
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pymc3 as pm
import theano
from scipy.integrate import odeint
from theano import *
THEANO_FLAGS = "optimizer=fast_compile"
print(f"PyMC3 Version: {pm.__version__}")
PyMC3 Version: 3.11.0
Lotka-Volterra with manual gradients#
Mathematical models are used ubiquitously in a variety of science and engineering domains to model the time evolution of physical variables. These mathematical models are often described as ODEs that are characterised by model structure - the functions of the dynamical variables - and model parameters. However, for the vast majority of systems of practical interest it is necessary to infer both the model parameters and an appropriate model structure from experimental observations. This experimental data often appears to be scarce and incomplete. Furthermore, a large variety of models described as dynamical systems show traits of sloppiness (see Gutenkunst et al., 2007) and have unidentifiable parameter combinations. The task of inferring model parameters and structure from experimental data is of paramount importance to reliably analyse the behaviour of dynamical systems and draw faithful predictions in light of the difficulties posit by their complexities. Moreover, any future model prediction should encompass and propagate variability and uncertainty in model parameters and/or structure. Thus, it is also important that the inference methods are equipped to quantify and propagate the aforementioned uncertainties from the model descriptions to model predictions. As a natural choice to handle uncertainty, at least in the parameters, Bayesian inference is increasingly used to fit ODE models to experimental data (Mark Girolami, 2008). However, due to some of the difficulties that I pointed above, fitting an ODE model using Bayesian inference is a challenging task. In this tutorial I am going to take up that challenge and will show how PyMC3 could be potentially used for this purpose.
I must point out that model fitting (inference of the unknown parameters) is just one of many crucial tasks that a modeller has to complete in order to gain a deeper understanding of a physical process. However, success in this task is crucial and this is where PyMC3, and probabilistic programming (ppl) in general, is extremely useful. The modeller can take full advantage of the variety of samplers and distributions provided by PyMC3 to automate inference.
In this tutorial I will focus on the fitting exercise, that is estimating the posterior distribution of the parameters given some noisy experimental time series.
Bayesian inference of the parameters of an ODE#
I begin by first introducing the Bayesian framework for inference in a coupled non-linear ODE defined as
Consider a set of noisy experimental observations \(\boldsymbol{Y} \in \mathbb{R}^{T\times K}\) observed at \(T\) experimental time points for the \(K\) states. We can obtain the likelihood \(p(\boldsymbol{Y}|\boldsymbol{X})\), where I use the symbol \(\boldsymbol{X}:=\boldsymbol{X}(\boldsymbol{\theta}, \mathbf{x_0})\), and combine that with a prior distribution \(p(\boldsymbol{\theta})\) on the parameters, using the Bayes theorem, to obtain the posterior distribution as
For this tutorial I have chosen two ODEs:
I will showcase two distinctive approaches (NUTS and SMC step methods), supported by PyMC3, for the estimation of unknown parameters in these models.
Lotka-Volterra predator prey model#
The Lotka Volterra model depicts an ecological system that is used to describe the interaction between a predator and prey species. This ODE given by
odeint. Note that the methods in this tutorial is not limited or tied to odeint. Here I have chosen odeint to simply stay within PyMC3’s dependencies (SciPy in this case).
class LotkaVolterraModel:
def __init__(self, y0=None):
self._y0 = y0
def simulate(self, parameters, times):
alpha, beta, gamma, delta, Xt0, Yt0 = (x for x in parameters)
def rhs(y, t, p):
X, Y = y
dX_dt = alpha * X - beta * X * Y
dY_dt = -gamma * Y + delta * X * Y
return dX_dt, dY_dt
values = odeint(rhs, [Xt0, Yt0], times, (parameters,))
return values
ode_model = LotkaVolterraModel()
Handling ODE gradients#
NUTS requires the gradient of the log of the target density w.r.t. the unknown parameters, \(\nabla_{\boldsymbol{\theta}}p(\boldsymbol{\theta}|\boldsymbol{Y})\), which can be evaluated using the chain rule of differentiation as
The gradient of an ODE w.r.t. its parameters, the term \(\frac{\partial \boldsymbol{X}}{\partial \boldsymbol{\theta}}\), can be obtained using local sensitivity analysis, although this is not the only method to obtain gradients. However, just like solving an ODE (a non-linear one to be precise) evaluation of the gradients can only be carried out using some sort of numerical method, say for example the famous Runge-Kutta method for non-stiff ODEs. PyMC3 uses Theano as the automatic differentiation engine and thus all models are implemented by stitching together available primitive operations (Ops) supported by Theano. Even to extend PyMC3 we need to compose models that can be expressed as symbolic combinations of Theano’s Ops. However, if we take a step back and think about Theano then it is apparent that neither the ODE solution nor its gradient w.r.t. to the parameters can be expressed symbolically as combinations of Theano’s primitive Ops. Hence, from Theano’s perspective an ODE (and for that matter any other form of a non-linear differential equation) is a non-differentiable black-box function. However, one might argue that if a numerical method is coded up in Theano (using say the scan Op), then it is possible to symbolically express the numerical method that evaluates the ODE states, and then we can easily use Theano’s automatic differentiation engine to obtain the gradients as well by differentiating through the numerical solver itself. I like to point out that the former, obtaining the solution, is indeed possible this way but the obtained gradient would be error-prone. Additionally, this entails to a complete ‘re-inventing the wheel’ as one would have to implement decades old sophisticated numerical algorithms again from scratch in Theano.
