
Compound Steps in Sampling#
This notebook explains how the compound steps work in pymc.sample function when sampling multiple random variables. We are going to answer the following questions associated with compound steps:
How do compound steps work?
What happens when PyMC assigns step methods by default?
How to specify the step methods? What is the order to apply the step methods at each iteration? Is there a way to specify the order of the step methods?
What are the issues with mixing discrete and continuous samplers, especially with HMC/NUTS?
What happens to sample statistics that occur in multiple step methods?
az.style.use("arviz-darkgrid")
Compound steps#
When sampling a model with multiple free random variables, compound steps are needed in the pm.sample function. When compound steps are involved, the function takes a list of step to generate a list of methods for different random variables. For example in the following code:
with pm.Model() as m:
rv1 = ... # random variable 1 (continuous)
rv2 = ... # random variable 2 (continuous)
rv3 = ... # random variable 3 (categorical)
#...
step1 = pm.Metropolis([rv1, rv2])
step2 = pm.CategoricalGibbsMetropolis([rv3])
trace = pm.sample(..., step=[step1, step2])
The compound step now contains a list of methods. At each sampling step, it iterates over these methods, taking a point as input. In each step a new point is proposed as an output, if rejected by the Metropolis-Hastings criteria the original input point sticks around as the output.
Compound steps by default#
To conduct Markov chain Monte Carlo (MCMC) sampling to generate posterior samples in PyMC, we specify a step method object that corresponds to a particular MCMC algorithm, such as Metropolis, Slice sampling, or the No-U-Turn Sampler (NUTS). PyMC’s step_methods can be assigned manually, or assigned automatically by PyMC. Auto-assignment is based on the attributes of each variable in the model. In general:
Binary variables will be assigned to BinaryMetropolis
Discrete variables will be assigned to Metropolis
Continuous variables will be assigned to NUTS
When we call pm.sample(return_inferencedata=False), PyMC assigns the best step method to each of the free random variables. Take the following example
n_ = pytensor.shared(np.asarray([10, 15]))
with pm.Model() as m:
p = pm.Beta("p", 1.0, 1.0)
ni = pm.Bernoulli("ni", 0.5)
k = pm.Binomial("k", p=p, n=n_[ni], observed=4)
trace = pm.sample(10000)
Multiprocess sampling (4 chains in 4 jobs)
CompoundStep
>NUTS: [p]
>BinaryGibbsMetropolis: [ni]
Sampling 4 chains for 1_000 tune and 10_000 draw iterations (4_000 + 40_000 draws total) took 43 seconds.
There are two free parameters in the model we would like to sample from, a continuous variable p_logodds__ and a binary variable ni.
m.free_RVs
[p, ni]
When we call pm.sample(return_inferencedata=False), PyMC assigns the best step method to each of them. For example, NUTS was assigned to p_logodds__ and BinaryGibbsMetropolis was assigned to ni.
Specify compound steps#
Auto-assignment can be overridden for any subset of variables by specifying them manually prior to sampling:
with m:
step1 = pm.Metropolis([p])
step2 = pm.BinaryMetropolis([ni])
trace = pm.sample(
10000,
step=[step1, step2],
idata_kwargs={
"dims": {"accept": ["step"]},
"coords": {"step": ["Metropolis", "BinaryMetropolis"]},
},
)
Multiprocess sampling (4 chains in 4 jobs)
CompoundStep
>Metropolis: [p]
>BinaryMetropolis: [ni]
Sampling 4 chains for 1_000 tune and 10_000 draw iterations (4_000 + 40_000 draws total) took 38 seconds.
The number of effective samples is smaller than 25% for some parameters.
point = m.test_point
point
e:\source\repos\pymc3-v4\pymc\model.py:976: FutureWarning: `Model.test_point` has been deprecated. Use `Model.recompute_initial_point(seed=None)`.
warnings.warn(
{'p_logodds__': array(0.), 'ni': array(1, dtype=int64)}
Then pass the point to the first step method pm.Metropolis for random variable p.
point, state = step1.step(point=point)
point, state
({'p_logodds__': array(0.52418058), 'ni': array(1, dtype=int64)},
[{'tune': True,
'scaling': array([1.]),
'accept': 0.08964089546197954,
'accepted': True}])
As you can see, the value of ni does not change, but p_logodds__ is updated.
And similarly, you can pass the updated point to step2 and get a sample for ni:
point = step2.step(point=point)
point
({'p_logodds__': array(0.52418058), 'ni': array(0, dtype=int64)},
[{'tune': True, 'accept': 21.632194762798157, 'p_jump': 0.5}])
Compound step works exactly like this by iterating all the steps within the list. In effect, it is a metropolis hastings within gibbs sampling.
