



Counterfactual generation using pymc do-operator#
%config InlineBackend.figure_format = 'retina' # high resolution figures
az.style.use("arviz-variat")
rng = np.random.default_rng(42)
SEED = 8927
Introduction#
In the realm of data science and analytics, understanding the causal relationships between variables is paramount. While traditional statistical methods have provided insights into these relationships, the advent of probabilistic programming has ushered in a new era of causal analysis. In this article, we will explore the power of counterfactuals in causal analysis using the PyMC framework, with a special focus on the “do-operator.” Counterfactuals are essentially “what-if” scenarios that allow us to understand the potential outcomes had a different action been taken or a different condition been present. By leveraging the PyMC framework and its “do-operator,” we can programmatically simulate these scenarios, giving us a deeper understanding of the relationships between predictors and target variables.
Through a step-by-step guide, we will delve into the process of building a PyMC model skeleton, generating data using the do-operator, and validating the relationships captured by the model. Furthermore, we will explore the magic of the do-operator in simulating different ‘what-if’ scenarios, akin to programmatic A/B testing.
Step 1. Build a pymc model skeleton
Step 2. Use model skeleton and generate data using do-operator to infuse relationship between predictors and target variable (ssshhh, that’s a hidden superhero feature of do-operator ;) )
Step 3. Use observe-operator to assign generated data on the model skeleton
Step 4. Create samples and validate that the infused relationship between predictors and target variable are captured by the model samples (isn’t that what we expect a predictive model to do ;) )
Step 5. Use do-operator to time travel, and generate target variable with different ‘what-if’ scenarios (basically mimic A/B testing…programatically)
Step 1. Build a pymc model skeleton#
For this demo, we are building a very simple Linear Regression model.
Predictor — ‘a’, ‘b’, ‘c’
Target Variable — ‘y’
Coefficients —
‘beta_ay’ -> coefficient of |a|
‘beta_by’ -> coefficient of |b|
‘beta_cy’ -> coefficient of |c|
with pm.Model(coords={"i": [0]}) as model_generative:
# priors
beta_y0 = pm.Normal("beta_y0")
beta_ay = pm.Normal("beta_ay")
beta_by = pm.Normal("beta_by")
beta_cy = pm.Normal("beta_cy")
# observation noise on Y
sigma_y = pm.HalfNormal("sigma_y")
# core nodes and causal relationships
a = pm.Normal("a", mu=0, sigma=1, dims="i")
b = pm.Normal("b", mu=0, sigma=1, dims="i")
c = pm.Normal("c", mu=0, sigma=1, dims="i")
y_mu = pm.Deterministic(
"y_mu", beta_y0 + (beta_ay * a) + (beta_by * b) + (beta_cy * c), dims="i"
)
y = pm.Normal("y", mu=y_mu, sigma=sigma_y, dims="i")
pm.model_to_graphviz(model_generative)

Step 2. Use model skeleton and generate data using do-operator to infuse relationship between predictors and target variable. We will use this generated data for modelling later.#
Let’s first define the predictors relationship with target variable.
true_values = {"beta_ay": 1.5, "beta_by": 0.7, "beta_cy": 0.3, "sigma_y": 0.2, "beta_y0": 0.0}
Basically what we are saying here is, we are intentionally defining the coefficient values, which we expect predictive model to predict later on.
Now the magic begins. We will use do-operator to use this dictionary and sample data variables. How do we do this ? Simple by passing two arguments to pymc do-operator. First, the model skeleton object. And second, the coefficient dictionary.
model_simulate = pm.do(model_generative, true_values)
This will create a new model object with the coefficent variables values infused.
model_simulate.to_graphviz()

The gray shades on the coefficient variables depicts the tale. Check the previous model graph, it was all white.
Now, all we have to do is generate samples, the known pymc way.
Lets generate 100 samples.
N = 100
with model_simulate:
simulate = pm.sample_prior_predictive(samples=N)
Sampling: [a, b, c, y]
We know that this generates an Arviz object, and since we have called sample_prior_predictive, hence the object will only contain priors.
simulate
-
<xarray.Dataset> Size: 5kB Dimensions: (chain: 1, draw: 100, i: 1) Coordinates: * chain (chain) int64 8B 0 * draw (draw) int64 800B 0 1 2 3 4 5 6 7 8 ... 91 92 93 94 95 96 97 98 99 * i (i) int64 8B 0 Data variables: b (chain, draw, i) float64 800B 0.9658 0.04536 ... -0.08396 0.5739 y (chain, draw, i) float64 800B 0.6151 -1.398 ... -0.2965 0.7868 y_mu (chain, draw, i) float64 800B 0.4538 -1.286 1.129 ... -0.4846 0.924 c (chain, draw, i) float64 800B -1.584 -1.12 ... -1.041 -0.3577 a (chain, draw, i) float64 800B 0.1686 -0.6548 ... -0.07567 0.4198 Attributes: created_at: 2026-02-12T08:05:25.902369+00:00 arviz_version: 0.23.1 inference_library: pymc inference_library_version: 5.27.1 -
<xarray.Dataset> Size: 40B Dimensions: () Data variables: beta_cy float64 8B 0.3 beta_by float64 8B 0.7 beta_ay float64 8B 1.5 beta_y0 float64 8B 0.0 sigma_y float64 8B 0.2 Attributes: created_at: 2026-02-12T08:05:25.907365+00:00 arviz_version: 0.23.1 inference_library: pymc inference_library_version: 5.27.1
Extract the sampled prior data into a pandas dataframe.