Thus, in this tutorial I am going to present the alternative approach which consists of defining new custom Theano Ops, extending Theano, that will wrap both the numerical solution and the vector-Matrix product, \( \frac{\partial p(\boldsymbol{\theta}|\boldsymbol{Y})}{\partial \boldsymbol{X}}^T \frac{\partial \boldsymbol{X}}{\partial \boldsymbol{\theta}}\), often known as the vector-Jacobian product (VJP) in automatic differentiation literature. I like to point out here that in the context of non-linear ODEs the term Jacobian is used to denote gradients of the ODE dynamics \(\boldsymbol{f}\) w.r.t. the ODE states \(X(t)\). Thus, to avoid confusion, from now on I will use the term vector-sensitivity product (VSP) to denote the same quantity that the term VJP denotes.
I will start by introducing the forward sensitivity analysis.
ODE sensitivity analysis#
For a coupled ODE system \(\frac{d X(t)}{dt} = \boldsymbol{f}(X(t),\boldsymbol{\theta})\), the local sensitivity of the solution to a parameter is defined by how much the solution would change by changes in the parameter, i.e. the sensitivity of the the \(k\)-th state is simply put the time evolution of its gradient w.r.t. the \(d\)-th parameter. This quantity, denoted as \(Z_{kd}(t)\), is given by
Using forward sensitivity analysis we can obtain both the state \(X(t)\) and its derivative w.r.t the parameters, at each time point, as the solution to an initial value problem by augmenting the original ODE system with the sensitivity equations \(Z_{kd}\). The augmented ODE system \(\big(X(t), Z(t)\big)\) can then be solved together using a chosen numerical method. The augmented ODE system needs the initial values for the sensitivity equations. All of these should be set to zero except the ones where the sensitivity of a state w.r.t. its own initial value is sought, that is \( \frac{\partial X_k(t)}{\partial X_k (0)} =1 \). Note that in order to solve this augmented system we have to embark in the tedious process of deriving \( \frac{\partial f_k}{\partial X_i (t)}\), also known as the Jacobian of an ODE, and \(\frac{\partial f_k}{\partial \theta_d}\) terms. Thankfully, many ODE solvers calculate these terms and solve the augmented system when asked for by the user. An example would be the SUNDIAL CVODES solver suite. A Python wrapper for CVODES can be found here.
However, for this tutorial I would go ahead and derive the terms mentioned above, manually, and solve the Lotka-Volterra ODEs alongwith the sensitivities in the following code block. The functions jac and dfdp below calculate \( \frac{\partial f_k}{\partial X_i (t)}\) and \(\frac{\partial f_k}{\partial \theta_d}\) respectively for the Lotka-Volterra model. For convenience I have transformed the sensitivity equation in a matrix form. Here I extended the solver code snippet above to include sensitivities when asked for.
n_states = 2
n_odeparams = 4
n_ivs = 2
class LotkaVolterraModel:
def __init__(self, n_states, n_odeparams, n_ivs, y0=None):
self._n_states = n_states
self._n_odeparams = n_odeparams
self._n_ivs = n_ivs
self._y0 = y0
def simulate(self, parameters, times):
return self._simulate(parameters, times, False)
def simulate_with_sensitivities(self, parameters, times):
return self._simulate(parameters, times, True)
def _simulate(self, parameters, times, sensitivities):
alpha, beta, gamma, delta, Xt0, Yt0 = (x for x in parameters)
def r(y, t, p):
X, Y = y
dX_dt = alpha * X - beta * X * Y
dY_dt = -gamma * Y + delta * X * Y
return dX_dt, dY_dt
if sensitivities:
def jac(y):
X, Y = y
ret = np.zeros((self._n_states, self._n_states))
ret[0, 0] = alpha - beta * Y
ret[0, 1] = -beta * X
ret[1, 0] = delta * Y
ret[1, 1] = -gamma + delta * X
return ret
def dfdp(y):
X, Y = y
ret = np.zeros(
(self._n_states, self._n_odeparams + self._n_ivs)
) # except the following entries
ret[0, 0] = (
X # \frac{\partial [\alpha X - \beta XY]}{\partial \alpha}, and so on...
)
ret[0, 1] = -X * Y
ret[1, 2] = -Y
ret[1, 3] = X * Y
return ret
def rhs(y_and_dydp, t, p):
y = y_and_dydp[0 : self._n_states]
dydp = y_and_dydp[self._n_states :].reshape(
(self._n_states, self._n_odeparams + self._n_ivs)
)
dydt = r(y, t, p)
d_dydp_dt = np.matmul(jac(y), dydp) + dfdp(y)
return np.concatenate((dydt, d_dydp_dt.reshape(-1)))
y0 = np.zeros((2 * (n_odeparams + n_ivs)) + n_states)
y0[6] = 1.0 # \frac{\partial [X]}{\partial Xt0} at t==0, and same below for Y
y0[13] = 1.0
y0[0:n_states] = [Xt0, Yt0]
result = odeint(rhs, y0, times, (parameters,), rtol=1e-6, atol=1e-5)
values = result[:, 0 : self._n_states]
dvalues_dp = result[:, self._n_states :].reshape(
(len(times), self._n_states, self._n_odeparams + self._n_ivs)
)
return values, dvalues_dp
else:
values = odeint(r, [Xt0, Yt0], times, (parameters,), rtol=1e-6, atol=1e-5)
return values
ode_model = LotkaVolterraModel(n_states, n_odeparams, n_ivs)
For this model I have set the relative and absolute tolerances to \(10^{-6}\) and \(10^{-5}\) respectively, as was suggested in the Stan tutorial. This will produce sufficiently accurate solutions. Further reducing the tolerances will increase accuracy but at the cost of increasing the computational time. A thorough discussion on the choice and use of a numerical method for solving the ODE is out of the scope of this tutorial. However, I must point out that the inaccuracies of the ODE solver do affect the likelihood and as a result the inference. This is more so the case for stiff systems. I would recommend interested readers to this nice blog article where this effect is discussed thoroughly for a cardiac ODE model. There is also an emerging area of uncertainty quantification that attacks the problem of noise arisng from impreciseness of numerical algorithms, probabilistic numerics. This is indeed an elegant framework to carry out inference while taking into account the errors coming from the numeric ODE solvers.
