Bayesian Parametric Survival Analysis with PyMC3#
import warnings
import arviz as az
import numpy as np
import pymc3 as pm
import scipy as sp
import seaborn as sns
from matplotlib import pyplot as plt
from matplotlib.ticker import StrMethodFormatter
from statsmodels import datasets
from theano import shared
from theano import tensor as tt
print(f"Running on PyMC3 v{pm.__version__}")
Running on PyMC3 v3.10.0
warnings.filterwarnings("ignore")
%config InlineBackend.figure_format = 'retina'
az.style.use("arviz-darkgrid")
Survival analysis studies the distribution of the time between when a subject comes under observation and when that subject experiences an event of interest. One of the fundamental challenges of survival analysis (which also makes is mathematically interesting) is that, in general, not every subject will experience the event of interest before we conduct our analysis. In more concrete terms, if we are studying the time between cancer treatment and death (as we will in this post), we will often want to analyze our data before every subject has died. This phenomenon is called censoring and is fundamental to survival analysis.
I have previously written about Bayesian survival analysis using the semiparametric Cox proportional hazards model. Implementing that semiparametric model in PyMC3 involved some fairly complex numpy code and nonobvious probability theory equivalences. This post illustrates a parametric approach to Bayesian survival analysis in PyMC3. Parametric models of survival are simpler to both implement and understand than semiparametric models; statistically, they are also more powerful than non- or semiparametric methods when they are correctly specified. This post will not further cover the differences between parametric and nonparametric models or the various methods for choosing between them.
As in the previous post, we will analyze mastectomy data from R’s HSAUR package. First, we load the data.
sns.set()
blue, green, red, purple, gold, teal = sns.color_palette(n_colors=6)
pct_formatter = StrMethodFormatter("{x:.1%}")
df = datasets.get_rdataset("mastectomy", "HSAUR", cache=True).data.assign(
metastized=lambda df: 1.0 * (df.metastized == "yes"), event=lambda df: 1.0 * df.event
)
df.head()
| time | event | metastized | |
|---|---|---|---|
| 0 | 23 | 1.0 | 0.0 |
| 1 | 47 | 1.0 | 0.0 |
| 2 | 69 | 1.0 | 0.0 |
| 3 | 70 | 0.0 | 0.0 |
| 4 | 100 | 0.0 | 0.0 |
The column time represents the survival time for a breast cancer patient after a mastectomy, measured in months. The column event indicates whether or not the observation is censored. If event is one, the patient’s death was observed during the study; if event is zero, the patient lived past the end of the study and their survival time is censored. The column metastized indicates whether the cancer had metastized prior to the mastectomy. In this post, we will use Bayesian parametric survival regression to quantify the difference in survival times for patients whose cancer had and had not metastized.
Accelerated failure time models#
Accelerated failure time models are the most common type of parametric survival regression models. The fundamental quantity of survival analysis is the survival function; if \(T\) is the random variable representing the time to the event in question, the survival function is \(S(t) = P(T > t)\). Accelerated failure time models incorporate covariates \(\mathbf{x}\) into the survival function as
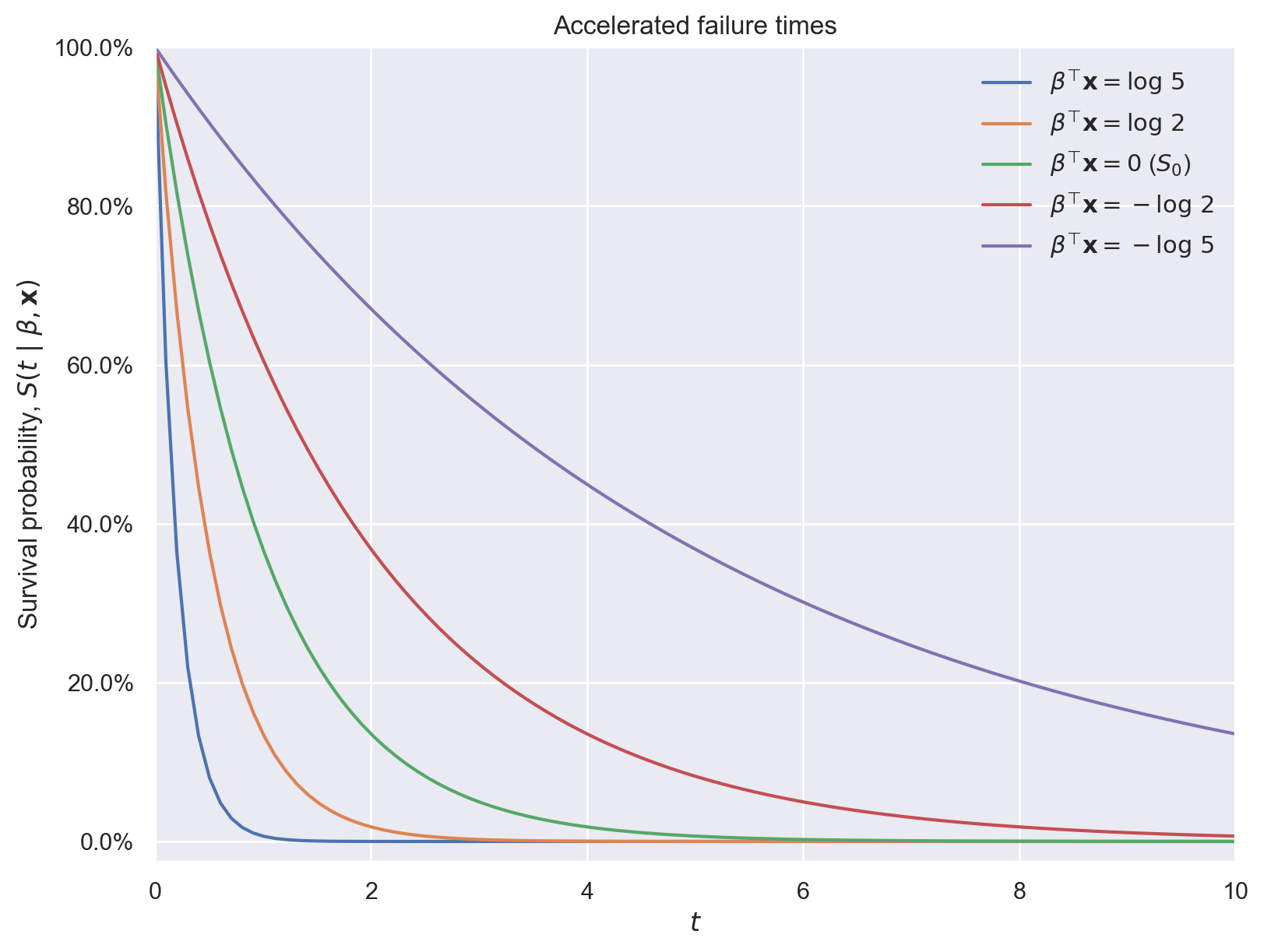
where \(S_0(t)\) is a fixed baseline survival function. These models are called “accelerated failure time” because, when \(\beta^{\top} \mathbf{x} > 0\), \(\exp\left(\beta^{\top} \mathbf{x}\right) \cdot t > t\), so the effect of the covariates is to accelerate the effective passage of time for the individual in question. The following plot illustrates this phenomenon using an exponential survival function.
S0 = sp.stats.expon.sf
fig, ax = plt.subplots(figsize=(8, 6))
t = np.linspace(0, 10, 100)
ax.plot(t, S0(5 * t), label=r"$\beta^{\top} \mathbf{x} = \log\ 5$")
ax.plot(t, S0(2 * t), label=r"$\beta^{\top} \mathbf{x} = \log\ 2$")
ax.plot(t, S0(t), label=r"$\beta^{\top} \mathbf{x} = 0$ ($S_0$)")
ax.plot(t, S0(0.5 * t), label=r"$\beta^{\top} \mathbf{x} = -\log\ 2$")
ax.plot(t, S0(0.2 * t), label=r"$\beta^{\top} \mathbf{x} = -\log\ 5$")
ax.set_xlim(0, 10)
ax.set_xlabel(r"$t$")
ax.yaxis.set_major_formatter(pct_formatter)
ax.set_ylim(-0.025, 1)
ax.set_ylabel(r"Survival probability, $S(t\ |\ \beta, \mathbf{x})$")
ax.legend(loc=1)
ax.set_title("Accelerated failure times");
Accelerated failure time models are equivalent to log-linear models for \(T\),
A choice of distribution for the error term \(\varepsilon\) determines baseline survival function, \(S_0\), of the accelerated failure time model. The following table shows the correspondence between the distribution of \(\varepsilon\) and \(S_0\) for several common accelerated failure time models.