observed = {
"a": simulate.prior["a"].values.flatten(),
"b": simulate.prior["b"].values.flatten(),
"c": simulate.prior["c"].values.flatten(),
"y": simulate.prior["y"].values.flatten(),
}
df = pd.DataFrame(observed)
print(df.shape)
df.head(5)
(100, 4)
| a | b | c | y | |
|---|---|---|---|---|
| 0 | 0.168609 | 0.965789 | -1.583881 | 0.615137 |
| 1 | -0.654816 | 0.045357 | -1.119634 | -1.397617 |
| 2 | 0.330262 | 0.955123 | -0.115252 | 0.939636 |
| 3 | -0.919746 | -0.629055 | 1.350298 | -1.482930 |
| 4 | -0.527499 | 0.046205 | -0.387889 | -1.003153 |
Ok, so now we are all set with a sample data.
Step 3. Use observe-operator to assign generated data on the model skeleton#
Now, this is another cool feature of pymc newly introduced observe method. Observe method, takes in a model skeleton and the dictionary with the data for the variables we want to infuse into the model.
data_dict = {"a": df["a"], "b": df["b"], "c": df["c"], "y": df["y"]}
model_inference = pm.observe(model_generative, data_dict)
model_inference.set_dim("i", N, coord_values=np.arange(N))
pm.model_to_graphviz(model_inference)

See the gray matter again. This time we have observed data infused into the model, and we have to sample for the coefficient and other parameters.
So, lets sample.
Step 4. Create samples and validate that the infused relationship between predictors and target variable are captured by the model samples#
with model_inference:
idata = pm.sample(random_seed=SEED)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_cy, beta_by, beta_ay, beta_y0, sigma_y]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
Now, lets validate if model captured the infused coefficient values in the data.
pc = az.plot_dist(
idata,
var_names=list(true_values.keys()),
)
az.add_lines(pc, true_values);
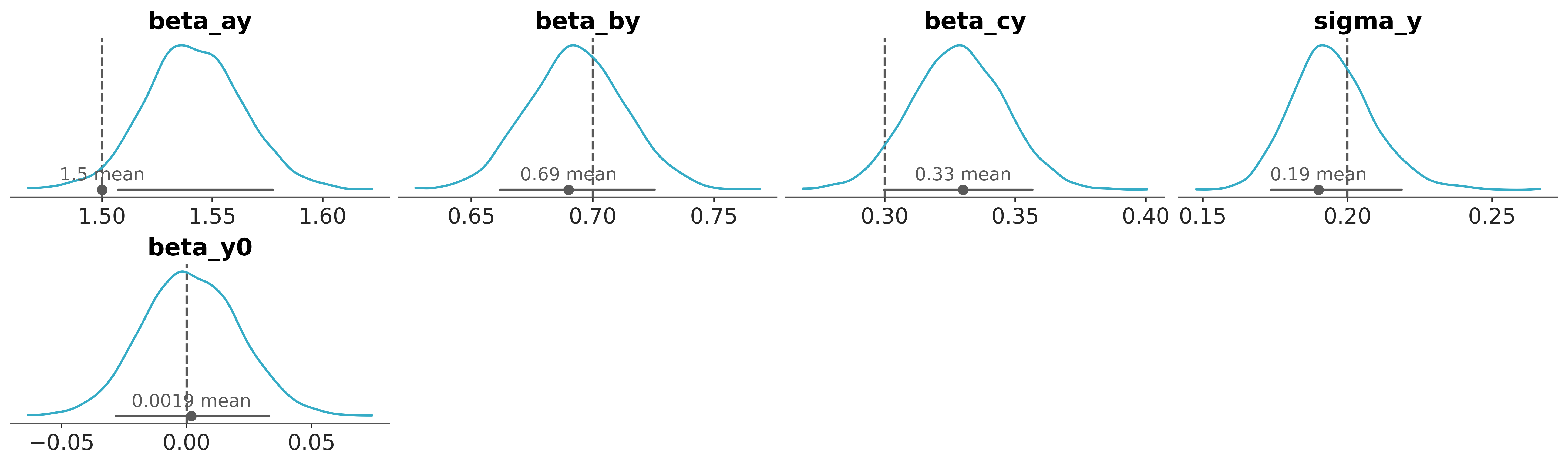
BAM ! Pretty nice fit !
Now, lets do what we are supposed to do ! Counterfactuals.
Basically, this is about generating target variable values with different predictor values. Basically, answering what if questions !
What-if there was all ‘b’ values as 0 ?
What-if all ‘b’ values were double ?
How to do this ? Here you go..
