_df["bias_sd"],
tipping_bern_df["prob_positive"],
marker="o",
linewidth=2,
color="C3",
)
axes[1].axhline(
decision_threshold,
color="black",
linestyle="--",
label=f"Decision threshold = {decision_threshold}",
)
axes[1].axvline(
tip_bern,
color="C3",
linestyle=":",
alpha=0.7,
label=f"Tipping point ≈ {tip_bern:.2f}",
)
axes[1].set_xlabel(r"Prior SD on bias $\beta$ (log-odds)")
axes[1].set_ylabel(r"$P(\tau > 0 \mid \text{data})$")
axes[1].set_title("Tipping point on the log-odds scale")
axes[1].legend();
The shape of the curve confirms what the Gaussian case showed: the decision rule loses confidence as the prior on bias widens, and the tipping point is identifiable on the log-odds scale just as it was on the revenue scale. The E-value of [VanderWeele and Ding, 2017] corresponds, roughly, to the bias magnitude at which a frequentist decision would tip; the Bayesian curve is the full posterior over that commitment. One dimension, two likelihoods, the same fragility picture. The complete audit needs both dimensions of the bias prior, the full region of commitments the conclusion can survive. That surface is below.
The sensitivity surface#
Both the Gaussian and the binary sweep moved one dimension of the bias prior. The complete audit requires the other: a map of the full region of \((\mu_\beta, \sigma_\beta)\) commitments the experiment can survive. The sweep below opens the line into a surface.
bias_mu_grid = np.linspace(-0.5, 0.5, 25)
bias_sd_grid_2d = np.linspace(0.01, 1.0, 25)
prob_grid = np.zeros((len(bias_sd_grid_2d), len(bias_mu_grid)))
for i, b_sd in enumerate(bias_sd_grid_2d):
for j, b_mu in enumerate(bias_mu_grid):
pm_a, pc_a = gaussian_sensitivity_posterior(
d_hat, sigma_d, tau_prior_sd=1.0, bias_prior_sd=b_sd, bias_prior_mean=b_mu
)
tau_mean, tau_sd = pm_a[0], np.sqrt(pc_a[0, 0])
prob_grid[i, j] = 1.0 - stats.norm.cdf(0.0, loc=tau_mean, scale=tau_sd)
fig, ax = plt.subplots(figsize=(15, 5))
im = ax.imshow(
prob_grid,
origin="lower",
aspect="auto",
extent=[bias_mu_grid.min(), bias_mu_grid.max(), bias_sd_grid_2d.min(), bias_sd_grid_2d.max()],
cmap="RdBu_r",
vmin=0.0,
vmax=1.0,
)
contour = ax.contour(
bias_mu_grid,
bias_sd_grid_2d,
prob_grid,
levels=[0.5, decision_threshold],
colors=["white", "black"],
linewidths=[1.2, 2.0],
)
ax.clabel(contour, fmt={0.5: "P=0.5", decision_threshold: f"P={decision_threshold}"})
ax.set_xlabel(r"Prior mean of bias $\beta$")
ax.set_ylabel(r"Prior SD of bias $\beta$")
ax.set_title(r"$P(\tau > 0)$ under bias-prior commitments")
plt.colorbar(im, ax=ax, label=r"$P(\tau > 0 \mid d_{\text{obs}})$");
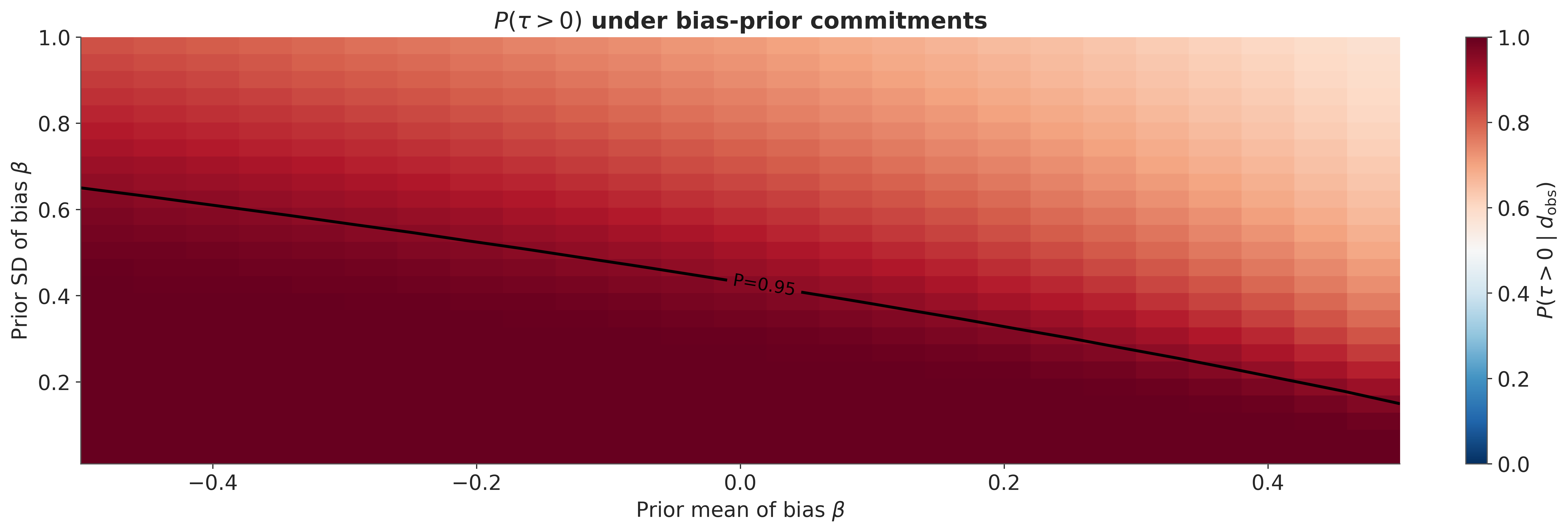
The decision threshold contour partitions the bias-prior plane into a region where the experiment is defensible and a region where it is not. The analyst who wants to claim a positive effect commits to a point inside the inner contour. The dissenter who wants to claim the effect is artefactual commits to a point outside it. The graph locates the disagreement rather than settling it. It shows which region of the bias-prior plane each party’s commitments occupy, and whether that region sits inside or outside the contour of defensibility. The audit has a legible geometry.
Robustness as a posterior question#
