
Prior and Posterior Predictive Checks#
Posterior predictive checks (PPCs) are a great way to validate a model. The idea is to generate data from the model using parameters from draws from the posterior.
Elaborating slightly, one can say that PPCs analyze the degree to which data generated from the model deviate from data generated from the true distribution. So, often you will want to know if, for example, your posterior distribution is approximating your underlying distribution. The visualization aspect of this model evaluation method is also great for a ‘sense check’ or explaining your model to others and getting criticism.
Prior predictive checks are also a crucial part of the Bayesian modeling workflow. Basically, they have two main benefits:
They allow you to check whether you are indeed incorporating scientific knowledge into your model – in short, they help you check how credible your assumptions before seeing the data are.
They can help sampling considerably, especially for generalized linear models, where the outcome space and the parameter space diverge because of the link function.
Here, we will implement a general routine to draw samples from the observed nodes of a model. The models are basic but they will be a steppingstone for creating your own routines. If you want to see how to do prior and posterior predictive checks in a more complex, multidimensional model, you can check this notebook. Now, let’s sample!
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import xarray as xr
from scipy.special import expit as logistic
import pymc as pm
print(f"Running on PyMC v{pm.__version__}")
Running on PyMC v5.27.0+78.ge5ea0af35.dirty
az.style.use("arviz-variat")
RANDOM_SEED = 58
rng = np.random.default_rng(RANDOM_SEED)
def standardize(series):
"""Standardize a pandas series"""