| Log-linear error distribution ($\varepsilon$) | Baseline survival function ($S_0$) |
|---|---|
| [Normal](https://en.wikipedia.org/wiki/Normal_distribution) | [Log-normal](https://en.wikipedia.org/wiki/Log-normal_distribution) |
| Extreme value ([Gumbel](https://en.wikipedia.org/wiki/Gumbel_distribution)) | [Weibull](https://en.wikipedia.org/wiki/Weibull_distribution) |
| [Logistic](https://en.wikipedia.org/wiki/Logistic_distribution) | [Log-logistic](https://en.wikipedia.org/wiki/Log-logistic_distribution) |
Accelerated failure time models are conventionally named after their baseline survival function, \(S_0\). The rest of this post will show how to implement Weibull and log-logistic survival regression models in PyMC3 using the mastectomy data.
Weibull survival regression#
In this example, the covariates are \(\mathbf{x}_i = \left(1\ x^{\textrm{met}}_i\right)^{\top}\), where
We construct the matrix of covariates \(\mathbf{X}\).
n_patient, _ = df.shape
X = np.empty((n_patient, 2))
X[:, 0] = 1.0
X[:, 1] = df.metastized
We place independent, vague normal prior distributions on the regression coefficients,
VAGUE_PRIOR_SD = 5.0
with pm.Model() as weibull_model:
β = pm.Normal("β", 0.0, VAGUE_PRIOR_SD, shape=2)
The covariates, \(\mathbf{x}\), affect value of \(Y = \log T\) through \(\eta = \beta^{\top} \mathbf{x}\).
X_ = shared(X)
with weibull_model:
η = β.dot(X_.T)
For Weibull regression, we use
with weibull_model:
s = pm.HalfNormal("s", 5.0)
We are nearly ready to specify the likelihood of the observations given these priors. Before doing so, we transform the observed times to the log scale and standardize them.
y = np.log(df.time.values)
y_std = (y - y.mean()) / y.std()
The likelihood of the data is specified in two parts, one for uncensored samples, and one for censored samples. Since \(Y = \eta + \varepsilon\), and \(\varepsilon \sim \textrm{Gumbel}(0, s)\), \(Y \sim \textrm{Gumbel}(\eta, s)\). For the uncensored survival times, the likelihood is implemented as
cens = df.event.values == 0.0
cens_ = shared(cens)
with weibull_model:
y_obs = pm.Gumbel("y_obs", η[~cens_], s, observed=y_std[~cens])
For censored observations, we only know that their true survival time exceeded the total time that they were under observation. This probability is given by the survival function of the Gumbel distribution,
This survival function is implemented below.
def gumbel_sf(y, μ, σ):
return 1.0 - tt.exp(-tt.exp(-(y - μ) / σ))
We now specify the likelihood for the censored observations.
with weibull_model:
y_cens = pm.Potential("y_cens", gumbel_sf(y_std[cens], η[cens_], s))
We now sample from the model.
SEED = 845199 # from random.org, for reproducibility
SAMPLE_KWARGS = {"chains": 3, "tune": 1000, "random_seed": [SEED, SEED + 1, SEED + 2]}
with weibull_model:
weibull_trace = pm.sample(**SAMPLE_KWARGS)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (3 chains in 2 jobs)
NUTS: [s, β]
Sampling 3 chains for 1_000 tune and 1_000 draw iterations (3_000 + 3_000 draws total) took 39 seconds.
The acceptance probability does not match the target. It is 0.6922724047840629, but should be close to 0.8. Try to increase the number of tuning steps.
The number of effective samples is smaller than 25% for some parameters.
The energy plot and Bayesian fraction of missing information give no cause for concern about poor mixing in NUTS.
az.plot_energy(weibull_trace);
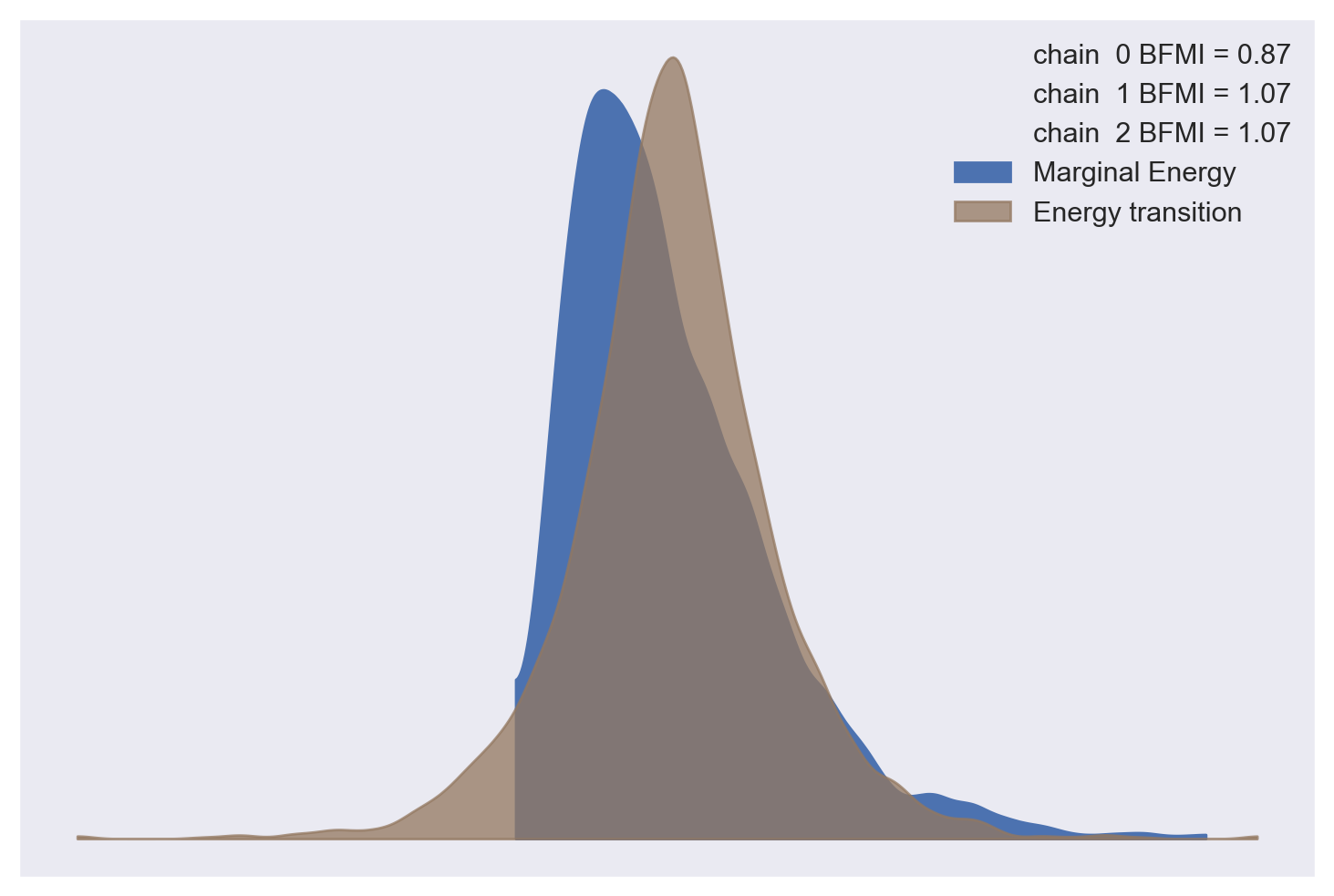
az.bfmi(weibull_trace)
array([0.87373535, 1.07058324, 1.06915059])
The Gelman-Rubin statistics also indicate convergence.
<xarray.DataArray 'β' ()> array(1.00602146)
- 1.006
array(1.00602146)
Below we plot posterior distributions of the parameters.