A sensitivity analysis maps the randomisation gap rather than closing it. The sweep above does not prove the experiment robust; it produces an auditable exhibit of which bias commitments the experiment can survive and which it cannot. That exhibit is the deliverable.
This changes what honest reporting looks like. The headline from a quasi-experiment becomes the tipping point, the prior on the bias at which the conclusion turns, and the sensitivity surface widens that point into a region: the full set of bias-prior commitments the experiment can survive, with its boundary drawn as a contour. Two analysts who hold the same data and reach opposite conclusions are reading the same difference in means through different priors on the confounder, and the surface shows precisely which commitment divides them.
What a clean experiment reports as one posterior on the effect, a quasi-experiment reports as a posterior spread over the bias the data cannot rule out. Mapping that spread, and naming the commitment a positive conclusion requires, is what the quasi-experiment owes its readers. Multiple Experiments and Bayesian Meta-analysis turns from a single threatened experiment to a whole series of them.
References#
U.S. Food and Drug Administration. Use of bayesian methodology in clinical trials of drug and biological products: guidance for industry (draft guidance). Draft Guidance, Center for Drug Evaluation and Research (CDER) and Center for Biologics Evaluation and Research (CBER), January 2026. Distributed for comment purposes only.
MA Hernán and JM Robins. Causal Inference: What If. Chapman & Hall/CRC, 2020.
Scott Cunningham. Causal inference: The Mixtape. Yale University Press, 2021.
Paul R. Rosenbaum. Observational Studies. Springer, 2nd edition, 2002.
Tyler J. VanderWeele and Peng Ding. Sensitivity analysis in observational research: introducing the E-value. Annals of Internal Medicine, 167(4):268–274, 2017. doi:10.7326/M16-2607.
Guido W. Imbens. Sensitivity to exogeneity assumptions in program evaluation. American Economic Review, 93(2):126–132, 2003. doi:10.1257/000282803321946921.
Carlos Cinelli and Chad Hazlett. Making sense of sensitivity: extending omitted variable bias. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 82(1):39–67, 2020. doi:10.1111/rssb.12348.
Watermark#
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor,xarray
Last updated: Fri, 12 Jun 2026
Python implementation: CPython
Python version : 3.13.13
IPython version : 9.14.0
pytensor: 3.0.3
xarray : 2026.4.0
arviz : 1.1.0
matplotlib: 3.10.9
numpy : 2.3.5
pandas : 2.3.3
pymc : 6.0.1
scipy : 1.17.1
Watermark: 2.6.0
License notice#
All the notebooks in this example gallery are provided under the MIT License which allows modification, and redistribution for any use provided the copyright and license notices are preserved.
Citing PyMC examples#
To cite this notebook, use the DOI provided by Zenodo for the pymc-examples repository.
Important
Many notebooks are adapted from other sources: blogs, books… In such cases you should cite the original source as well.
Also remember to cite the relevant libraries used by your code.
Here is an citation template in bibtex:
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
which once rendered could look like: