
Modeling Heteroscedasticity with BART#
In this notebook we show how to use BART to model heteroscedasticity as described in Section 4.1 of pymc-bart’s paper []. We use the marketing data set provided by the R package datarium []. The idea is to model a marketing channel contribution to sales as a function of budget.
import os
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
import pymc_bart as pmb
%config InlineBackend.figure_format = "retina"
az.style.use("arviz-variat")
plt.rcParams["figure.figsize"] = [10, 6]
rng = np.random.default_rng(42)
Read Data#
try:
df = pd.read_csv(os.path.join("..", "data", "marketing.csv"), sep=";", decimal=",")
except FileNotFoundError:
df = pd.read_csv(pm.get_data("marketing.csv"), sep=";", decimal=",")
n_obs = df.shape[0]
df.head()
| youtube | newspaper | sales | ||
|---|---|---|---|---|
| 0 | 276.12 | 45.36 | 83.04 | 26.52 |
| 1 | 53.40 | 47.16 | 54.12 | 12.48 |
| 2 | 20.64 | 55.08 | 83.16 | 11.16 |
| 3 | 181.80 | 49.56 | 70.20 | 22.20 |
| 4 | 216.96 | 12.96 | 70.08 | 15.48 |
EDA#
We start by looking into the data. We are going to focus on Youtube.
fig, ax = plt.subplots()
ax.plot(df["youtube"], df["sales"], "o", c="C0")
ax.set(title="Sales as a function of Youtube budget", xlabel="budget", ylabel="sales");
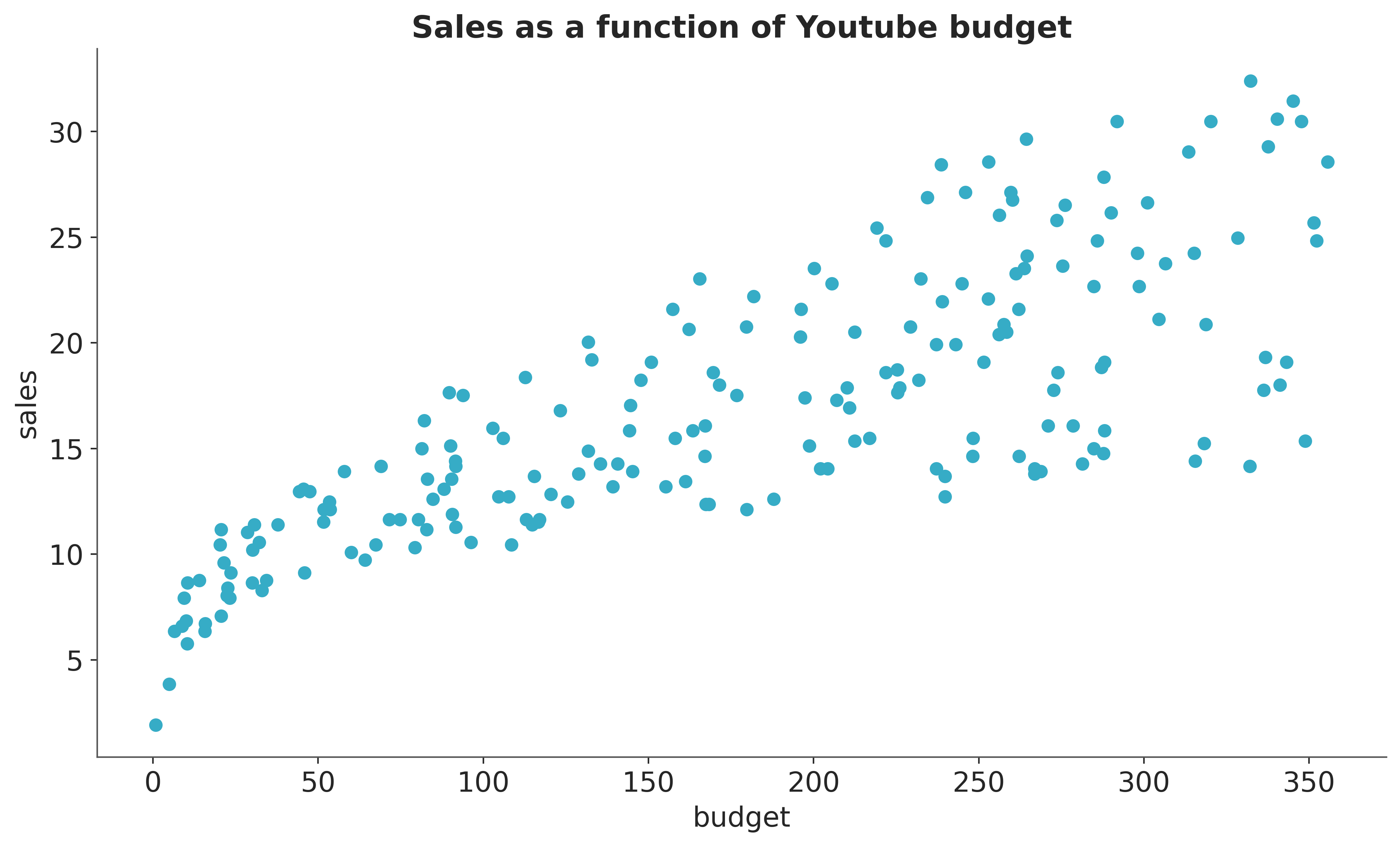
We clearly see that both the mean and variance are increasing as a function of budget. One possibility is to manually select an explicit parametrization of these functions, e.g. square root or logarithm. However, in this example we want to learn these functions from the data using a BART model.
Model Specification#
We proceed to prepare the data for modeling. We are going to use the budget as the predictor and sales as the response.
X = df["youtube"].to_numpy().reshape(-1, 1)
Y = df["sales"].to_numpy()
Next, we specify the model. Note that we just need one BART distribution which can be vectorized to model both the mean and variance. We use a Gamma distribution as likelihood as we expect the sales to be positive.

We now fit the model.
with model_marketing_full:
idata_marketing_full = pm.sample(2000, random_seed=rng, compute_convergence_checks=False)
posterior_predictive_marketing_full = pm.sample_posterior_predictive(
trace=idata_marketing_full, random_seed=rng
)
Multiprocess sampling (4 chains in 4 jobs)
PGBART: [w]
Sampling 4 chains for 1_000 tune and 2_000 draw iterations (4_000 + 8_000 draws total) took 150 seconds.
Sampling: [y]
Results#
We can now visualize the posterior predictive distribution of the mean and the likelihood.
posterior_predictive_marketing_full
<xarray.DataTree>
Group: /
├── Group: /posterior_predictive
│ Dimensions: (chain: 4, draw: 2000, y_dim_0: 200)
│ Coordinates:
│ * chain (chain) int64 32B 0 1 2 3
│ * draw (draw) int64 16kB 0 1 2 3 4 5 6 ... 1994 1995 1996 1997 1998 1999
│ * y_dim_0 (y_dim_0) int64 2kB 0 1 2 3 4 5 6 7 ... 193 194 195 196 197 198 199
│ Data variables:
│ y (chain, draw, y_dim_0) float64 13MB 28.37 10.13 ... 25.83 13.69
│ Attributes:
│ created_at: 2026-04-25T08:24:51.846027+00:00
│ creation_library: ArviZ
│ creation_library_version: 1.1.1dev0
│ creation_library_language: Python
│ inference_library: pymc
│ inference_library_version: 5.28.0+58.gf58491a3
│ sample_dims: ['chain', 'draw']
└── Group: /observed_data
Dimensions: (y_dim_0: 200)
Coordinates:
* y_dim_0 (y_dim_0) int64 2kB 0 1 2 3 4 5 6 7 ... 193 194 195 196 197 198 199
Data variables:
y (y_dim_0) float64 2kB 26.52 12.48 11.16 22.2 ... 15.36 30.6 16.08
Attributes:
created_at: 2026-04-25T08:24:51.847700+00:00
creation_library: ArviZ
creation_library_version: 1.1.1dev0
creation_library_language: Python
inference_library: pymc
inference_library_version: 5.28.0+58.gf58491a3
sample_dims: []dt_plot = az.from_dict(
{
"posterior_predictive": {
"y": posterior_predictive_marketing_full.posterior_predictive["y"]
},
"observed_data": {"y": df["sales"].values},
"constant_data": {"budget": X[:, 0]},
},
dims={
"y": ["budget_dim"],
"budget": ["budget_dim"],
},
)
az.plot_lm(dt_plot, x="budget", y="y");
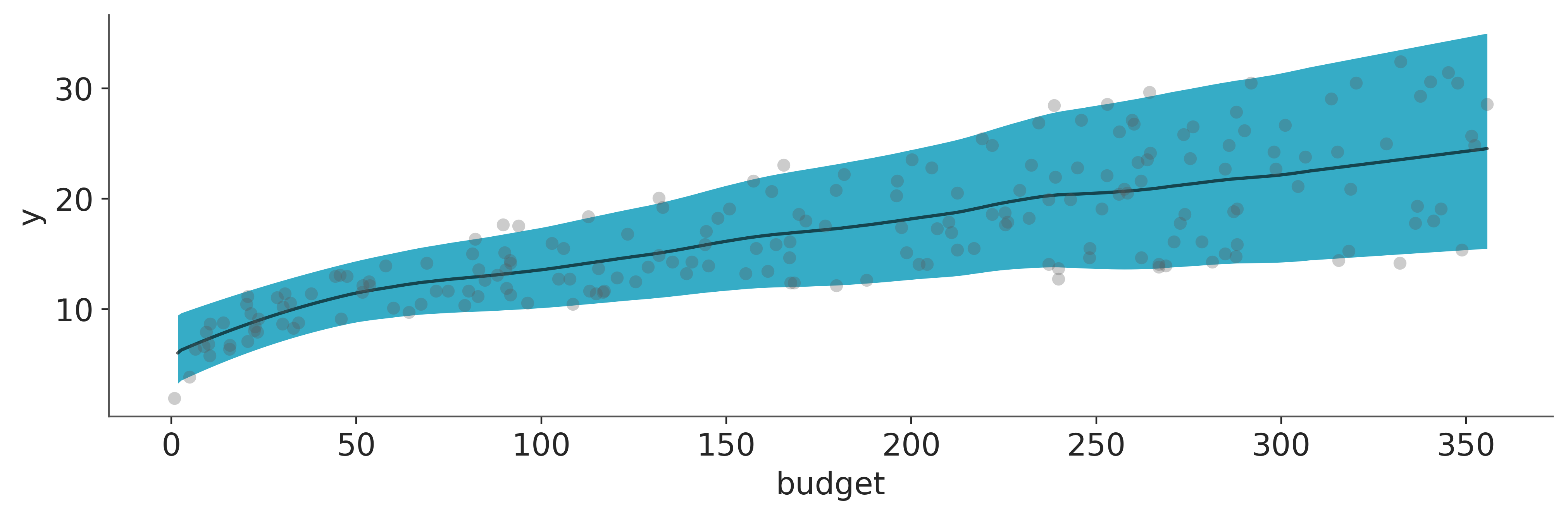
The fit looks good! In fact, we see that the mean and variance increase as a function of the budget.
References#
Watermark#
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor
Last updated: Sat, 25 Apr 2026
Python implementation: CPython
Python version : 3.14.4
IPython version : 9.12.0
pytensor: 2.38.0+133.g80cc113b5
arviz : 1.1.0
matplotlib: 3.10.8
numpy : 2.4.4
pandas : 3.0.2
pymc : 5.28.0+58.gf58491a3
pymc_bart : 0.11.0
Watermark: 2.6.0