az.plot_posterior(weibull_trace, lw=0, alpha=0.5);
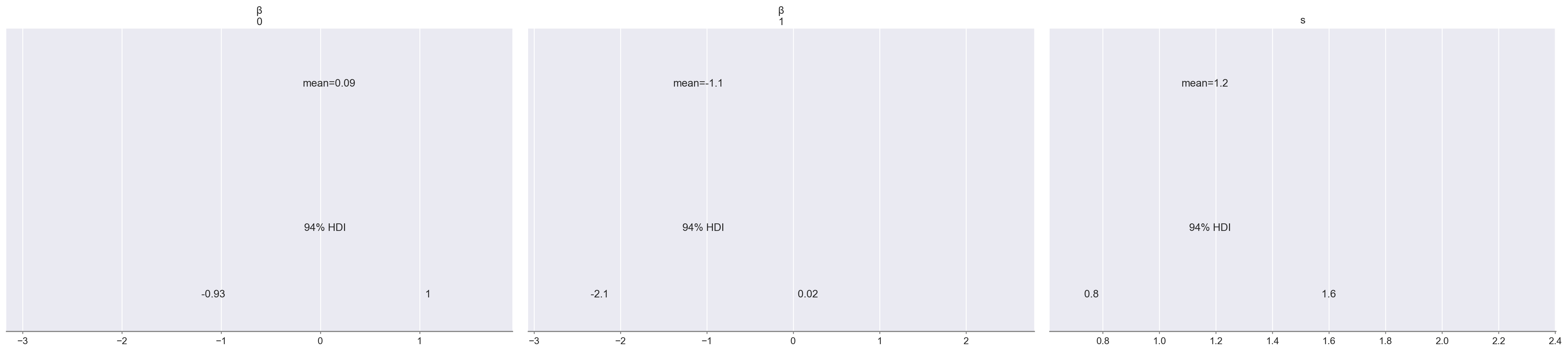
These are somewhat interesting (espescially the fact that the posterior of \(\beta_1\) is fairly well-separated from zero), but the posterior predictive survival curves will be much more interpretable.
The advantage of using theano.shared variables is that we can now change their values to perform posterior predictive sampling. For posterior prediction, we set \(X\) to have two rows, one for a subject whose cancer had not metastized and one for a subject whose cancer had metastized. Since we want to predict actual survival times, none of the posterior predictive rows are censored.
with weibull_model:
pp_weibull_trace = pm.sample_posterior_predictive(weibull_trace, samples=1500)
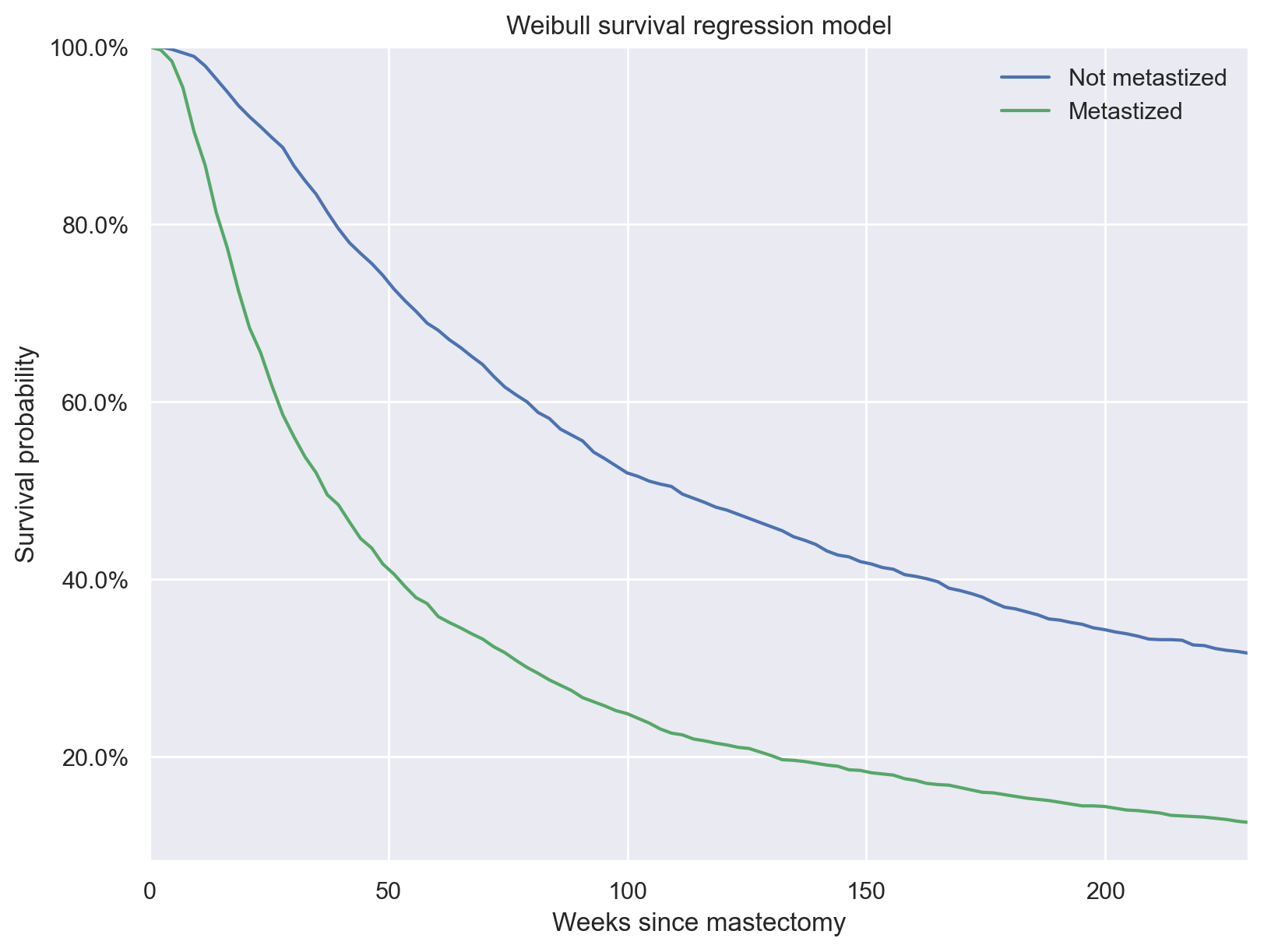
The posterior predictive survival times show that, on average, patients whose cancer had not metastized survived longer than those whose cancer had metastized.
t_plot = np.linspace(0, 230, 100)
weibull_pp_surv = np.greater_equal.outer(
np.exp(y.mean() + y.std() * pp_weibull_trace["y_obs"]), t_plot
)
weibull_pp_surv_mean = weibull_pp_surv.mean(axis=0)
fig, ax = plt.subplots(figsize=(8, 6))
ax.plot(t_plot, weibull_pp_surv_mean[0], c=blue, label="Not metastized")
ax.plot(t_plot, weibull_pp_surv_mean[1], c=red, label="Metastized")
ax.set_xlim(0, 230)
ax.set_xlabel("Weeks since mastectomy")
ax.set_ylim(top=1)
ax.yaxis.set_major_formatter(pct_formatter)
ax.set_ylabel("Survival probability")
ax.legend(loc=1)
ax.set_title("Weibull survival regression model");
Log-logistic survival regression#
Other accelerated failure time models can be specified in a modular way by changing the prior distribution on \(\varepsilon\). A log-logistic model corresponds to a logistic prior on \(\varepsilon\). Most of the model specification is the same as for the Weibull model above.
X_.set_value(X)
cens_.set_value(cens)
with pm.Model() as log_logistic_model:
β = pm.Normal("β", 0.0, VAGUE_PRIOR_SD, shape=2)
η = β.dot(X_.T)
s = pm.HalfNormal("s", 5.0)
We use the prior \(\varepsilon \sim \textrm{Logistic}(0, s)\). The survival function of the logistic distribution is
so we get the likelihood
def logistic_sf(y, μ, s):
return 1.0 - pm.math.sigmoid((y - μ) / s)
with log_logistic_model:
y_obs = pm.Logistic("y_obs", η[~cens_], s, observed=y_std[~cens])
y_cens = pm.Potential("y_cens", logistic_sf(y_std[cens], η[cens_], s))
We now sample from the log-logistic model.
with log_logistic_model:
log_logistic_trace = pm.sample(**SAMPLE_KWARGS)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (3 chains in 2 jobs)
NUTS: [s, β]
Sampling 3 chains for 1_000 tune and 1_000 draw iterations (3_000 + 3_000 draws total) took 19 seconds.
All of the sampling diagnostics look good for this model.