Step 5. Use do-operator to time travel, and generate target variable with different ‘what-if’ scenarios.#
Since, we want to experiment with ‘b’, lets first assign observed values to ‘a’ and ‘c’. Not to ‘y’, because that’s what we want to sample. Correct !
model_counterfactual = pm.do(model_inference, {"a": df["a"], "c": df["c"]})
Now, lets begin the fun part. Let’s generate counterfactuals.
Scenario 1 :- What if all values for ‘b’ were 0 ?#
model_b0 = pm.do(model_counterfactual, {"b": np.zeros(N, dtype="int32")}, prune_vars=True)
model_b1 = pm.do(model_counterfactual, {"b": df["b"]}, prune_vars=True)
Just sample.
# Sample when 'b' was 0: P(y | (a,c), do(b=0))
idata_b0 = pm.sample_posterior_predictive(
idata,
model=model_b0,
predictions=True,
var_names=["y_mu"],
random_seed=SEED,
)
# Sample when 'b' was as observed: P(y | (a,c), do(b=observed))
idata_b1 = pm.sample_posterior_predictive(
idata,
model=model_b1,
predictions=True,
var_names=["y_mu"],
random_seed=SEED,
)
Sampling: []
Sampling: []
Some basic python and here we have the counterfactuals.
df["b_scenario_1"] = 0
df["y_scenario_1"] = (
idata_b0.predictions.y_mu.mean(("chain", "draw")).values.reshape(1, -1).flatten()
)
df.head(5)
| a | b | c | y | b_scenario_1 | y_scenario_1 | |
|---|---|---|---|---|---|---|
| 0 | 0.168609 | 0.965789 | -1.583881 | 0.615137 | 0 | -0.257788 |
| 1 | -0.654816 | 0.045357 | -1.119634 | -1.397617 | 0 | -1.374868 |
| 2 | 0.330262 | 0.955123 | -0.115252 | 0.939636 | 0 | 0.473174 |
| 3 | -0.919746 | -0.629055 | 1.350298 | -1.482930 | 0 | -0.973051 |
| 4 | -0.527499 | 0.046205 | -0.387889 | -1.003153 | 0 | -0.938561 |
Scenario 2: What if ‘b’ was 5 times as observed#
model_b0 = pm.do(model_counterfactual, {"b": 5 * df["b"]}, prune_vars=True)
model_b1 = pm.do(model_counterfactual, {"b": df["b"]}, prune_vars=True)
Sample.
# Sample when 'b' was 5 times b: P(y | (a,c), do(b=5*b))
idata_b0 = pm.sample_posterior_predictive(
idata,
model=model_b0,
predictions=True,
var_names=["y_mu"],
random_seed=SEED,
)
# Sample when 'b' was as observed: P(y | (a,c), do(b=observed))
idata_b1 = pm.sample_posterior_predictive(
idata,
model=model_b1,
predictions=True,
var_names=["y_mu"],
random_seed=SEED,
)
df["b_scenario_2"] = 5 * df["b"]
df["y_scenario_2"] = (
idata_b0.predictions.y_mu.mean(("chain", "draw")).values.reshape(1, -1).flatten()
)
df.head(5)
Sampling: []
Sampling: []
| a | b | c | y | b_scenario_1 | y_scenario_1 | b_scenario_2 | y_scenario_2 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0.168609 | 0.965789 | -1.583881 | 0.615137 | 0 | -0.257788 | 4.828943 | 3.090282 |
| 1 | -0.654816 | 0.045357 | -1.119634 | -1.397617 | 0 | -1.374868 | 0.226784 | -1.217631 |
| 2 | 0.330262 | 0.955123 | -0.115252 | 0.939636 | 0 | 0.473174 | 4.775613 | 3.784268 |
| 3 | -0.919746 | -0.629055 | 1.350298 | -1.482930 | 0 | -0.973051 | -3.145274 | -3.153777 |
| 4 | -0.527499 | 0.046205 | -0.387889 | -1.003153 | 0 | -0.938561 | 0.231026 | -0.778383 |
Ok, so now you got the idea. It’s an open playground. Go back in time, change whatever you want to change, and see how output changes.
This opens the door for many more possibilities in various use cases. Especially, Causal Analytics !
References#
https://medium.com/@khandelwal-shekhar/counterfactuals-for-causal-analysis-via-pymc-do-operator-234ba04e4e80
https://www.pymc-labs.io/blog-posts/causal-analysis-with-pymc-answering-what-if-with-the-new-do-operator/
Watermark#
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor
Last updated: Thu, 12 Feb 2026
Python implementation: CPython
Python version : 3.13.11
IPython version : 8.29.0
pytensor: 2.37.0
arviz : 0.23.1
numpy : 2.2.6
pandas: 2.2.3
pymc : 5.27.1
Watermark: 2.6.0
License notice#
All the notebooks in this example gallery are provided under the MIT License which allows modification, and redistribution for any use provided the copyright and license notices are preserved.
Citing PyMC examples#
To cite this notebook, use the DOI provided by Zenodo for the pymc-examples repository.
Important
Many notebooks are adapted from other sources: blogs, books… In such cases you should cite the original source as well.
Also remember to cite the relevant libraries used by your code.
Here is an citation template in bibtex:
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
which once rendered could look like: