
LKJ Cholesky Covariance Priors for Multivariate Normal Models#
While the inverse-Wishart distribution is the conjugate prior for the covariance matrix of a multivariate normal distribution, it is not very well-suited to modern Bayesian computational methods. For this reason, the LKJ prior is recommended when modeling the covariance matrix of a multivariate normal distribution.
To illustrate modelling covariance with the LKJ distribution, we first generate a two-dimensional normally-distributed sample data set.
import arviz as az
import numpy as np
import pymc as pm
from matplotlib import pyplot as plt
from matplotlib.lines import Line2D
from matplotlib.patches import Ellipse
print(f"Running on PyMC v{pm.__version__}")
Running on PyMC v5.9.0
%config InlineBackend.figure_format = 'retina'
RANDOM_SEED = 8927
rng = np.random.default_rng(RANDOM_SEED)
az.style.use("arviz-darkgrid")
N = 10000
mu_actual = np.array([1.0, -2.0])
sigmas_actual = np.array([0.7, 1.5])
Rho_actual = np.matrix([[1.0, -0.4], [-0.4, 1.0]])
Sigma_actual = np.diag(sigmas_actual) * Rho_actual * np.diag(sigmas_actual)
x = rng.multivariate_normal(mu_actual, Sigma_actual, size=N)
Sigma_actual
matrix([[ 0.49, -0.42],
[-0.42, 2.25]])
var, U = np.linalg.eig(Sigma_actual)
angle = 180.0 / np.pi * np.arccos(np.abs(U[0, 0]))
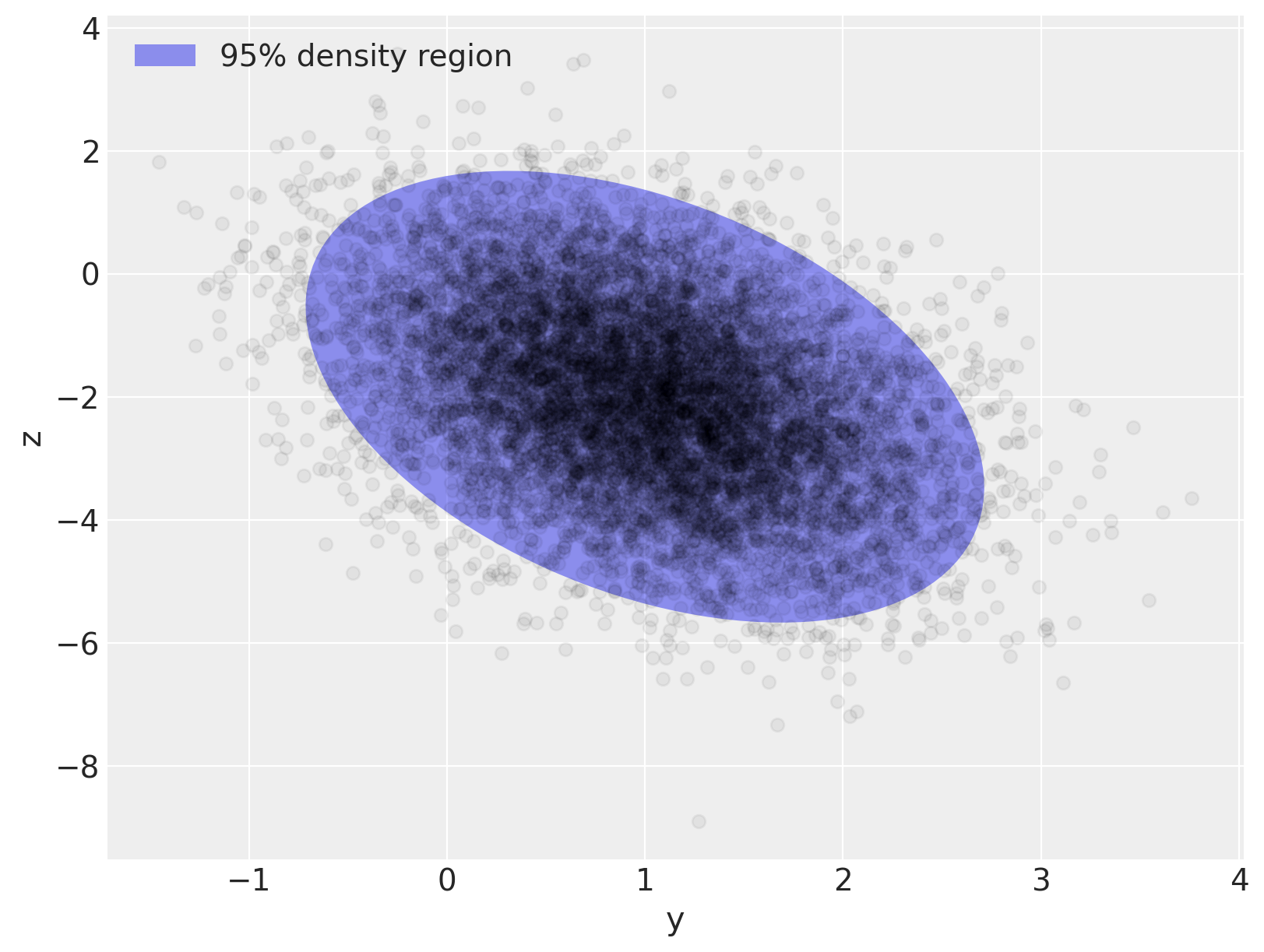
fig, ax = plt.subplots(figsize=(8, 6))
e = Ellipse(mu_actual, 2 * np.sqrt(5.991 * var[0]), 2 * np.sqrt(5.991 * var[1]), angle=angle)
e.set_alpha(0.5)
e.set_facecolor("C0")
e.set_zorder(10)
ax.add_artist(e)
ax.scatter(x[:, 0], x[:, 1], c="k", alpha=0.05, zorder=11)
ax.set_xlabel("y")
ax.set_ylabel("z")
rect = plt.Rectangle((0, 0), 1, 1, fc="C0", alpha=0.5)
ax.legend([rect], ["95% density region"], loc=2);
The sampling distribution for the multivariate normal model is \(\mathbf{x} \sim N(\mu, \Sigma)\), where \(\Sigma\) is the covariance matrix of the sampling distribution, with \(\Sigma_{ij} = \textrm{Cov}(x_i, x_j)\). The density of this distribution is
The LKJ distribution provides a prior on the correlation matrix, \(\mathbf{C} = \textrm{Corr}(x_i, x_j)\), which, combined with priors on the standard deviations of each component, induces a prior on the covariance matrix, \(\Sigma\). Since inverting \(\Sigma\) is numerically unstable and inefficient, it is computationally advantageous to use the Cholesky decomposition of \(\Sigma\), \(\Sigma = \mathbf{L} \mathbf{L}^{\top}\), where \(\mathbf{L}\) is a lower-triangular matrix. This decomposition allows computation of the term \((\mathbf{x} - \mu)^{\top} \Sigma^{-1} (\mathbf{x} - \mu)\) using back-substitution, which is more numerically stable and efficient than direct matrix inversion.
PyMC supports LKJ priors for the Cholesky decomposition of the covariance matrix via the pymc.LKJCholeskyCov distribution. This distribution has parameters n and sd_dist, which are the dimension of the observations, \(\mathbf{x}\), and the PyMC distribution of the component standard deviations, respectively. It also has a hyperparamter eta, which controls the amount of correlation between components of \(\mathbf{x}\). The LKJ distribution has the density \(f(\mathbf{C}\ |\ \eta) \propto |\mathbf{C}|^{\eta - 1}\), so \(\eta = 1\) leads to a uniform distribution on correlation matrices, while the magnitude of correlations between components decreases as \(\eta \to \infty\).
In this example, we model the standard deviations with \(\textrm{Exponential}(1.0)\) priors, and the correlation matrix as \(\mathbf{C} \sim \textrm{LKJ}(\eta = 2)\).
with pm.Model() as m:
packed_L = pm.LKJCholeskyCov(
"packed_L", n=2, eta=2.0, sd_dist=pm.Exponential.dist(1.0, shape=2), compute_corr=False
)
Since the Cholesky decomposition of \(\Sigma\) is lower triangular, LKJCholeskyCov only stores the diagonal and sub-diagonal entries, for efficiency:
packed_L.eval()
array([ 2.60423567, -1.28344686, 0.65139719])
We use expand_packed_triangular to transform this vector into the lower triangular matrix \(\mathbf{L}\), which appears in the Cholesky decomposition \(\Sigma = \mathbf{L} \mathbf{L}^{\top}\).
with m:
L = pm.expand_packed_triangular(2, packed_L)
Sigma = L.dot(L.T)
L.eval().shape
(2, 2)
Often however, you’ll be interested in the posterior distribution of the correlations matrix and of the standard deviations, not in the posterior Cholesky covariance matrix per se. Why? Because the correlations and standard deviations are easier to interpret and often have a scientific meaning in the model. As of PyMC v4, the compute_corr argument is set to True by default, which returns a tuple consisting of the Cholesky decomposition, the correlations matrix, and the standard deviations.
coords = {"axis": ["y", "z"], "axis_bis": ["y", "z"], "obs_id": np.arange(N)}
with pm.Model(coords=coords) as model:
chol, corr, stds = pm.LKJCholeskyCov(
"chol", n=2, eta=2.0, sd_dist=pm.Exponential.dist(1.0, shape=2)
)
cov = pm.Deterministic("cov", chol.dot(chol.T), dims=("axis", "axis_bis"))
To complete our model, we place independent, weakly regularizing priors, \(N(0, 1.5),\) on \(\mu\):
with model:
mu = pm.Normal("mu", 0.0, sigma=1.5, dims="axis")
obs = pm.MvNormal("obs", mu, chol=chol, observed=x, dims=("obs_id", "axis"))
We sample from this model using NUTS and give the trace to arviz for summarization:
with model:
trace = pm.sample(
random_seed=rng,
idata_kwargs={"dims": {"chol_stds": ["axis"], "chol_corr": ["axis", "axis_bis"]}},
)
az.summary(trace, var_names="~chol", round_to=2)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [chol, mu]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 31 seconds.
/home/erik/mambaforge/envs/pymc_examples/lib/python3.11/site-packages/arviz/stats/diagnostics.py:592: RuntimeWarning: invalid value encountered in scalar divide
(between_chain_variance / within_chain_variance + num_samples - 1) / (num_samples)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| mu[y] | 1.00 | 0.01 | 0.99 | 1.01 | 0.0 | 0.0 | 4121.45 | 3183.18 | 1.0 |
| mu[z] | -2.01 | 0.01 | -2.04 | -1.99 | 0.0 | 0.0 | 4649.42 | 3413.88 | 1.0 |
| chol_corr[y, y] | 1.00 | 0.00 | 1.00 | 1.00 | 0.0 | 0.0 | 4000.00 | 4000.00 | NaN |
| chol_corr[y, z] | -0.40 | 0.01 | -0.42 | -0.39 | 0.0 | 0.0 | 4986.71 | 3442.98 | 1.0 |
| chol_corr[z, y] | -0.40 | 0.01 | -0.42 | -0.39 | 0.0 | 0.0 | 4986.71 | 3442.98 | 1.0 |
| chol_corr[z, z] | 1.00 | 0.00 | 1.00 | 1.00 | 0.0 | 0.0 | 3458.80 | 3722.51 | 1.0 |
| chol_stds[y] | 0.70 | 0.01 | 0.69 | 0.71 | 0.0 | 0.0 | 5112.65 | 3038.55 | 1.0 |
| chol_stds[z] | 1.49 | 0.01 | 1.47 | 1.51 | 0.0 | 0.0 | 5330.27 | 3156.89 | 1.0 |
| cov[y, y] | 0.49 | 0.01 | 0.48 | 0.51 | 0.0 | 0.0 | 5112.65 | 3038.55 | 1.0 |
| cov[y, z] | -0.42 | 0.01 | -0.44 | -0.40 | 0.0 | 0.0 | 4320.77 | 3391.79 | 1.0 |
| cov[z, y] | -0.42 | 0.01 | -0.44 | -0.40 | 0.0 | 0.0 | 4320.77 | 3391.79 | 1.0 |
| cov[z, z] | 2.23 | 0.03 | 2.17 | 2.28 | 0.0 | 0.0 | 5330.27 | 3156.89 | 1.0 |
Sampling went smoothly: no divergences and good r-hats (except for the diagonal elements of the correlation matrix - however, these are not a concern, because, they should be equal to 1 for each sample for each chain and the variance of a constant value isn’t defined. If one of the diagonal elements has r_hat defined, it’s likely due to tiny numerical errors).