return (series - series.mean()) / series.std()
Lets generate a very simple linear regression model. On purpose, I’ll simulate data that don’t come from a standard Normal (you’ll see why later):
N = 100
true_a, true_b, predictor = 0.5, 3.0, rng.normal(loc=2, scale=6, size=N)
true_mu = true_a + true_b * predictor
true_sd = 2.0
outcome = rng.normal(loc=true_mu, scale=true_sd, size=N)
f"{predictor.mean():.2f}, {predictor.std():.2f}, {outcome.mean():.2f}, {outcome.std():.2f}"
'1.59, 5.69, 4.97, 17.54'
As you can see, variation in our predictor and outcome are quite high – which is often the case with real data. And sometimes, the sampler won’t like this – and you don’t want to make the sampler angry when you’re a Bayesian… So, let’s do what you’ll often have to do with real data: standardize! This way, our predictor and outcome will have a mean of 0 and std of 1, and the sampler will be much, much happier:
predictor_scaled = standardize(predictor)
outcome_scaled = standardize(outcome)
f"{predictor_scaled.mean():.2f}, {predictor_scaled.std():.2f}, {outcome_scaled.mean():.2f}, {outcome_scaled.std():.2f}"
'0.00, 1.00, -0.00, 1.00'
And now, let’s write the model with conventional flat priors and sample prior predictive samples:
with pm.Model() as model_1:
a = pm.Normal("a", 0.0, 10.0)
b = pm.Normal("b", 0.0, 10.0)
mu = a + b * predictor_scaled
sigma = pm.Exponential("sigma", 1.0)
pm.Normal("obs", mu=mu, sigma=sigma, observed=outcome_scaled)
idata = pm.sample_prior_predictive(draws=50, random_seed=rng)
Sampling: [a, b, obs, sigma]
What do these priors mean? It’s always hard to tell on paper – the best is to plot their implication on the outcome scale, like that:
_, ax = plt.subplots()
x = xr.DataArray(np.linspace(-2, 2, 50), dims=["plot_dim"])
prior = idata.prior
y = prior["a"] + prior["b"] * x
ax.plot(x, y.stack(sample=("chain", "draw")), c="k", alpha=0.4)