Moreover, pm.CompoundStep is called internally by pm.sample(return_inferencedata=False). We can make them explicit as below:
with m:
comp_step1 = pm.CompoundStep([step1, step2])
trace1 = pm.sample(10000, comp_step1)
comp_step1.methods
Multiprocess sampling (4 chains in 4 jobs)
CompoundStep
>Metropolis: [p]
>BinaryMetropolis: [ni]
Sampling 4 chains for 1_000 tune and 10_000 draw iterations (4_000 + 40_000 draws total) took 38 seconds.
The number of effective samples is smaller than 25% for some parameters.
[<pymc.step_methods.metropolis.Metropolis at 0x215573b6cd0>,
<pymc.step_methods.metropolis.BinaryMetropolis at 0x21557af7e20>]
# These are the Sample Stats for Compound Step based sampling
list(trace1.sample_stats.data_vars)
['p_jump', 'scaling', 'accepted', 'accept']
Note: In compound step method, a sample stats variable maybe present in both step methods, like accept in every chain.
trace1.sample_stats["accept"].sel(chain=1).values
array([[5.05880713e-02, 1.00000000e+00],
[1.00656794e+00, 8.23345217e-01],
[6.44911199e-03, 1.00000000e+00],
...,
[1.32225607e-06, 1.00000000e+00],
[7.07386719e-02, 1.00000000e+00],
[4.94538644e-02, 1.00000000e+00]])
Order of step methods#
When in the default setting, the parameter update order follows the same order of the random variables, and it is assigned automatically. But if you specify the steps, you can change the order of the methods in the list:
with m:
comp_step2 = pm.CompoundStep([step2, step1])
trace2 = pm.sample(
10000,
comp_step2,
)
comp_step2.methods
Multiprocess sampling (4 chains in 4 jobs)
CompoundStep
>BinaryMetropolis: [ni]
>Metropolis: [p]
Sampling 4 chains for 1_000 tune and 10_000 draw iterations (4_000 + 40_000 draws total) took 39 seconds.
The number of effective samples is smaller than 25% for some parameters.
[<pymc.step_methods.metropolis.BinaryMetropolis at 0x21557af7e20>,
<pymc.step_methods.metropolis.Metropolis at 0x215573b6cd0>]
In the sampling process, it always follows the same step order in each sample in the Gibbs-like fashion. More precisely, at each update, it iterates over the list of methods where the accept/reject is based on comparing the acceptance rate with \(p \sim \text{Uniform}(0, 1)\) (by checking whether \(\log p < \log p_{\text {updated}} - \log p_{\text {current}}\)).