You can also see that the sampler recovered the true means, correlations and standard deviations. As often, that will be clearer in a graph:
az.plot_trace(
trace,
var_names="chol_corr",
coords={"axis": "y", "axis_bis": "z"},
lines=[("chol_corr", {}, Rho_actual[0, 1])],
);

az.plot_trace(
trace,
var_names=["~chol", "~chol_corr"],
compact=True,
lines=[
("mu", {}, mu_actual),
("cov", {}, Sigma_actual),
("chol_stds", {}, sigmas_actual),
],
);
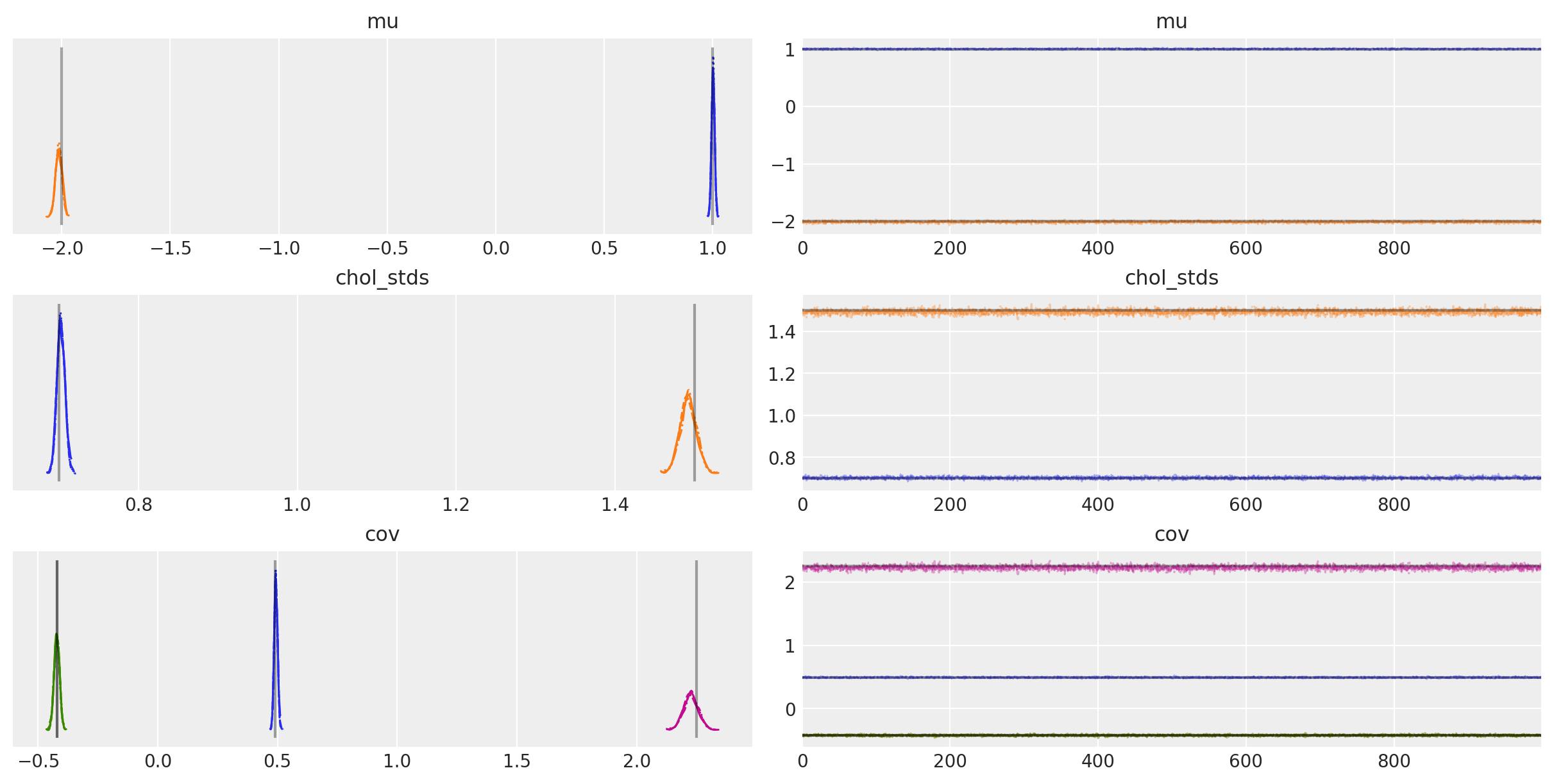
The posterior expected values are very close to the true value of each component! How close exactly? Let’s compute the percentage of closeness for \(\mu\) and \(\Sigma\):
mu_post = trace.posterior["mu"].mean(("chain", "draw")).values
(1 - mu_post / mu_actual).round(2)
array([-0. , -0.01])