ax.set_xlabel("Predictor (stdz)")
ax.set_ylabel("Mean Outcome (stdz)")
ax.set_title("Prior predictive checks -- Flat priors");
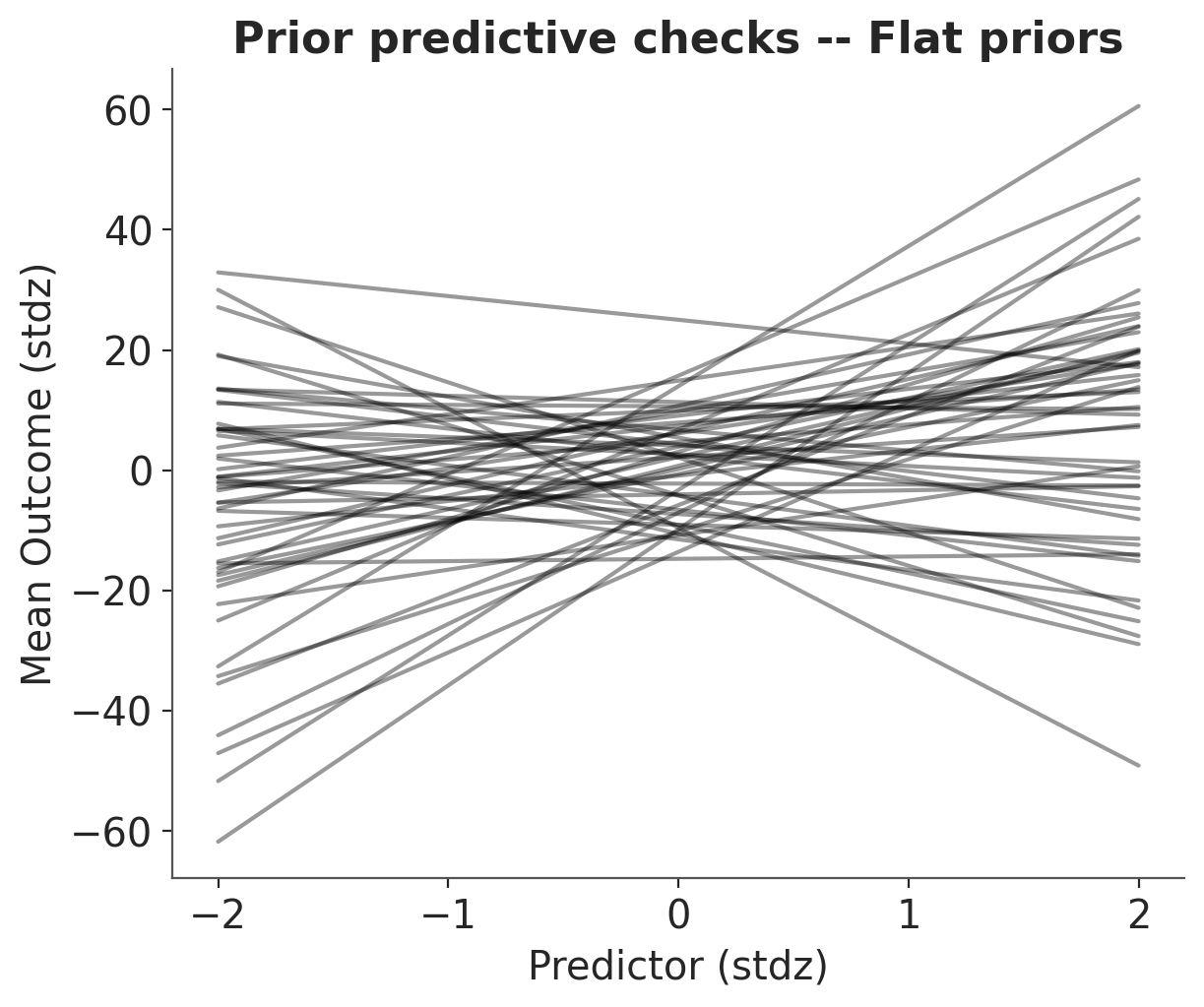
These priors allow for absurdly strong relationships between the outcome and predictor. Of course, the choice of prior always depends on your model and data, but look at the scale of the y axis: the outcome can go from -40 to +40 standard deviations (remember, the data are standardized). I hope you will agree this is way too permissive – we can do better! Let’s use weakly informative priors and see what they yield. In a real case study, this is the part where you incorporate scientific knowledge into your model:
with pm.Model() as model_1:
a = pm.Normal("a", 0.0, 0.5)
b = pm.Normal("b", 0.0, 1.0)
mu = a + b * predictor_scaled
sigma = pm.Exponential("sigma", 1.0)
pm.Normal("obs", mu=mu, sigma=sigma, observed=outcome_scaled)
idata = pm.sample_prior_predictive(draws=50, random_seed=rng)
Sampling: [a, b, obs, sigma]
_, ax = plt.subplots()
x = xr.DataArray(np.linspace(-2, 2, 50), dims=["plot_dim"])
prior = idata.prior
y = prior["a"] + prior["b"] * x
ax.plot(x, y.stack(sample=("chain", "draw")), c="k", alpha=0.4)
ax.set_xlabel("Predictor (stdz)")
ax.set_ylabel("Mean Outcome (stdz)")
ax.set_title("Prior predictive checks -- Weakly regularizing priors");
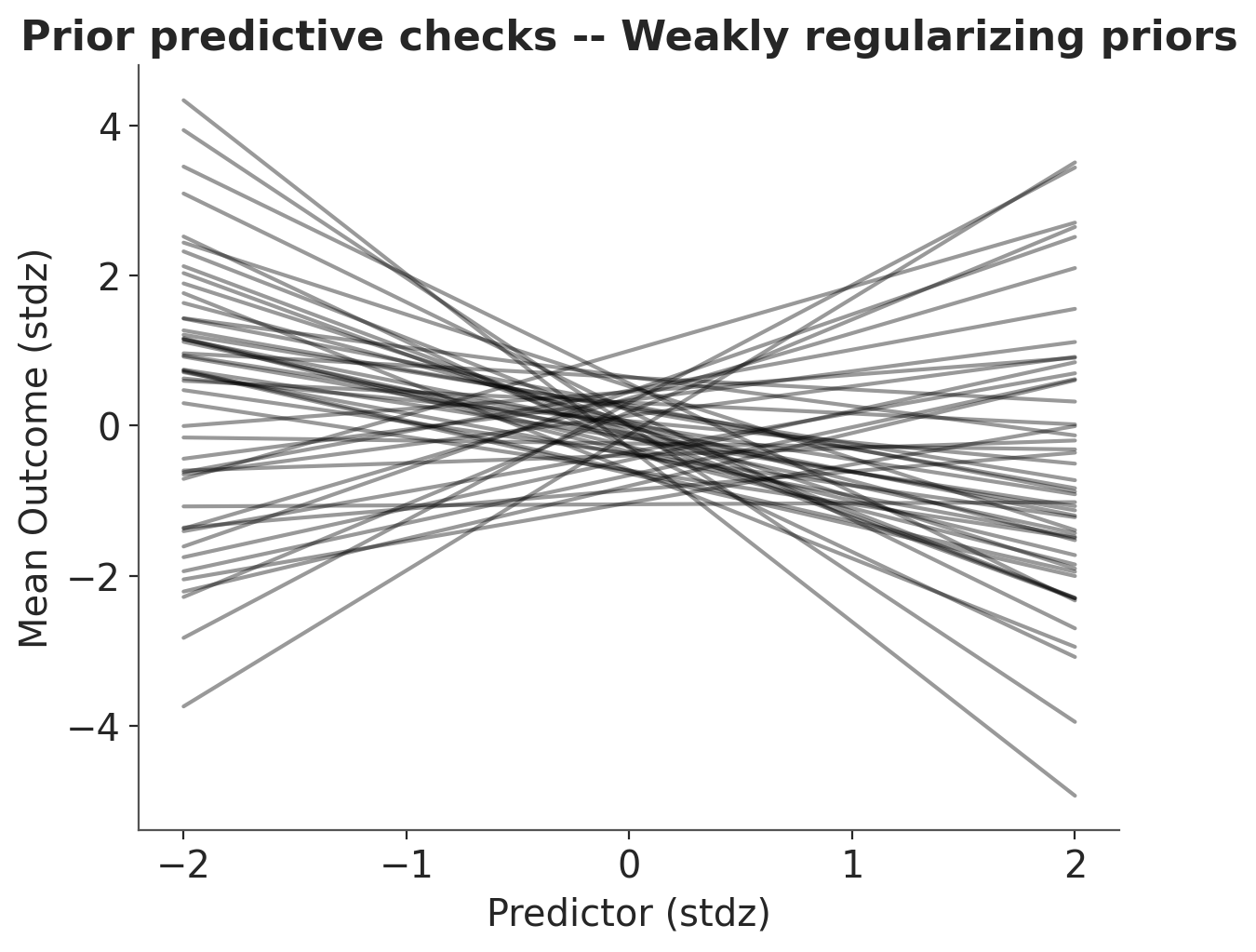
Well that’s way better! There are still very strong relationships, but at least now the outcome stays in the realm of possibilities. Now, it’s time to party – if by “party” you mean “run the model”, of course.
with model_1:
idata.update(pm.sample(1000, tune=2000, random_seed=rng))
az.plot_rank_dist(idata);
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [a, b, sigma]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 2 seconds.
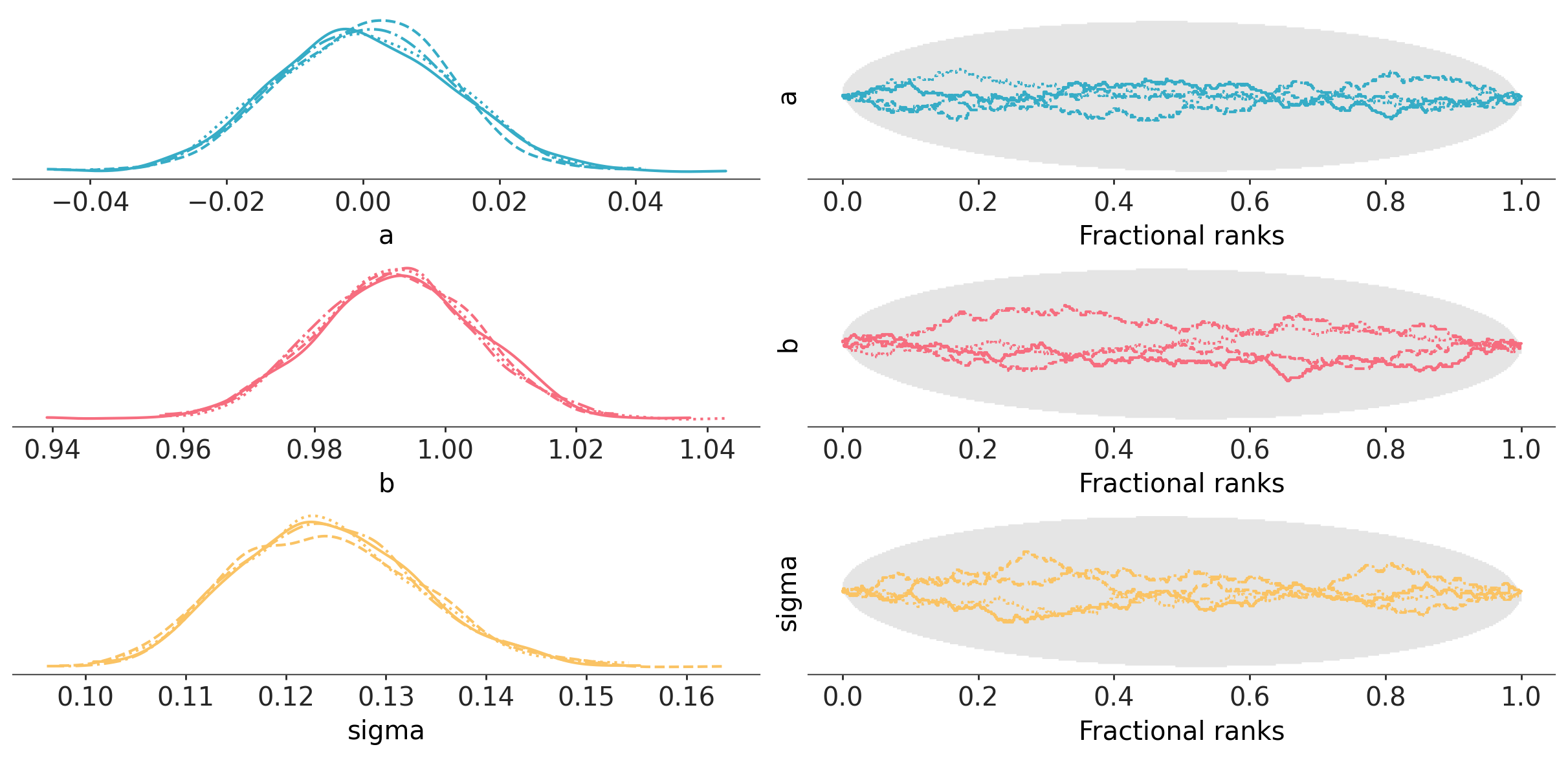
Everything ran smoothly, but it’s often difficult to understand what the parameters’ values mean when analyzing a trace plot or table summary – even more so here, as the parameters live in the standardized space. A useful thing to understand your models is… you guessed it: posterior predictive checks! We’ll use PyMC’s dedicated function to sample data from the posterior. This function will randomly draw 4000 samples of parameters from the trace. Then, for each sample, it will draw 100 random numbers from a normal distribution specified by the values of mu and sigma in that sample:
with model_1:
pm.sample_posterior_predictive(idata, extend_inferencedata=True, random_seed=rng)
Sampling: [obs]
Now, the posterior_predictive group in idata contains 4000 generated data sets (containing 100 samples each), each using a different parameter setting from the posterior:
idata.posterior_predictive
<xarray.DatasetView> Size: 3MB
Dimensions: (chain: 4, draw: 1000, obs_dim_0: 100)
Coordinates:
* chain (chain) int64 32B 0 1 2 3
* draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999
* obs_dim_0 (obs_dim_0) int64 800B 0 1 2 3 4 5 6 7 ... 93 94 95 96 97 98 99
Data variables:
obs (chain, draw, obs_dim_0) float64 3MB -0.3941 -0.003109 ... 0.7515
Attributes:
created_at: 2026-03-07T07:32:47.425262+00:00
creation_library: ArviZ
creation_library_version: 1.0.0
creation_library_language: Python
inference_library: pymc
inference_library_version: 5.27.0+77.g364d1e162One common way to visualize is to look if the model can reproduce the patterns observed in the real data. ArviZ has a really neat function to do that out of the box:
az.plot_ppc_dist(idata);
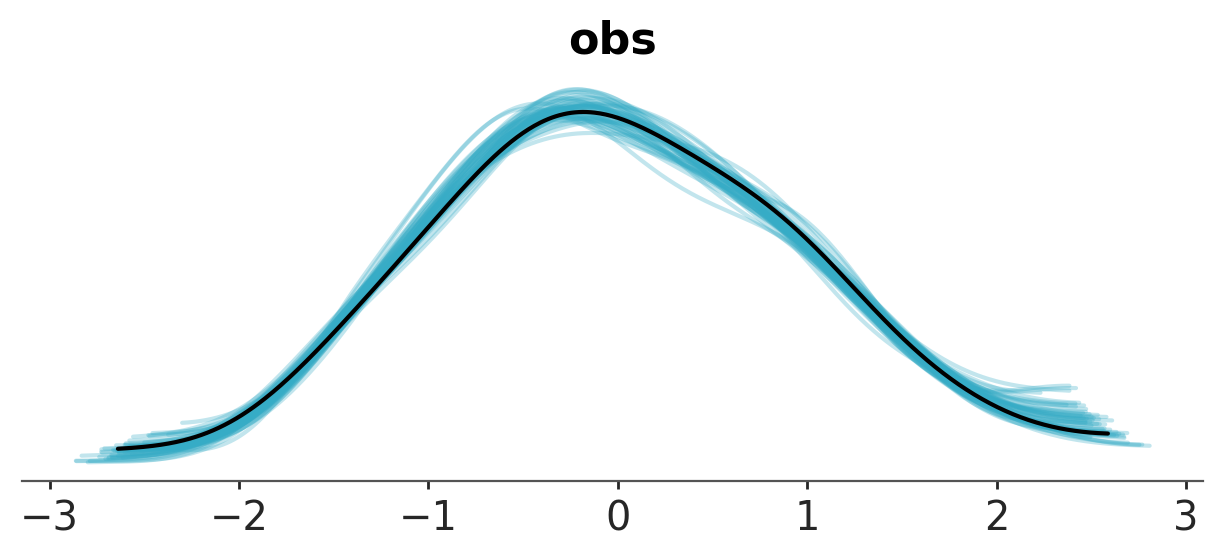
It looks like the model is pretty good at retrodicting the data. In addition to this generic function, it’s always nice to make a plot tailored to your use-case. Here, it would be interesting to plot the predicted relationship between the predictor and the outcome. This is quite easy, now that we already sampled posterior predictive samples – we just have to push the parameters through the model:
post = idata.posterior
mu_pp = post["a"] + post["b"] * xr.DataArray(predictor_scaled, dims=["obs_id"])
idata["constant_data"] = xr.Dataset({"predictor_scaled": (("obs_dim_0",), predictor_scaled)})
az.plot_lm(idata);
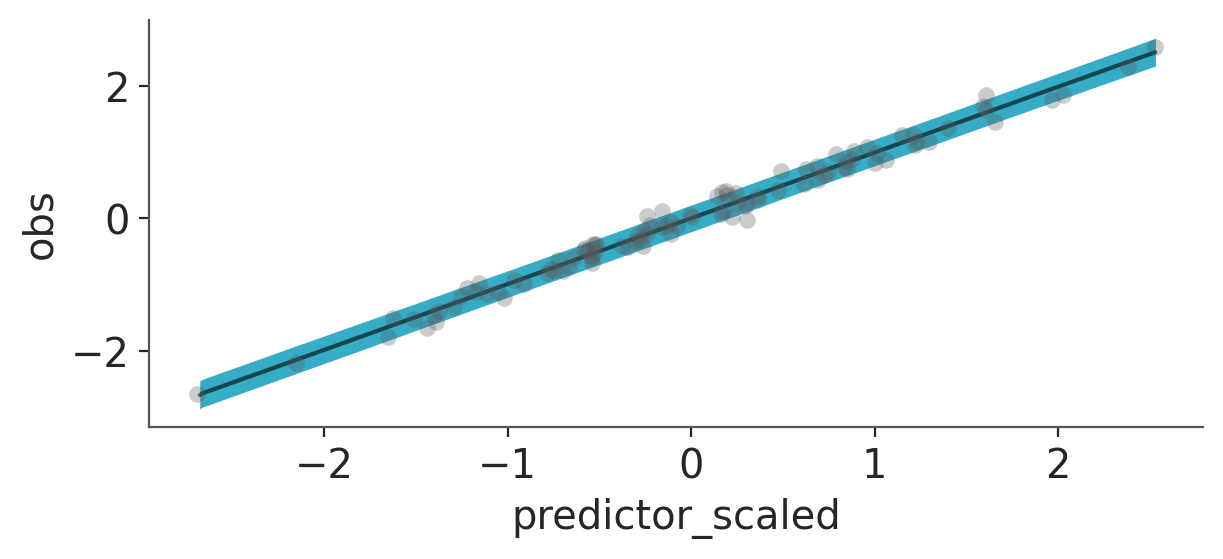
We have a lot of data, so the uncertainty around the mean of the outcome is pretty narrow; but the uncertainty surrounding the outcome in general seems quite in line with the observed data.
Comparison between PPC and other model evaluation methods.#
An excellent introduction to this was given in the Edward documentation:
PPCs are an excellent tool for revising models, simplifying or expanding the current model as one examines how well it fits the data. They are inspired by prior checks and classical hypothesis testing, under the philosophy that models should be criticized under the frequentist perspective of large sample assessment.
PPCs can also be applied to tasks such as hypothesis testing, model comparison, model selection, and model averaging. It’s important to note that while they can be applied as a form of Bayesian hypothesis testing, hypothesis testing is generally not recommended: binary decision making from a single test is not as common a use case as one might believe. We recommend performing many PPCs to get a holistic understanding of the model fit.
Prediction#
The same pattern can be used for prediction. Here, we are building a logistic regression model:
N = 400
true_intercept = 0.2
true_slope = 1.0
predictors = rng.normal(size=N)
true_p = logistic(true_intercept + true_slope * predictors)
outcomes = rng.binomial(1, true_p)
outcomes[:10]
array([0, 1, 1, 1, 1, 0, 1, 0, 0, 1])
with pm.Model() as model_2:
betas = pm.Normal("betas", mu=0.0, sigma=np.array([0.5, 1.0]), shape=2)
# set predictors as shared variable to change them for PPCs:
pred = pm.Data("pred", predictors, dims="obs_id")
p = pm.Deterministic("p", pm.math.invlogit(betas[0] + betas[1] * pred), dims="obs_id")
outcome = pm.Bernoulli("outcome", p=p, observed=outcomes, dims="obs_id")
idata_2 = pm.sample(1000, tune=2000, return_inferencedata=True, random_seed=rng)
az.summary(idata_2, var_names=["betas"], kind="stats", round_to=2)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [betas]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 2 seconds.
| mean | sd | eti89_lb | eti89_ub | |
|---|---|---|---|---|
| betas[0] | 0.22 | 0.11 | 0.06 | 0.40 |
| betas[1] | 1.02 | 0.14 | 0.81 | 1.24 |
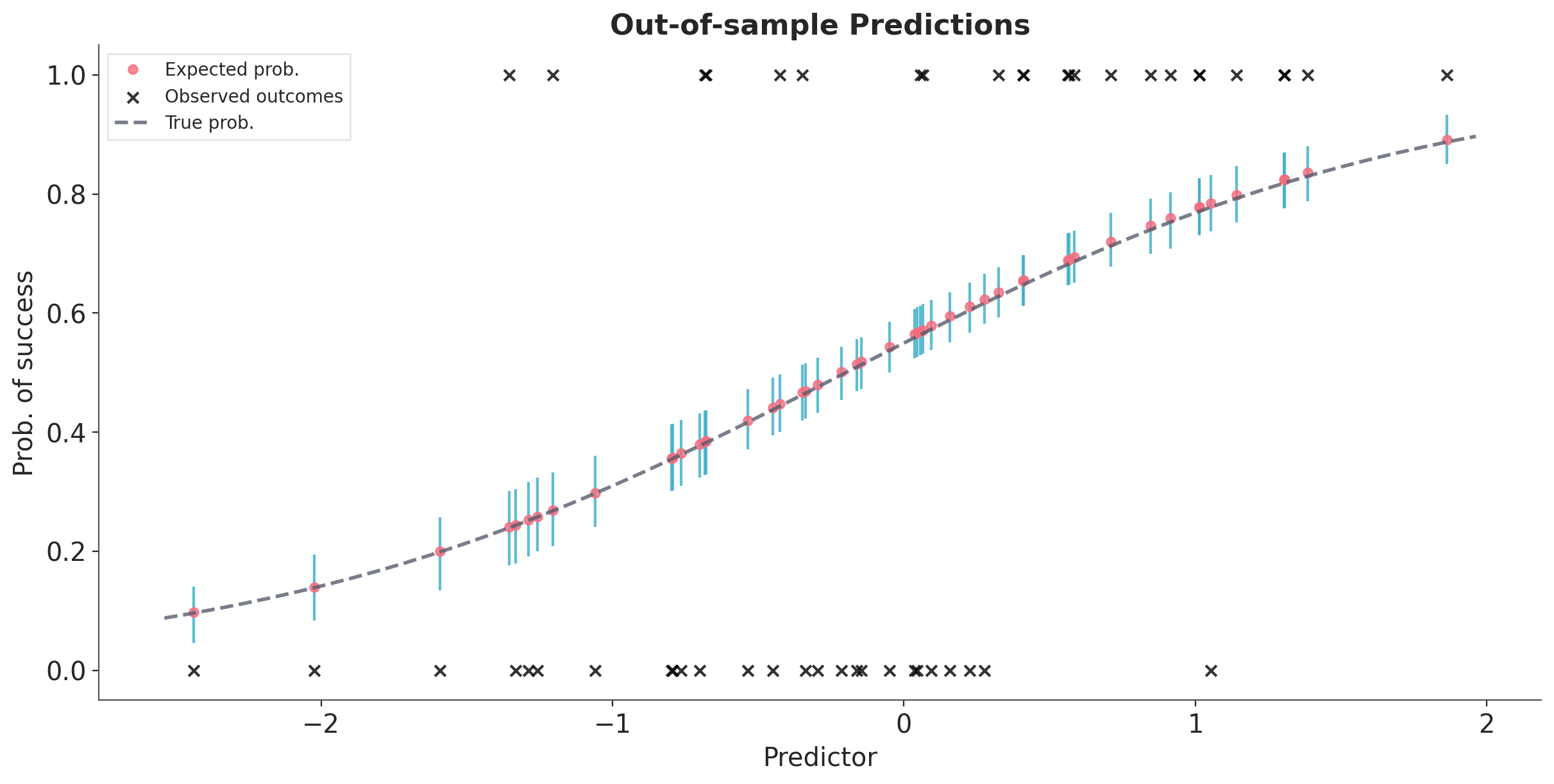
Now, let’s simulate out-of-sample data to see how the model predicts them. We’ll give the new predictors to the model and it’ll then tell us what it thinks the outcomes are, based on what it learned in the training round. We’ll then compare the model’s predictions to the true out-of-sample outcomes.
predictors_out_of_sample = rng.normal(size=50)
outcomes_out_of_sample = rng.binomial(
1, logistic(true_intercept + true_slope * predictors_out_of_sample)
)
with model_2:
# update values of predictors:
pm.set_data({"pred": predictors_out_of_sample})
# use the updated values and predict outcomes and probabilities:
idata_2 = pm.sample_posterior_predictive(
idata_2,
var_names=["p"],
return_inferencedata=True,
predictions=True,
extend_inferencedata=True,
random_seed=rng,
)
Sampling: []
idata_2
<xarray.DatasetView> Size: 0B
Dimensions: ()
Data variables:
*empty*Mean predicted values plus error bars to give a sense of uncertainty in prediction#
Note that since we are dealing with the full posterior, we are also getting uncertainty in our predictions for free.