az.plot_energy(log_logistic_trace);
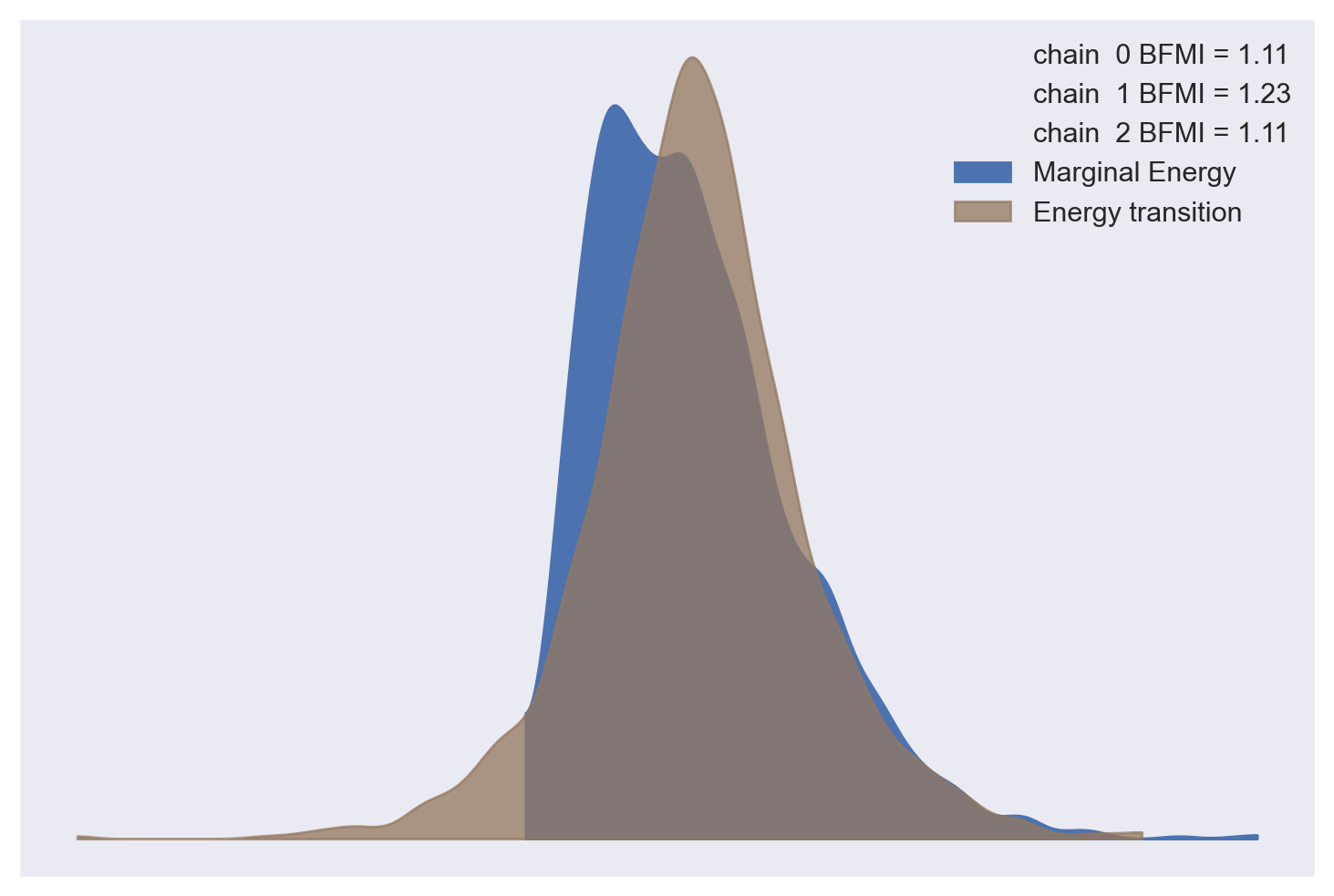
az.bfmi(log_logistic_trace)
array([1.11499706, 1.22571612, 1.10888002])
<xarray.DataArray 'β' ()> array(1.00581312)
- 1.006
array(1.00581312)
Again, we calculate the posterior expected survival functions for this model.