Custom ODE Op#
In order to define the custom Op I have written down two theano.Op classes ODEGradop, ODEop. ODEop essentially wraps the ODE solution and will be called by PyMC3. The ODEGradop wraps the numerical VSP and this op is then in turn used inside the grad method in the ODEop to return the VSP. Note that we pass in two functions: state, numpy_vsp as arguments to respective Ops. I will define these functions later. These functions act as shims using which we connect the python code for numerical solution of state and VSP to Theano and thus PyMC3.
class ODEGradop(theano.tensor.Op):
def __init__(self, numpy_vsp):
self._numpy_vsp = numpy_vsp
def make_node(self, x, g):
x = theano.tensor.as_tensor_variable(x)
g = theano.tensor.as_tensor_variable(g)
node = theano.Apply(self, [x, g], [g.type()])
return node
def perform(self, node, inputs_storage, output_storage):
x = inputs_storage[0]
g = inputs_storage[1]
out = output_storage[0]
out[0] = self._numpy_vsp(x, g) # get the numerical VSP
class ODEop(theano.tensor.Op):
def __init__(self, state, numpy_vsp):
self._state = state
self._numpy_vsp = numpy_vsp
def make_node(self, x):
x = theano.tensor.as_tensor_variable(x)
return theano.tensor.Apply(self, [x], [x.type()])
def perform(self, node, inputs_storage, output_storage):
x = inputs_storage[0]
out = output_storage[0]
out[0] = self._state(x) # get the numerical solution of ODE states
def grad(self, inputs, output_grads):
x = inputs[0]
g = output_grads[0]
grad_op = ODEGradop(self._numpy_vsp) # pass the VSP when asked for gradient
grad_op_apply = grad_op(x, g)
return [grad_op_apply]
I must point out that the way I have defined the custom ODE Ops above there is the possibility that the ODE is solved twice for the same parameter values, once for the states and another time for the VSP. To avoid this behaviour I have written a helper class which stops this double evaluation.
class solveCached:
def __init__(self, times, n_params, n_outputs):
self._times = times
self._n_params = n_params
self._n_outputs = n_outputs
self._cachedParam = np.zeros(n_params)
self._cachedSens = np.zeros((len(times), n_outputs, n_params))
self._cachedState = np.zeros((len(times), n_outputs))
def __call__(self, x):
if np.all(x == self._cachedParam):
state, sens = self._cachedState, self._cachedSens
else:
state, sens = ode_model.simulate_with_sensitivities(x, times)
return state, sens
times = np.arange(0, 21) # number of measurement points (see below)
cached_solver = solveCached(times, n_odeparams + n_ivs, n_states)
The ODE state & VSP evaluation#
Most ODE systems of practical interest will have multiple states and thus the output of the solver, which I have denoted so far as \(\boldsymbol{X}\), for a system with \(K\) states solved on \(T\) time points, would be a \(T \times K\)-dimensional matrix. For the Lotka-Volterra model the columns of this matrix represent the time evolution of the individual species concentrations. I flatten this matrix to a \(TK\)-dimensional vector \(vec(\boldsymbol{X})\), and also rearrange the sensitivities accordingly to obtain the desired vector-matrix product. It is beneficial at this point to test the custom Op as described here.
def state(x):
State, Sens = cached_solver(np.array(x, dtype=np.float64))
cached_solver._cachedState, cached_solver._cachedSens, cached_solver._cachedParam = (
State,
Sens,
x,
)
return State.reshape((2 * len(State),))
def numpy_vsp(x, g):
numpy_sens = cached_solver(np.array(x, dtype=np.float64))[1].reshape(
(n_states * len(times), len(x))
)
return numpy_sens.T.dot(g)
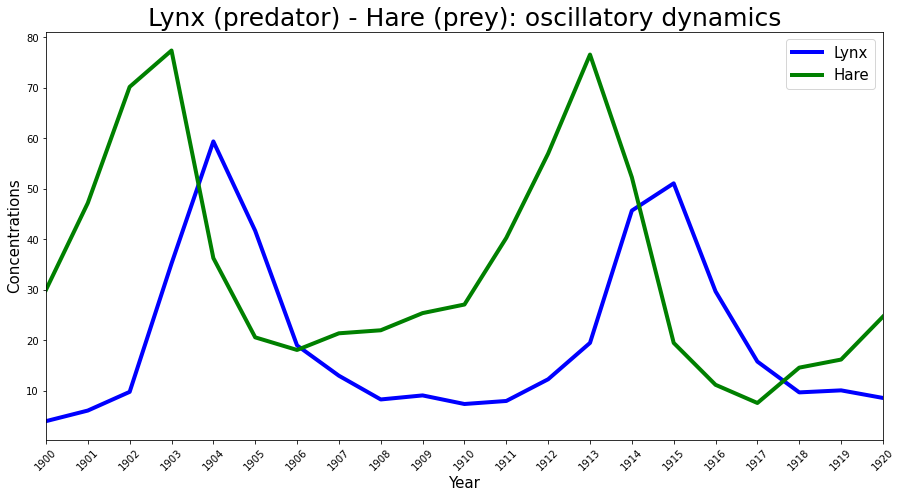
The Hudson’s Bay Company data#
The Lotka-Volterra predator prey model has been used previously to successfully explain the dynamics of natural populations of predators and prey, such as the lynx and snowshoe hare data of the Hudson’s Bay Company. This is the same data (that was shared here) used in the Stan example and thus I will use this data-set as the experimental observations \(\boldsymbol{Y}(t)\) to infer the parameters.
Year = np.arange(1900, 1921, 1)
# fmt: off
Lynx = np.array([4.0, 6.1, 9.8, 35.2, 59.4, 41.7, 19.0, 13.0, 8.3, 9.1, 7.4,
8.0, 12.3, 19.5, 45.7, 51.1, 29.7, 15.8, 9.7, 10.1, 8.6])
Hare = np.array([30.0, 47.2, 70.2, 77.4, 36.3, 20.6, 18.1, 21.4, 22.0, 25.4,
27.1, 40.3, 57.0, 76.6, 52.3, 19.5, 11.2, 7.6, 14.6, 16.2, 24.7])
# fmt: on
plt.figure(figsize=(15, 7.5))
plt.plot(Year, Lynx, color="b", lw=4, label="Lynx")
plt.plot(Year, Hare, color="g", lw=4, label="Hare")
plt.legend(fontsize=15)
plt.xlim([1900, 1920])
plt.xlabel("Year", fontsize=15)
plt.ylabel("Concentrations", fontsize=15)
plt.xticks(Year, rotation=45)
plt.title("Lynx (predator) - Hare (prey): oscillatory dynamics", fontsize=25);
The probabilistic model#
I have now got all the ingredients needed in order to define the probabilistic model in PyMC3. As I have mentioned previously I will set up the probabilistic model with the exact same likelihood and priors used in the Stan example. The observed data is defined as follows:
where \(\eta(t)\) is assumed to be zero mean i.i.d Gaussian noise with an unknown standard deviation \(\sigma\), that needs to be estimated. The above multiplicative (on the natural scale) noise model encodes a lognormal distribution as the likelihood:
The following priors are then placed on the parameters:
For an intuitive explanation, which I am omitting for brevity, regarding the choice of priors as well as the likelihood model, I would recommend the Stan example mentioned above. The above probabilistic model is defined in PyMC3 below. Note that the flattened state vector is reshaped to match the data dimensionality.
Finally, I use the pm.sample method to run NUTS by default and obtain \(1500\) post warm-up samples from the posterior.
theano.config.exception_verbosity = "high"
theano.config.floatX = "float64"
# Define the data matrix
Y = np.vstack((Hare, Lynx)).T
# Now instantiate the theano custom ODE op
my_ODEop = ODEop(state, numpy_vsp)
# The probabilistic model
with pm.Model() as LV_model:
# Priors for unknown model parameters
alpha = pm.Normal("alpha", mu=1, sigma=0.5)
beta = pm.Normal("beta", mu=0.05, sigma=0.05)
gamma = pm.Normal("gamma", mu=1, sigma=0.5)
delta = pm.Normal("delta", mu=0.05, sigma=0.05)
xt0 = pm.Lognormal("xto", mu=np.log(10), sigma=1)
yt0 = pm.Lognormal("yto", mu=np.log(10), sigma=1)
sigma = pm.Lognormal("sigma", mu=-1, sigma=1, shape=2)
# Forward model
all_params = pm.math.stack([alpha, beta, gamma, delta, xt0, yt0], axis=0)
ode_sol = my_ODEop(all_params)
forward = ode_sol.reshape(Y.shape)
# Likelihood
Y_obs = pm.Lognormal("Y_obs", mu=pm.math.log(forward), sigma=sigma, observed=Y)
trace = pm.sample(1500, init="jitter+adapt_diag", cores=1)
trace["diverging"].sum()
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Initializing NUTS failed. Falling back to elementwise auto-assignment.
Sequential sampling (2 chains in 1 job)
CompoundStep
>CompoundStep
>>Slice: [yto]
>>Slice: [xto]
>>Slice: [delta]
>>Slice: [gamma]
>>Slice: [beta]
>>Slice: [alpha]
>NUTS: [sigma]
/Users/CloudChaoszero/opt/anaconda3/envs/pymc3-dev-py38/lib/python3.8/site-packages/scipy/integrate/odepack.py:247: ODEintWarning: Excess work done on this call (perhaps wrong Dfun type). Run with full_output = 1 to get quantitative information.
warnings.warn(warning_msg, ODEintWarning)
Sampling 2 chains for 1_000 tune and 1_500 draw iterations (2_000 + 3_000 draws total) took 1327 seconds.
The rhat statistic is larger than 1.05 for some parameters. This indicates slight problems during sampling.
The estimated number of effective samples is smaller than 200 for some parameters.
0
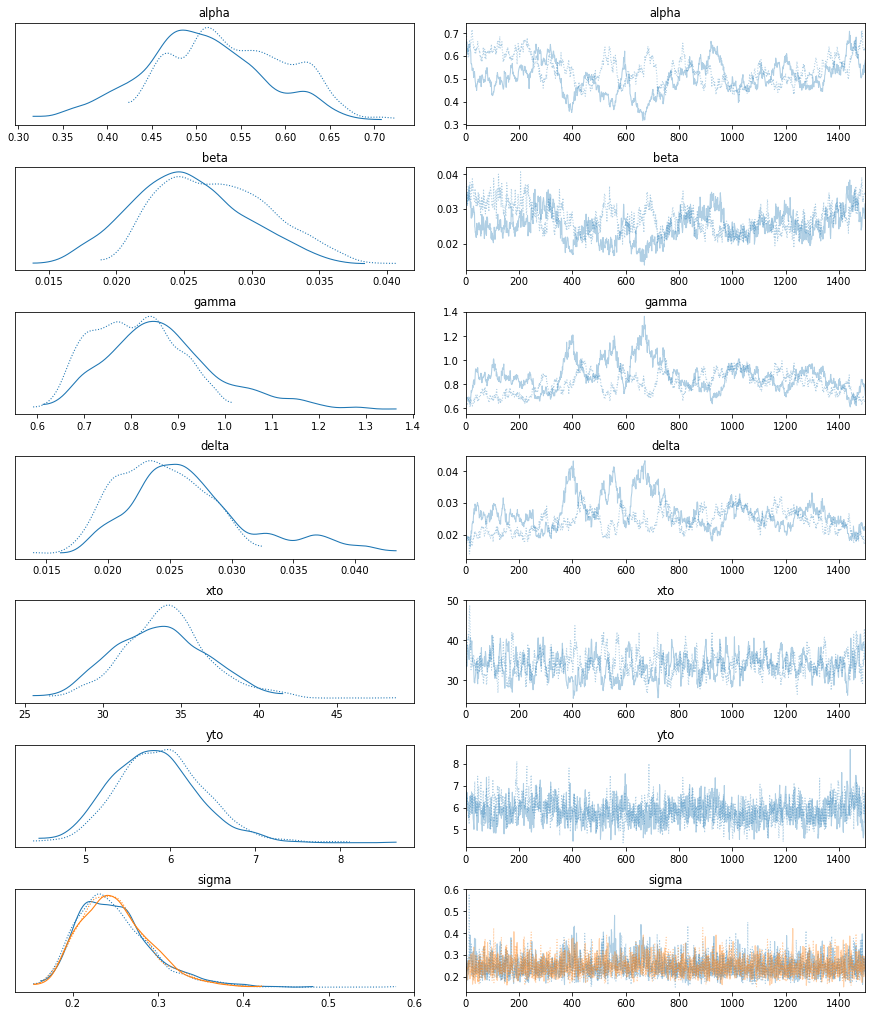
with LV_model:
az.plot_trace(trace);
import pandas as pd
summary = az.summary(trace)
STAN_mus = [0.549, 0.028, 0.797, 0.024, 33.960, 5.949, 0.248, 0.252]
STAN_sds = [0.065, 0.004, 0.091, 0.004, 2.909, 0.533, 0.045, 0.044]
summary["STAN_mus"] = pd.Series(np.array(STAN_mus), index=summary.index)
summary["STAN_sds"] = pd.Series(np.array(STAN_sds), index=summary.index)
summary
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_mean | ess_sd | ess_bulk | ess_tail | r_hat | STAN_mus | STAN_sds | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| alpha | 0.524 | 0.069 | 0.403 | 0.653 | 0.017 | 0.012 | 16.0 | 16.0 | 16.0 | 15.0 | 1.12 | 0.549 | 0.065 |
| beta | 0.026 | 0.004 | 0.019 | 0.035 | 0.001 | 0.001 | 17.0 | 17.0 | 17.0 | 17.0 | 1.11 | 0.028 | 0.004 |
| gamma | 0.837 | 0.111 | 0.652 | 1.045 | 0.029 | 0.022 | 14.0 | 14.0 | 15.0 | 15.0 | 1.12 | 0.797 | 0.091 |
| delta | 0.026 | 0.005 | 0.017 | 0.034 | 0.001 | 0.001 | 12.0 | 11.0 | 16.0 | 17.0 | 1.12 | 0.024 | 0.004 |
| xto | 33.921 | 2.912 | 28.246 | 39.126 | 0.179 | 0.127 | 264.0 | 264.0 | 257.0 | 539.0 | 1.02 | 33.960 | 2.909 |
| yto | 5.857 | 0.515 | 4.873 | 6.783 | 0.039 | 0.028 | 174.0 | 174.0 | 175.0 | 1060.0 | 1.01 | 5.949 | 0.533 |
| sigma[0] | 0.249 | 0.044 | 0.173 | 0.330 | 0.002 | 0.001 | 683.0 | 661.0 | 789.0 | 896.0 | 1.00 | 0.248 | 0.045 |
| sigma[1] | 0.250 | 0.041 | 0.178 | 0.327 | 0.001 | 0.001 | 1793.0 | 1756.0 | 1864.0 | 1949.0 | 1.00 | 0.252 | 0.044 |
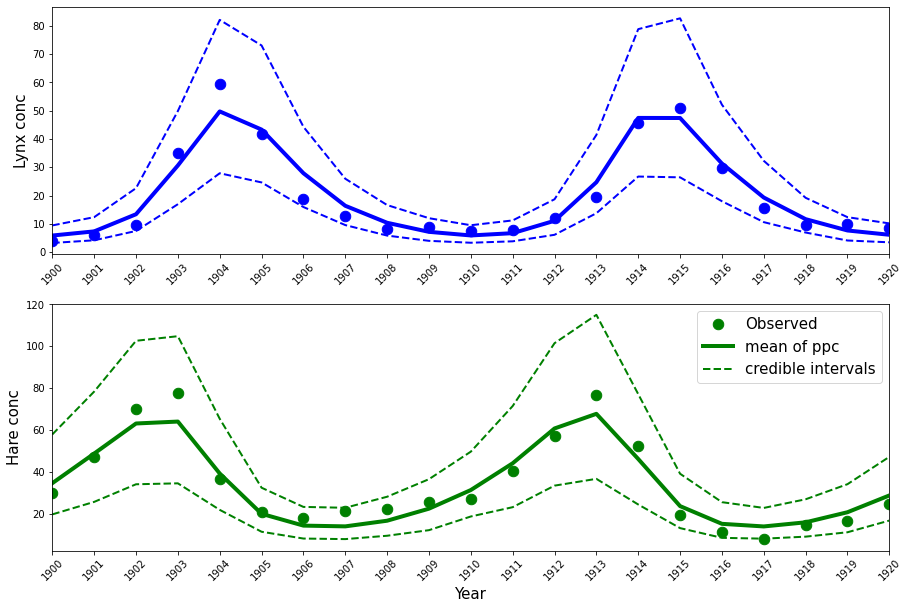
These estimates are almost identical to those obtained in the Stan tutorial (see the last two columns above), which is what we can expect. Posterior predictives can be drawn as below.
ppc_samples = pm.sample_posterior_predictive(trace, samples=1000, model=LV_model)["Y_obs"]
mean_ppc = ppc_samples.mean(axis=0)
CriL_ppc = np.percentile(ppc_samples, q=2.5, axis=0)
CriU_ppc = np.percentile(ppc_samples, q=97.5, axis=0)
/Users/CloudChaoszero/Documents/Projects-Dev/pymc3/pymc3/sampling.py:1687: UserWarning: samples parameter is smaller than nchains times ndraws, some draws and/or chains may not be represented in the returned posterior predictive sample
warnings.warn(
plt.figure(figsize=(15, 2 * (5)))
plt.subplot(2, 1, 1)
plt.plot(Year, Lynx, "o", color="b", lw=4, ms=10.5)
plt.plot(Year, mean_ppc[:, 1], color="b", lw=4)
plt.plot(Year, CriL_ppc[:, 1], "--", color="b", lw=2)
plt.plot(Year, CriU_ppc[:, 1], "--", color="b", lw=2)
plt.xlim([1900, 1920])
plt.ylabel("Lynx conc", fontsize=15)
plt.xticks(Year, rotation=45)
plt.subplot(2, 1, 2)
plt.plot(Year, Hare, "o", color="g", lw=4, ms=10.5, label="Observed")
plt.plot(Year, mean_ppc[:, 0], color="g", lw=4, label="mean of ppc")
plt.plot(Year, CriL_ppc[:, 0], "--", color="g", lw=2, label="credible intervals")
plt.plot(Year, CriU_ppc[:, 0], "--", color="g", lw=2)
plt.legend(fontsize=15)
plt.xlim([1900, 1920])
plt.xlabel("Year", fontsize=15)
plt.ylabel("Hare conc", fontsize=15)
plt.xticks(Year, rotation=45);
Efficient exploration of the posterior landscape with SMC#
It has been pointed out in several papers that the complex non-linear dynamics of an ODE results in a posterior landscape that is extremely difficult to navigate efficiently by many MCMC samplers. Thus, recently the curvature information of the posterior surface has been used to construct powerful geometrically aware samplers (Mark Girolami and Ben Calderhead, 2011) that perform extremely well in ODE inference problems. Another set of ideas suggest breaking down a complex inference task into a sequence of simpler tasks. In essence the idea is to use sequential-importance-sampling to sample from an artificial sequence of increasingly complex distributions where the first in the sequence is a distribution that is easy to sample from, the prior, and the last in the sequence is the actual complex target distribution. The associated importance distribution is constructed by moving the set of particles sampled at the previous step using a Markov kernel, say for example the MH kernel.
A simple way of building the sequence of distributions is to use a temperature \(\beta\), that is raised slowly from \(0\) to \(1\). Using this temperature variable \(\beta\) we can write down the annealed intermediate distribution as
Samplers that carry out sequential-importance-sampling from these artificial sequence of distributions, to avoid the difficult task of sampling directly from \(p(\boldsymbol{\theta}|\boldsymbol{y})\), are known as Sequential Monte Carlo (SMC) samplers (P Del Moral et al., 2006). The performance of these samplers are sensitive to the choice of the temperature schedule, that is the set of user-defined increasing values of \(\beta\) between \(0\) and \(1\). Fortunately, PyMC3 provides a version of the SMC sampler (Jianye Ching and Yi-Chu Chen, 2007) that automatically figures out this temperature schedule. Moreover, the PyMC3’s SMC sampler does not require the gradient of the log target density. As a result it is extremely easy to use this sampler for inference in ODE models. In the next example I will apply this SMC sampler to estimate the parameters of the Fitzhugh-Nagumo model.
The Fitzhugh-Nagumo model#
The Fitzhugh-Nagumo model given by
class FitzhughNagumoModel:
def __init__(self, times, y0=None):
self._y0 = np.array([-1, 1], dtype=np.float64)
self._times = times
def _simulate(self, parameters, times):
a, b, c = (float(x) for x in parameters)
def rhs(y, t, p):
V, R = y
dV_dt = (V - V**3 / 3 + R) * c
dR_dt = (V - a + b * R) / -c
return dV_dt, dR_dt
values = odeint(rhs, self._y0, times, (parameters,), rtol=1e-6, atol=1e-6)
return values
def simulate(self, x):
return self._simulate(x, self._times)
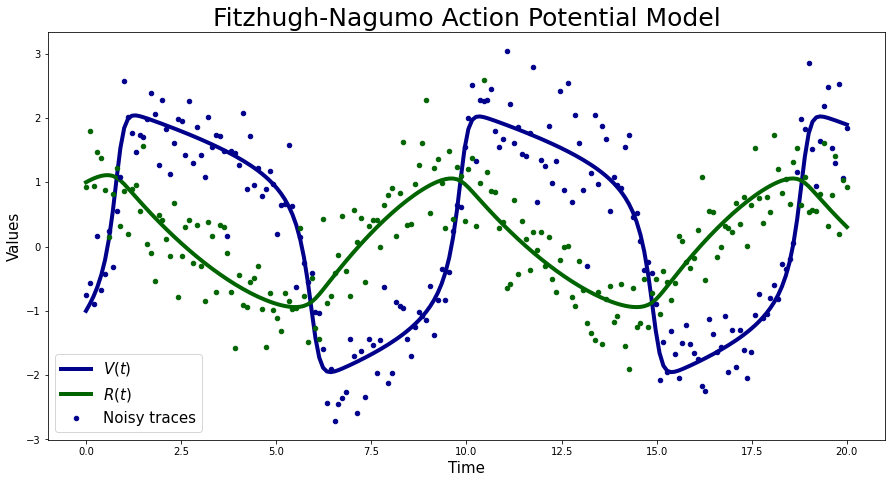
Simulated Data#
For this example I am going to use simulated data that is I will generate noisy traces from the forward model defined above with parameters \(\theta\) set to \((0.2,0.2,3)\) respectively and corrupted by i.i.d Gaussian noise with a standard deviation \(\sigma=0.5\). The initial values are set to \(V(0)=-1\) and \(R(0)=1\) respectively. Again following Mark Girolami and Ben Calderhead, 2011 I will assume that the initial values are known. These parameter values pushes the model into the oscillatory regime.