idata_2.predictions["p"]
<xarray.DataArray 'p' (chain: 4, draw: 1000, obs_id: 50)> Size: 2MB
array([[[0.24499916, 0.36424952, 0.43215318, ..., 0.51940357,
0.62635204, 0.26048925],
[0.22165158, 0.3428441 , 0.41379221, ..., 0.50629837,
0.62073062, 0.23708964],
[0.36896078, 0.48803177, 0.54889627, ..., 0.62193432,
0.70582097, 0.38552976],
...,
[0.19230299, 0.349541 , 0.44657119, ..., 0.57142928,
0.71427354, 0.2112108 ],
[0.27863891, 0.40383437, 0.47277499, ..., 0.55910474,
0.66177939, 0.29521982],
[0.27336768, 0.40128562, 0.47209802, ..., 0.56083462,
0.66606483, 0.29022984]],
[[0.25111804, 0.3831781 , 0.45805521, ..., 0.55285507,
0.66558471, 0.26821789],
[0.24228487, 0.40149344, 0.49269228, ..., 0.60536781,
0.73105435, 0.26245043],
[0.24228487, 0.40149344, 0.49269228, ..., 0.60536781,
0.73105435, 0.26245043],
...
[0.26931383, 0.41014292, 0.48840139, ..., 0.5854494 ,
0.69746831, 0.28771417],
[0.20418355, 0.34659125, 0.43257286, ..., 0.54406354,
0.67644763, 0.22174232],
[0.18632534, 0.32660596, 0.41367411, ..., 0.52852031,
0.66678285, 0.20330462]],
[[0.25132902, 0.37829796, 0.45022312, ..., 0.54169218,
0.65166784, 0.2678202 ],
[0.19937516, 0.36582575, 0.46737901, ..., 0.59569945,
0.73811294, 0.21943144],
[0.24844763, 0.37234648, 0.44271416, ..., 0.53260243,
0.64154721, 0.26453542],
...,
[0.1714009 , 0.32436038, 0.42229378, ..., 0.55133063,
0.70184786, 0.18935032],
[0.25214225, 0.39400901, 0.47438864, ..., 0.57508344,
0.69204388, 0.27042836],
[0.23062933, 0.37545324, 0.45973984, ..., 0.5665809 ,
0.69108691, 0.24892688]]], shape=(4, 1000, 50))
Coordinates:
* chain (chain) int64 32B 0 1 2 3
* draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999
* obs_id (obs_id) int64 400B 0 1 2 3 4 5 6 7 8 ... 42 43 44 45 46 47 48 49_, ax = plt.subplots(figsize=(12, 6))
# Get sorted indices based on predictor values
sort_idx = np.argsort(predictors_out_of_sample)
preds_out_of_sample = predictors_out_of_sample[sort_idx]
model_preds = idata_2.predictions["p"].isel(obs_id=sort_idx)
# uncertainty about the estimates:
ax.vlines(
preds_out_of_sample,
*az.hdi(model_preds).transpose("ci_bound", ...),
alpha=0.8,
)
# expected probability of success:
ax.plot(
preds_out_of_sample,
model_preds.mean(("chain", "draw")),
"o",
ms=5,
color="C1",
alpha=0.8,
label="Expected prob.",
)
# actual outcomes:
ax.scatter(
x=predictors_out_of_sample,
y=outcomes_out_of_sample,
marker="x",
color="k",
alpha=0.8,
label="Observed outcomes",
)
# true probabilities:
x = np.linspace(predictors_out_of_sample.min() - 0.1, predictors_out_of_sample.max() + 0.1)
ax.plot(
x,
logistic(true_intercept + true_slope * x),
lw=2,
ls="--",
color="#565C6C",
alpha=0.8,
label="True prob.",
)
ax.set_xlabel("Predictor")
ax.set_ylabel("Prob. of success")
ax.set_title("Out-of-sample Predictions")
ax.legend(fontsize=10, frameon=True, framealpha=0.5);
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor
Last updated: Sat Mar 07 2026
Python implementation: CPython
Python version : 3.13.5
IPython version : 9.3.0
pytensor: 2.38.1
xarray : 2025.6.1
numpy : 2.2.6
matplotlib: 3.10.3
pymc : 5.27.0+77.g364d1e162
arviz : 1.0.0
Watermark: 2.5.0