X_.set_value(X_pp)
cens_.set_value(cens_pp)
with log_logistic_model:
pp_log_logistic_trace = pm.sample_posterior_predictive(log_logistic_trace, samples=1500)
log_logistic_pp_surv = np.greater_equal.outer(
np.exp(y.mean() + y.std() * pp_log_logistic_trace["y_obs"]), t_plot
)
log_logistic_pp_surv_mean = log_logistic_pp_surv.mean(axis=0)
fig, ax = plt.subplots(figsize=(8, 6))
ax.plot(t_plot, weibull_pp_surv_mean[0], c=blue, label="Weibull, not metastized")
ax.plot(t_plot, weibull_pp_surv_mean[1], c=red, label="Weibull, metastized")
ax.plot(t_plot, log_logistic_pp_surv_mean[0], "--", c=blue, label="Log-logistic, not metastized")
ax.plot(t_plot, log_logistic_pp_surv_mean[1], "--", c=red, label="Log-logistic, metastized")
ax.set_xlim(0, 230)
ax.set_xlabel("Weeks since mastectomy")
ax.set_ylim(top=1)
ax.yaxis.set_major_formatter(pct_formatter)
ax.set_ylabel("Survival probability")
ax.legend(loc=1)
ax.set_title("Weibull and log-logistic\nsurvival regression models");
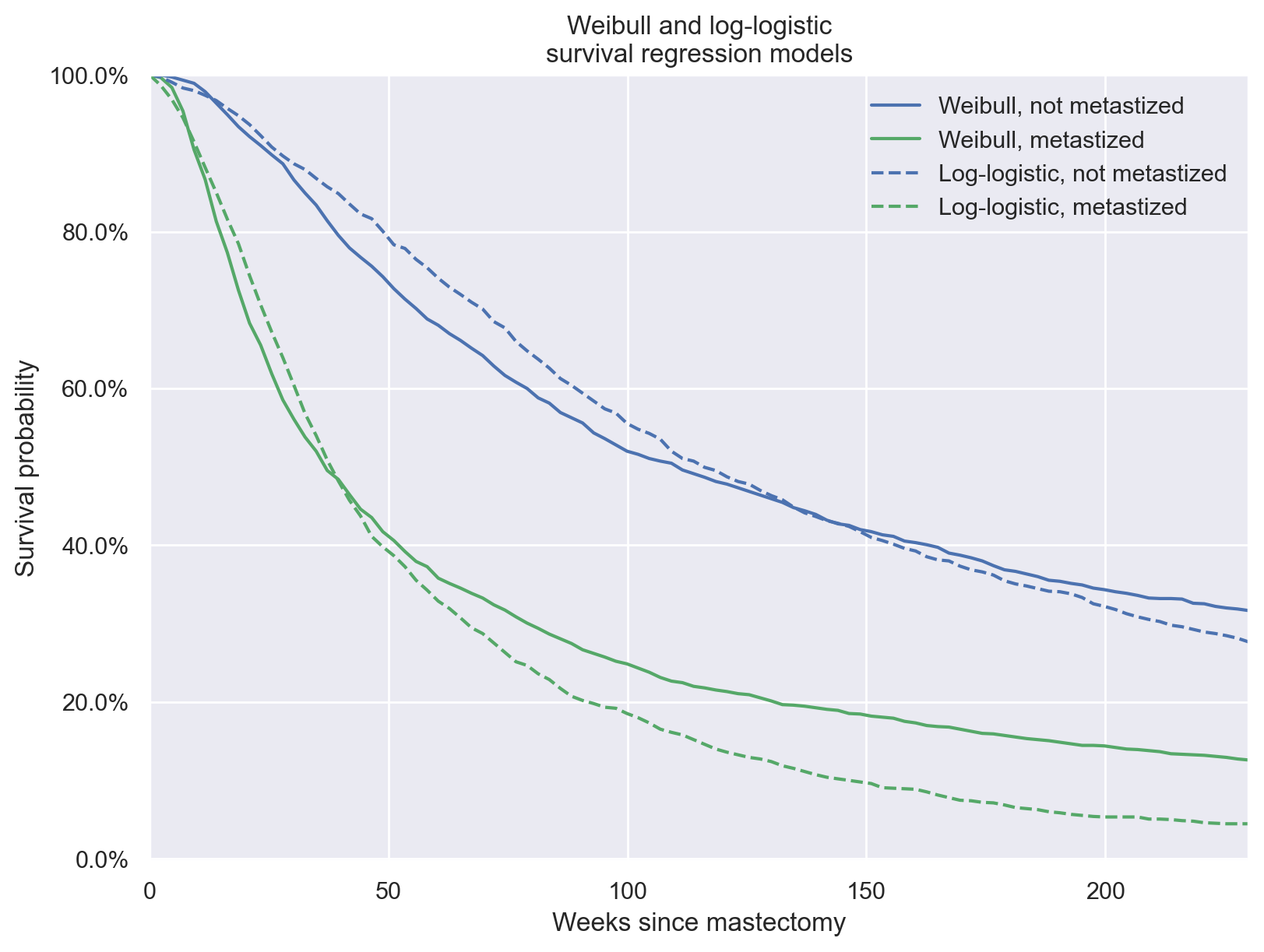
This post has been a short introduction to implementing parametric survival regression models in PyMC3 with a fairly simple data set. The modular nature of probabilistic programming with PyMC3 should make it straightforward to generalize these techniques to more complex and interesting data set.