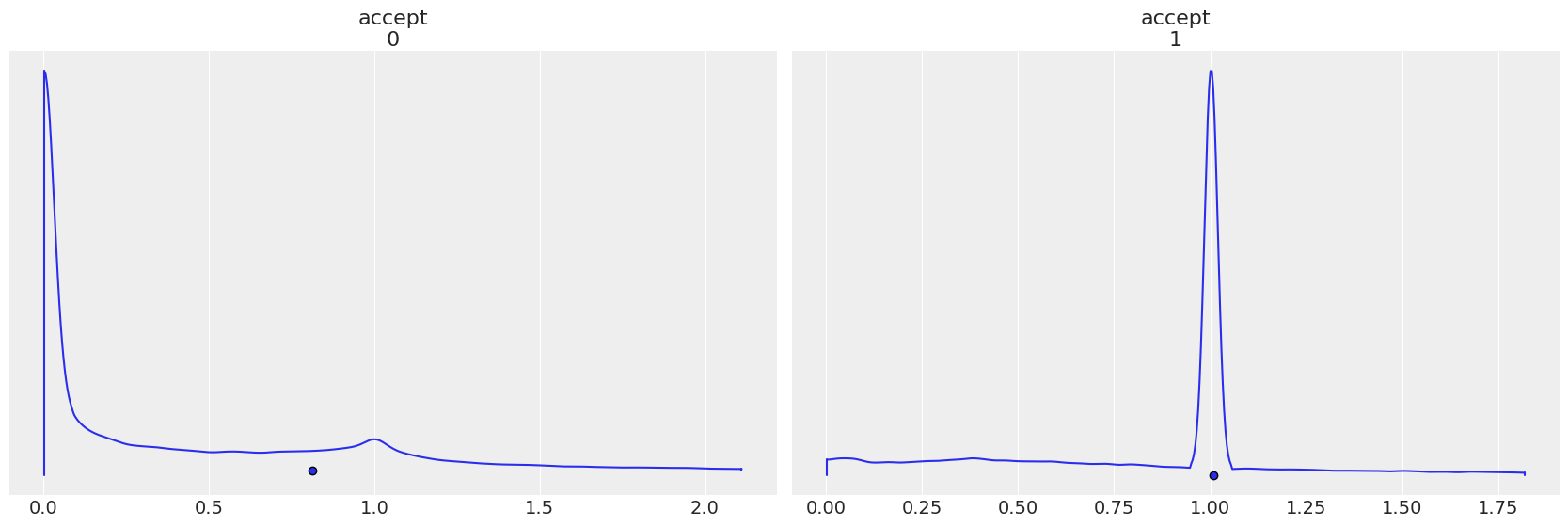
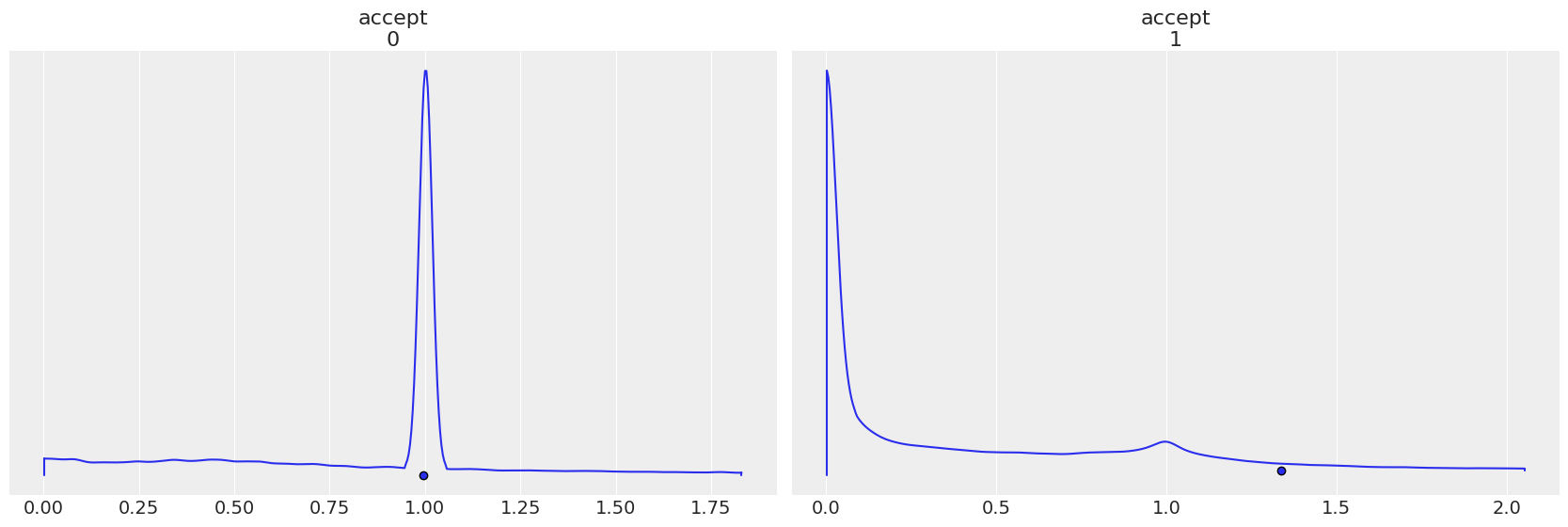
Each step method gets its own accept, notice how the plots are reversed in when step order is reverted.
az.plot_density(
trace1,
group="sample_stats",
var_names="accept",
point_estimate="mean",
);
az.plot_density(
trace2,
group="sample_stats",
var_names="accept",
point_estimate="mean",
);
Issues with mixing discrete and continuous sampling#
A recurrent issue/concern is the validity of mixing discrete and continuous sampling, especially mixing other samplers with NUTS. While in the book Bayesian Data Analysis 3rd edition Chapter 12.4, there is a small paragraph on “Combining Hamiltonian Monte Carlo with Gibbs sampling”, which suggests that this could be a valid way to do, the Stan developers are always skeptical about how practical it is. (Here are more discussions about this issue 1, 2).
The concern with mixing discrete and continuous sampling is that the change in discrete parameters will affect the continuous distribution’s geometry so that the adaptation (i.e., the tuned mass matrix and step size) may be inappropriate for the Hamiltonian Monte Carlo sampling. HMC/NUTS is hypersensitive to its tuning parameters (mass matrix and step size). Another issue is that we also don’t know how many iterations we have to run to get a decent sample when the discrete parameters change. Though it hasn’t been fully evaluated, it seems that if the discrete parameter is in low dimensions (e.g., 2-class mixture models, outlier detection with explicit discrete labeling), the mixing of discrete sampling with HMC/NUTS works OK. However, it is much less efficient than marginalizing out the discrete parameters. And sometimes it can be observed that the Markov chains get stuck quite often. In order to evaluate this more properly, one can use a simulation-based method to look at the posterior coverage and establish the computational correctness, as explained in Cook, Gelman, and Rubin 2006.
Updated by: Meenal Jhajharia
%load_ext watermark
%watermark -n -u -v -iv -w
Last updated: Sun Jan 09 2022
Python implementation: CPython
Python version : 3.8.10
IPython version : 7.30.1
pymc : 4.0.0b1
pytensor: 2.3.2
arviz : 0.11.4
xarray: 0.18.2
numpy : 1.21.1
Watermark: 2.3.0