Sigma_post = trace.posterior["cov"].mean(("chain", "draw")).values
(1 - Sigma_post / Sigma_actual).round(2)
array([[-0.01, -0. ],
[-0. , 0.01]])
So the posterior means are within 1% of the true values of \(\mu\) and \(\Sigma\).
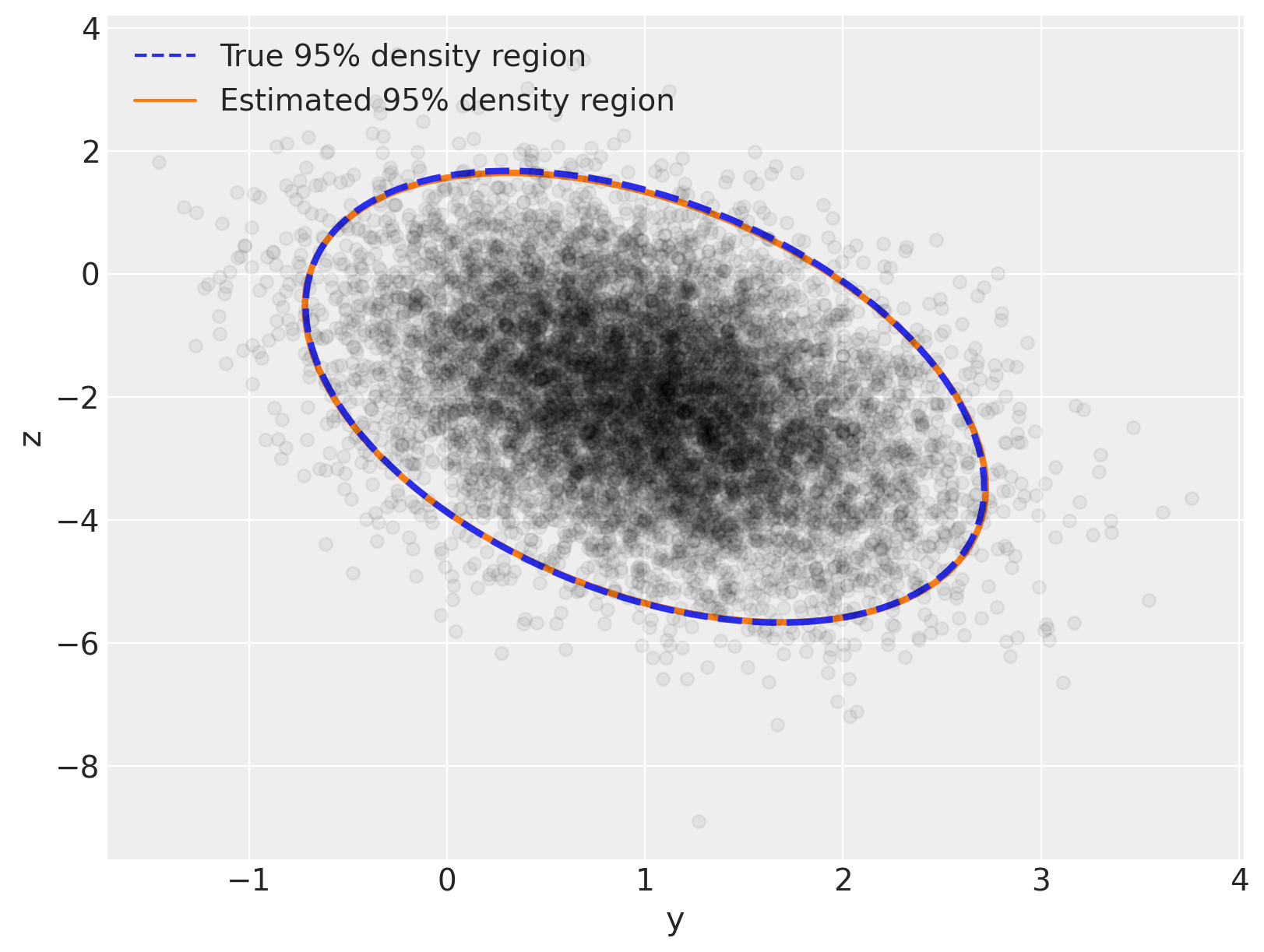
Now let’s replicate the plot we did at the beginning, but let’s overlay the posterior distribution on top of the true distribution – you’ll see there is excellent visual agreement between both:
var_post, U_post = np.linalg.eig(Sigma_post)
angle_post = 180.0 / np.pi * np.arccos(np.abs(U_post[0, 0]))
fig, ax = plt.subplots(figsize=(8, 6))
e = Ellipse(
mu_actual,
2 * np.sqrt(5.991 * var[0]),
2 * np.sqrt(5.991 * var[1]),
angle=angle,
linewidth=3,
linestyle="dashed",
)
e.set_edgecolor("C0")
e.set_zorder(11)
e.set_fill(False)
ax.add_artist(e)
e_post = Ellipse(
mu_post,
2 * np.sqrt(5.991 * var_post[0]),
2 * np.sqrt(5.991 * var_post[1]),
angle=angle_post,
linewidth=3,
)
e_post.set_edgecolor("C1")
e_post.set_zorder(10)
e_post.set_fill(False)
ax.add_artist(e_post)
ax.scatter(x[:, 0], x[:, 1], c="k", alpha=0.05, zorder=11)
ax.set_xlabel("y")
ax.set_ylabel("z")
line = Line2D([], [], color="C0", linestyle="dashed", label="True 95% density region")
line_post = Line2D([], [], color="C1", label="Estimated 95% density region")
ax.legend(
handles=[line, line_post],
loc=2,
);
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor,xarray
Last updated: Thu Oct 12 2023
Python implementation: CPython
Python version : 3.11.6
IPython version : 8.16.1
pytensor: 2.17.1
xarray : 2023.9.0
numpy : 1.25.2
matplotlib: 3.8.0
pymc : 5.9.0
arviz : 0.16.1
Watermark: 2.4.3