n_states = 2
n_times = 200
true_params = [0.2, 0.2, 3.0]
noise_sigma = 0.5
FN_solver_times = np.linspace(0, 20, n_times)
ode_model = FitzhughNagumoModel(FN_solver_times)
sim_data = ode_model.simulate(true_params)
np.random.seed(42)
Y_sim = sim_data + np.random.randn(n_times, n_states) * noise_sigma
plt.figure(figsize=(15, 7.5))
plt.plot(FN_solver_times, sim_data[:, 0], color="darkblue", lw=4, label=r"$V(t)$")
plt.plot(FN_solver_times, sim_data[:, 1], color="darkgreen", lw=4, label=r"$R(t)$")
plt.plot(FN_solver_times, Y_sim[:, 0], "o", color="darkblue", ms=4.5, label="Noisy traces")
plt.plot(FN_solver_times, Y_sim[:, 1], "o", color="darkgreen", ms=4.5)
plt.legend(fontsize=15)
plt.xlabel("Time", fontsize=15)
plt.ylabel("Values", fontsize=15)
plt.title("Fitzhugh-Nagumo Action Potential Model", fontsize=25);
Define a non-differentiable black-box op using Theano @as_op#
Remember that I told SMC sampler does not require gradients, this is by the way the case for other samplers such as the Metropolis-Hastings, Slice sampler that are also supported in PyMC3. For all these gradient-free samplers I will show a simple and quick way of wrapping the forward model i.e. the ODE solution in Theano. All we have to do is to simply to use the decorator as_op that converts a python function into a basic Theano Op. We also tell Theano using the as_op decorator that we have three parameters each being a Theano scalar. The output then is a Theano matrix whose columns are the state vectors.
import theano.tensor as tt
from theano.compile.ops import as_op
@as_op(itypes=[tt.dscalar, tt.dscalar, tt.dscalar], otypes=[tt.dmatrix])
def th_forward_model(param1, param2, param3):
param = [param1, param2, param3]
th_states = ode_model.simulate(param)
return th_states
Generative model#
Since I have corrupted the original traces with i.i.d Gaussian thus the likelihood is given by
Notice how I have used the start argument for this example. Just like pm.sample pm.sample_smc has a number of settings, but I found the default ones good enough for simple models such as this one.
draws = 1000
with pm.Model() as FN_model:
a = pm.Gamma("a", alpha=2, beta=1)
b = pm.Normal("b", mu=0, sigma=1)
c = pm.Uniform("c", lower=0.1, upper=10)
sigma = pm.HalfNormal("sigma", sigma=1)
forward = th_forward_model(a, b, c)
cov = np.eye(2) * sigma**2
Y_obs = pm.MvNormal("Y_obs", mu=forward, cov=cov, observed=Y_sim)
startsmc = {v.name: np.random.uniform(1e-3, 2, size=draws) for v in FN_model.free_RVs}
trace_FN = pm.sample_smc(draws, start=startsmc)
Initializing SMC sampler...
Sampling 2 chains in 2 jobs
Stage: 0 Beta: 0.009
Stage: 1 Beta: 0.029
Stage: 2 Beta: 0.043
Stage: 3 Beta: 0.054
Stage: 4 Beta: 0.065
Stage: 5 Beta: 0.087
Stage: 6 Beta: 0.118
Stage: 7 Beta: 0.163
Stage: 8 Beta: 0.229
Stage: 9 Beta: 0.317
Stage: 10 Beta: 0.456
Stage: 11 Beta: 0.645
Stage: 12 Beta: 0.914
Stage: 13 Beta: 1.000
Stage: 0 Beta: 0.009
Stage: 1 Beta: 0.031
Stage: 2 Beta: 0.046
Stage: 3 Beta: 0.056
Stage: 4 Beta: 0.067
Stage: 5 Beta: 0.088
Stage: 6 Beta: 0.122
Stage: 7 Beta: 0.169
Stage: 8 Beta: 0.235
Stage: 9 Beta: 0.339
Stage: 10 Beta: 0.494
Stage: 11 Beta: 0.695
Stage: 12 Beta: 0.999
Stage: 13 Beta: 1.000
az.plot_posterior(trace_FN, kind="hist", bins=30, color="seagreen");

Inference summary#
With pm.SMC, do I get similar performance to geometric MCMC samplers (see Mark Girolami and Ben Calderhead, 2011)? I think so !
results = [
az.summary(trace_FN, ["a"]),
az.summary(trace_FN, ["b"]),
az.summary(trace_FN, ["c"]),
az.summary(trace_FN, ["sigma"]),
]
results = pd.concat(results)
true_params.append(noise_sigma)
results["True values"] = pd.Series(np.array(true_params), index=results.index)
true_params.pop()
results
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_mean | ess_sd | ess_bulk | ess_tail | r_hat | True values | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| a | 0.261 | 0.020 | 0.223 | 0.298 | 0.007 | 0.005 | 8.0 | 8.0 | 8.0 | 108.0 | 1.18 | 0.2 |
| b | 0.149 | 0.084 | -0.003 | 0.304 | 0.003 | 0.002 | 1014.0 | 654.0 | 1009.0 | 1772.0 | 1.01 | 0.2 |
| c | 2.895 | 0.041 | 2.815 | 2.968 | 0.016 | 0.012 | 7.0 | 7.0 | 7.0 | 98.0 | 1.22 | 3.0 |
| sigma | 0.609 | 0.010 | 0.591 | 0.628 | 0.005 | 0.004 | 4.0 | 4.0 | 4.0 | 75.0 | 1.38 | 0.5 |
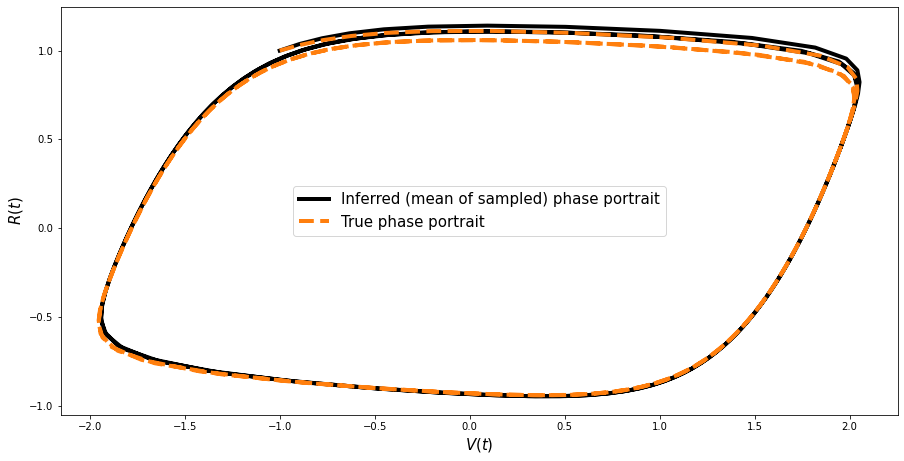
Reconstruction of the phase portrait#
Its good to check that we can reconstruct the (famous) pahse portrait for this model based on the obtained samples.
params = np.array([trace_FN.get_values("a"), trace_FN.get_values("b"), trace_FN.get_values("c")]).T
params.shape
new_values = []
for ind in range(len(params)):
ppc_sol = ode_model.simulate(params[ind])
new_values.append(ppc_sol)
new_values = np.array(new_values)
mean_values = np.mean(new_values, axis=0)
plt.figure(figsize=(15, 7.5))
plt.plot(
mean_values[:, 0],
mean_values[:, 1],
color="black",
lw=4,
label="Inferred (mean of sampled) phase portrait",
)
plt.plot(
sim_data[:, 0], sim_data[:, 1], "--", color="#ff7f0e", lw=4, ms=6, label="True phase portrait"
)
plt.legend(fontsize=15)
plt.xlabel(r"$V(t)$", fontsize=15)
plt.ylabel(r"$R(t)$", fontsize=15);
Perspectives#
Using some other ODE models#
I have tried to keep everything as general as possible. So, my custom ODE Op, the state and VSP evaluator as well as the cached solver are not tied to a specific ODE model. Thus, to use any other ODE model one only needs to implement a simulate_with_sensitivities method according to their own specific ODE model.
Other forms of differential equation (DDE, DAE, PDE)#
I hope the two examples have elucidated the applicability of PyMC3 in regards to fitting ODE models. Although ODEs are the most fundamental constituent of a mathematical model, there are indeed other forms of dynamical systems such as a delay differential equation (DDE), a differential algebraic equation (DAE) and the partial differential equation (PDE) whose parameter estimation is equally important. The SMC and for that matter any other non-gradient sampler supported by PyMC3 can be used to fit all these forms of differential equation, of course using the as_op. However, just like an ODE we can solve augmented systems of DDE/DAE along with their sensitivity equations. The sensitivity equations for a DDE and a DAE can be found in this recent paper, C Rackauckas et al., 2018 (Equation 9 and 10). Thus we can easily apply NUTS sampler to these models.
Stan already supports ODEs#
Well there are many problems where I believe SMC sampler would be more suitable than NUTS and thus its good to have that option.
Model selection#
Most ODE inference literature since Vladislav Vyshemirsky and Mark Girolami, 2008 recommend the usage of Bayes factor for the purpose of model selection/comparison. This involves the calculation of the marginal likelihood which is a much more nuanced topic and I would refrain from any discussion about that. Fortunately, the SMC sampler calculates the marginal likelihood as a by product so this can be used for obtaining Bayes factors. Follow PyMC3’s other tutorials for further information regarding how to obtain the marginal likelihood after running the SMC sampler.
Since we generally frame the ODE inference as a regression problem (along with the i.i.d measurement noise assumption in most cases) we can straight away use any of the supported information criterion, such as the widely available information criterion (WAIC), irrespective of what sampler is used for inference. See the PyMC3’s API for further information regarding WAIC.
Other AD packages#
Although this is a slight digression nonetheless I would still like to point out my observations on this issue. The approach that I have presented here for embedding an ODE (also extends to DDE/DAE) as a custom Op can be trivially carried forward to other AD packages such as TensorFlow and PyTorch. I had been able to use TensorFlow’s py_func to build a custom TensorFlow ODE Op and then use that in the Edward ppl. I would recommend this tutorial, for writing PyTorch extensions, to those who are interested in using the Pyro ppl.
%load_ext watermark
%watermark -n -u -v -iv -w
Last updated: Sat Mar 13 2021
Python implementation: CPython
Python version : 3.8.6
IPython version : 7.20.0
logging : 0.5.1.2
pandas : 1.2.1
theano : 1.1.2
numpy : 1.20.0
sys : 3.8.6 | packaged by conda-forge | (default, Jan 25 2021, 23:22:12)
[Clang 11.0.1 ]
matplotlib: None
pymc3 : 3.11.0
arviz : 0.11.0
Watermark: 2.1.0